
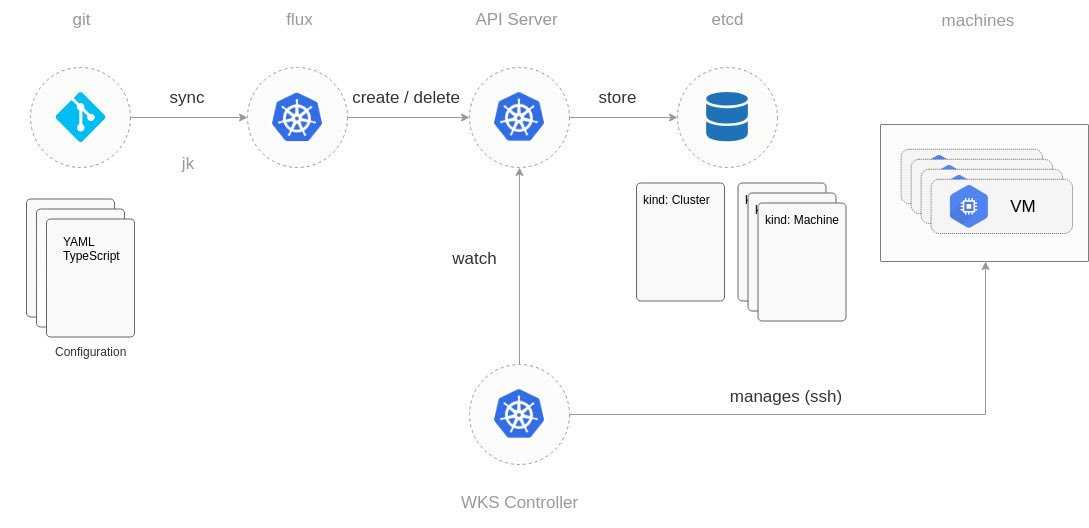
Введение
Поздравляем! Вам удалось убедить ваше начальство в миграции приложений на микросервисную архитектуру с использованием контейнеров и Kubernetes.
Вы очень довольны и все идет по плану. Вы создаете свой первый кластер Kubernetes (у всех основных облачных провайдеров: Azure, AWS и GCP, — есть простые решения для провиженинга управляемого или неуправляемого Kubernetes), разрабатываете первое контейнерное приложение и развертываете его в кластере. Это было легко, не так ли?
Через некоторое время вы понимаете, что все становится немного сложнее: вам нужно развернуть в кластере несколько приложений, поэтому вам нужен Ingress Controller. Далее вы хотите мониторить нагрузку, поэтому вы начинаете искать решения для этого и, к счастью, находите Prometheus. Разворачиваете его, добавляете Grafana и все!
Позже вы начинаете задаваться вопросом: «Почему Prometheus работает только с одной репликой»? Что произойдет в случае рестарта контейнера? Что будет при простом обновлении версии? Как долго Prometheus может хранить метрики? Что если кластер развалится? Нужен ли еще один кластер для HA и DR? Как мне получить единое представление метрик со всех серверов Prometheus?
Что ж, продолжайте читать, умные люди уже разобрались с этими вопросами.
А в чем была собственно проблема?
- медленные запуски утилит каждый раз, на каждый нужный элемент данных
- обращение к ресурсу (диск, порт, счетчик, API приложения) на каждый элемент данных
- парсинг результата нужно было делать внешними скриптами/утилитами
- а если потом нужно было поправить парсинг – приходилось опять обновлять UserParameters или скрипты
- кроме всего прочего, одновременные запросы от нескольких Zabbix pollers приводили к ошибке при обращении, например, к последовательному порту.
зависимых элементов данных
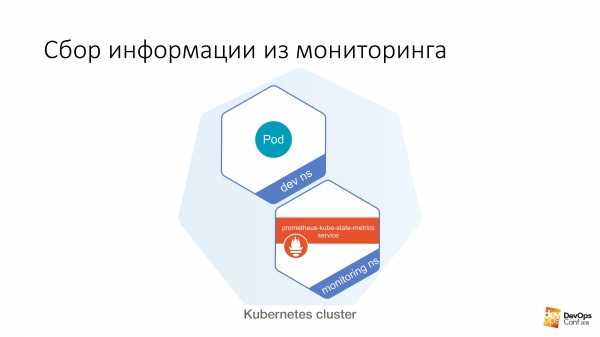
- В Zabbix 3.4 источником данных может выступать другой элемент данных, который называется родительским или мастер-элементом. Такой элемент может, например, содержать массив данных в формате JSON, XML или произвольном текстовом формате.
- В момент поступления новых данных в родительский элемент, остальные элементы данных, которые называются зависимыми, обращаются к родительскому элементу и при помощи таких как JSON path, XPath или Regex выделяют из текста нужную метрику.
шаблон для сервера
Деплой Thanos
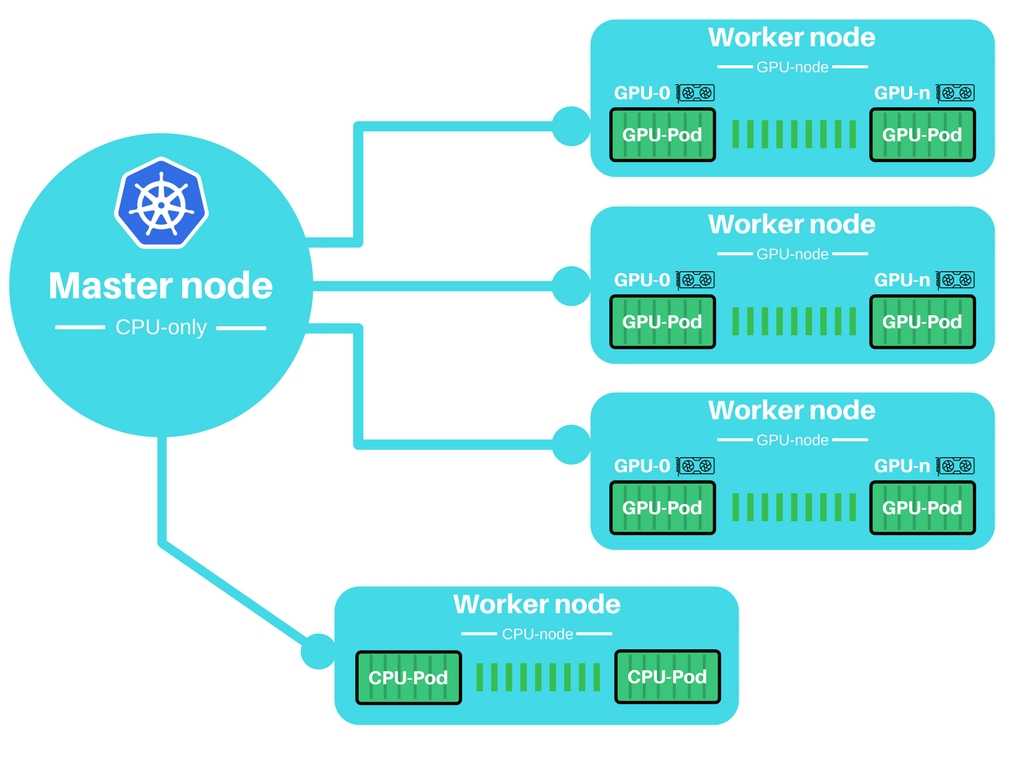
Мы начнем с развертывания Thanos Sidecar в тех же кластерах Kubernetes, которые мы используем для пользовательских приложений, Prometheus и Grafana.
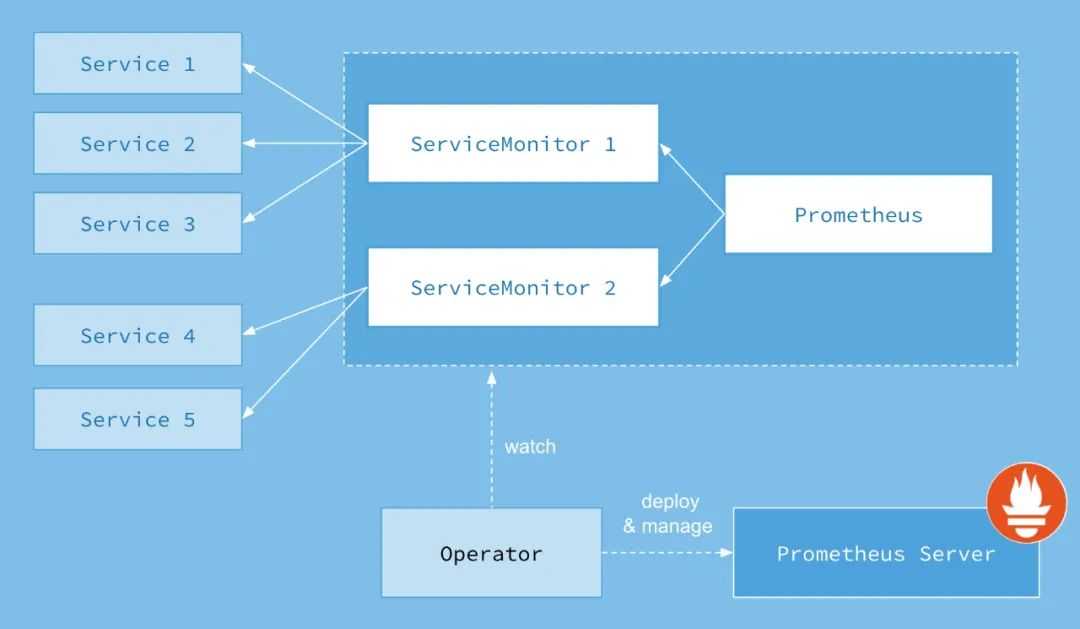
Есть много способов установки Prometheus, но я предпочитаю использовать Prometheus-Operator, который предоставляет настройки для мониторинга сервисов и развертываний Kubernetes, а также для управления экземплярами Prometheus.
Самый простой способ установки Prometheus-Operator — это использовать его Helm чарт, у которого есть встроенная поддержка высокой доступности, Thanos Sidecar и множество преднастроенных алертов для мониторинга кластерных виртуальных машин, инфраструктуры Kubernetes и ваших приложений.
Перед развертыванием Thanos Sidecar нам нужен Kubernetes Secret с информацией о том, как подключиться к облачному хранилищу.
Для демонстрации я буду использовать Microsoft Azure.
Создайте account для blob-хранилища:
Затем создайте папку (она же container) для метрик:
Получите ключи от хранилища:
Создайте файл с настройками хранилища (thanos-storage-config.yaml):
Создайте Kubernetes Secret:
Создайте файл prometheus-operator-values.yaml, в котором переопределите настройки по умолчанию для Prometheus-Operator.
И деплой:
Теперь у вас должен быть высокодоступный Prometheus вместе с Thanos Sidecar, который загружает ваши метрики в Azure Blob Storage с неограниченным сроком хранения.
Для того чтобы Thanos Store Gateway предоставить доступ к Thanos Sidecar, нужно выставить его наружу через Ingress. Я использую Nginx Ingress Controller, но вы можете использовать любой другой Ingress Controller, который поддерживает gRPC (возможно, Envoy будет лучшим вариантом).
Для защищенного соединения между Thanos Store Gateway и Thanos Sidecar мы будем использовать mutual TLS. То есть клиент будет аутентифицировать сервер и наоборот.
Если у вас есть .pfx-файл, то вы можете извлечь из него закрытый, открытый ключ и сертификат с помощью openssl:
Создайте из этого два Kubernetes Secrets.
Убедитесь, что у вас есть домен, который резолвится в ваш кластер Kubernetes, и создайте два поддомена, которые будут использоваться для маршрутизации к каждому из Thaos SideCar:
Теперь мы можем создать правила Ingress (измените имя хоста):
Теперь у нас есть защищенный доступ к Thanos Sidecars снаружи кластера!
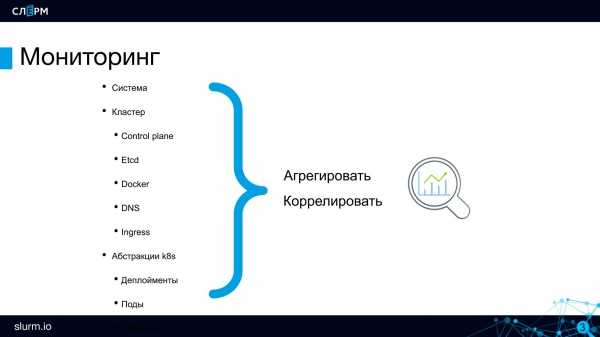
Системные сервисы, стек ПО
У каждого приложения есть своя специфика, и сложно выделить какой-то набор метрик.
Универсальным набором являются:
- рейт запросов;
- количество ошибок;
- латентность;
- saturation.
Наиболее яркие примеры мониторинга данного уровня у нас — Nginx и PostgreSQL.
Самый нагруженный сервис в нашей системе — база данных. Раньше у нас достаточно часто возникали проблемы с тем, чтобы выяснить, чем занимается база данных.
Мы видели высокую нагрузку на диски, но слоулоги ничего толком не показывали. Эту проблему мы решили с помощью pg_stat_statements, представления, в котором собирается статистика по запросам.
Это всё, что нужно админу.
Строим графики активности запросов на чтение и запись:
Всё просто и понятно, каждому запросу — свой цвет.
Не менее яркий пример — Nginx-логи. Не удивительно, что мало кто их парсит или упоминает в списке обязательных. Стандартный формат не очень информативен и его нужно расширять.
Лично я добавил request_time, upstream_response_time, body_bytes_sent, request_length, request_id.Строим графики времени ответа и количества ошибок:
Строим графики времени ответа и количества ошибок. Помните? я говорил про задачи бизнеса? Чтоб быстро и без ошибок? Мы уже двумя графиками эти вопросы закрыли. И по ним уже можно звонить дежурным админам.
Но осталась ещё одна проблема — обеспечить быстрое устранение причин инцидента.
I — Основы мониторинга Linux
Прежде чем строить всю нашу архитектуру мониторинга, давайте посмотрим, какие решения существуют в настоящее время и какие проблемы мы пытаемся решить с помощью Node Exporter.
а — Существующие решения
Как системный администратор, вы можете контролировать свою инфраструктуру Linux несколькими способами.
Инструменты командной строки
Существует множество инструментов командной строки для мониторинга вашей системы.
Они хорошо известны каждому системному администратору и часто очень полезны для выполнения простых действий по устранению неполадок на вашем экземпляре.
Некоторые примеры инструментов командной строки могут быть top или htop для использования ЦП, df или du для дисков или даже tcpdump для простого анализа сетевого трафика.
Эти решения прекрасны, но у них есть серьезные недостатки.
Помимо того, что они очень просты в использовании, они часто форматируются по-разному , что затрудняет их единообразный экспорт.
Кроме того, для выполнения этих команд вам иногда требуются повышенные привилегии в системе, что не всегда так.
Благодаря полной системе мониторинга вы можете обрабатывать правила безопасности непосредственно в вашей системе панелей управления (например, Grafana), и вам не нужно предоставлять прямой доступ к вашему экземпляру тем, кто хочет устранять неполадки в работе.
Настольные решения
Решения для настольных ПК обеспечивают более последовательное и, вероятно, более практичное решение для системного мониторинга.
Некоторыми примерами этих инструментов являются хорошо зарекомендовавший себя SolarWinds Linux Performance Monitoring Tool (который предоставляет очень полные информационные панели для вашей системы Linux) или Zabbix с продуктом Metric Collection.
Инструменты мониторинга производительности Linux от SolarWinds — это платный инструмент, но если вы хотите, чтобы решение было готово к использованию очень быстро, они представляют собой отличную возможность для мониторинга Linux.
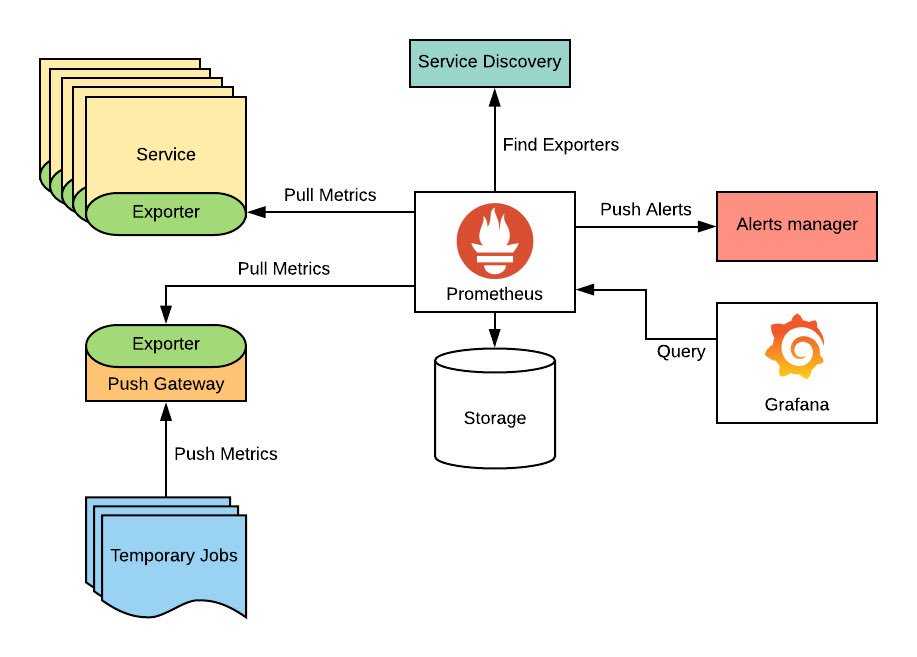
б — Экспортер узлов и Prometheus
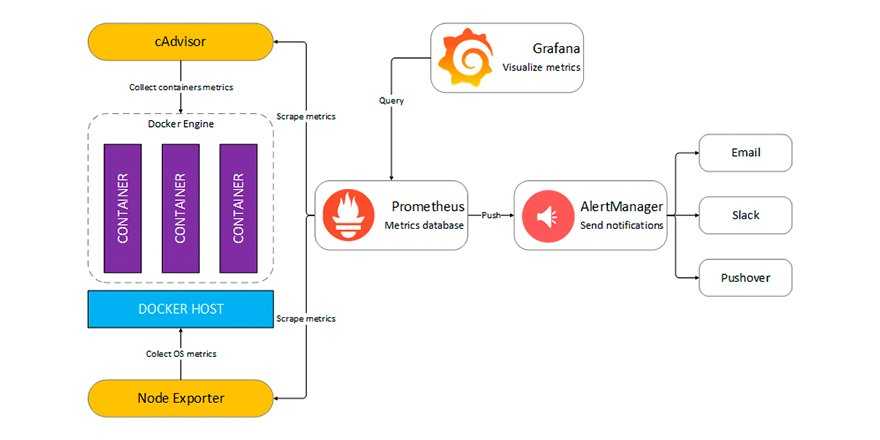
Теперь, когда мы знаем, что такое существующие инструменты для мониторинга Linux, давайте посмотрим, что мы собираемся использовать сегодня: экспортер узлов и Prometheus .
Как было сказано ранее, Prometheus очищает цели, и экспортер узлов — лишь одна из них.
В вашей архитектуре у вас будут следующие компоненты:
- База данных временных рядов , в данном случае Prometheus, предназначенная для хранения различных метрик, полученных экспортером узлов.
- Node Exporter работает как служба systemd, которая периодически (каждую 1 секунду) собирает все метрики вашей системы.
- Решение для приборной панели , в данном случае Grafana, отображающее метрики, полученные от Prometheus. Мы не собираемся строить каждую панель самостоятельно. Вместо этого мы собираемся использовать очень мощную функцию Grafana — импорт панели инструментов . (напомним, у Grafana есть список из сотен панелей мониторинга, которые вы импортируете в пользовательский интерфейс)
В нашем случае весь стек будет запущен в одном экземпляре, поэтому нет необходимости настраивать какие-либо правила брандмауэра.
Экспортер узлов будет работать на порту 9100, а Prometheus — на порту 9090.
Теперь, когда у вас есть представление о том, как выглядит архитектура мониторинга, давайте установим различные необходимые инструменты.
Мониторинг работоспособности:
- Работоспособность ElasticSearch теперь является для Zabbix’a ключевой, поэтому о проблемах в работе ES надо узнавать максимально быстро.
- Zabbix является системой мониторинга, поэтому логично следить за состоянием ES прямо из него.
- В сети есть достаточное количество готовых полнофункциональных шаблонов, но если они представляются для вас слишком громоздкими, то можете воспользоваться предложенным ниже простым вариантом.
- Итак, создайте новый шаблон в Zabbix’e:
- имя: elasticsearch;
- создайте внутри него Application «ElasticSearch»;
- назначьте этот шаблон Zabbix-серверу.
- Создайте в шаблоне метрику, которая будет следить за сетевым портом, на котором ES принимает подключения:
- Name: ElasticSearch listening on port 9200;
- Key: ;
- Application: ElasticSearch.
- Триггер для неё:
- Name: ElasticSearch is not listening on port 9200 on {HOSTNAME}
- Severity: Disaster
- Expression:
- Метрика, показывающая состояние ES (green/yellow/red, для одиночного сервера без кластеризации нормальным будет yellow):
- Name: ElasticSearch cluster health;
- Type: Zabbix agent
- * Key: elasticsearch.cluster_health_status
- Type: Character;
- Application: ElasticSearch;
- Описание метрики в настройках агента:
создайте файл /etc/zabbix/zabbix_agentd.d/elasticsearch.conf;
скомандуйте агенту перечитать настройки:
Триггер на «жёлтый» уровень здоровья:
- Name = ElasticSearch cluster status is «yellow» on {HOSTNAME};
- Severity = Warning;
- Expression = .
Триггер на «красный» уровень здоровья:
- Name = ElasticSearch cluster status is «red» on {HOSTNAME}
- Severity = High
- Expression =
Убедитесь, что первый триггер срабатывает:
- остановите ES командой ;
- в течение минуты Zabbix должен отреагировать на это на странице Monitoring => Problems;
- снова запустите ES и убедитесь, что проблема в Zabbix’e ушла.
Экспортеры
О сервисах Node.js мы уже поговорили. Как насчет MySQL? Метрики базы данных нам тоже нужны. Чтобы экспортировать имеющиеся метрики из сторонних систем в виде метрик Prometheus, можно использовать экспортеры.
Выбор экспортеров богатый. Вот некоторые из них: https://prometheus.io/docs/instrumenting/exporters/
Мы используем официальный образ экспортера MySQL и запустим его с контейнером MySQL. Для образа требуется переменная среды , значение которой будет получено из секрета. Поскольку все контейнеры в поде используют одну сеть, можно использовать localhost, чтобы подключиться к MySQL.
После создания ресурсов в Kubernetes на вкладке Prometheus Targets мы увидим следующее:
В браузере выражений Prometheus мы увидим, что метрики MySQL доступны.
Метрики MySQL в Prometheus
Теперь можно использовать функцию , чтобы посмотреть средний рост для команд select за определенный период. Это показатели только для команд select, выполненных экспортером для сбора метрик.
Если сделать то же самое с командами delete, мы увидим 0, потому что команды delete не выполнялись.
С помощью Apache Benchmark можно провести нагрузочное тестирование, чтобы создать пик.
20к запросов с AB
Пик для команд select в Prometheus
Discovery Rule
Все дальнейшие действия производятся с данными из базовой метрики, в том числе и процедура дискавери
Processing
В разделе Processing указать правило — какие именно метрики собирать
Тут важно обратить внимание на 2 момента
- Указать тип — преобразование в JSON
- Правильно указать способ преобразования
Например полученные данные выглядят так:
curl 127.0.0.1:65001 2>/dev/null | grep -v '#' | grep java_lang_GC
java_lang_GC{gc_name="G1 Young Generation",metric_name="CollectionCount",} 6091.0
java_lang_GC{gc_name="G1 Young Generation",metric_name="CollectionTime",} 1360730.0
java_lang_GC{gc_name="G1 Young Generation",metric_name="Valid",} 1.0
java_lang_GC{gc_name="G1 Old Generation",metric_name="CollectionCount",} 0.0
java_lang_GC{gc_name="G1 Old Generation",metric_name="CollectionTime",} 0.0
java_lang_GC{gc_name="G1 Old Generation",metric_name="Valid",} 1.0
Правило процессинга
java_lang_GC{metric_name=~".*", gc_name=~".*"}
"labels": {
"metric_name="CollectionCount",
"gc_name": "G1 Young Generation"
},
Макросы
Данные из этой структуры можно извлечь в макросы:
$.labels --> {#METRIC_NAME}
$.labels ---> {#GC_NAME}
{#METRIC}=$
Названия макросов произвольные (как и названия меток) — важно только что б они были одинаковы там где они задаются и там где к ним обращаются
Устранение инцидентов
Весь процесс от выявления до решения проблемы можно разбить на ряд шагов:
- выявление проблемы;
- уведомление дежурного администратора;
- реакция на инцидент;
- устранение причин.
Важно, что мы должны это делать максимально быстро. И если на этапах выявления проблемы и отправки уведомления мы особо времени выиграть не можем — две минуты на них уйдут в любом случае, то последующие — просто непаханное поле для улучшений
Давайте просто представим, что у дежурного зазвонил телефон. Что он будет делать? Искать ответы на вопросы — что сломалось, где сломалось, как реагировать? Вот каким образом мы отвечаем на эти вопросы:
Мы просто включаем всю эту информацию в текст уведомления, даем в нем ссылку на страницу в вики, где описано, как на эту проблему реагировать, как её решать и эскалировать.
Я до сих пор ничего не сказал про уровень приложения и бизнес логики. К сожалению, в наших приложениях пока не реализован сбор метрик. Единственный источник хоть какой то информации с этих уровней — логи.
Пара моментов.
Во-первых, пишите структурированные логи. Не надо включать контекст в текст сообщения. Это затрудняет их группировку и анализ. Logstash требует много времени, чтобы всё это нормализовать.
Во-вторых, правильно используйте severity-уровни. У каждого языка свой стандарт. Лично я выделяю четыре уровня:
- ошибки нет;
- ошибка на стороне клиента;
- ошибка на нашей стороне, не теряем денег, не несём риски;
- ошибка на нашей стороне, теряем деньги.
Резюмирую. Нужно стараться выстраивать мониторинг именно от бизнес-логики. Стараться замониторить само приложение и оперировать уже такими метриками, как количество продаж, количество новых регистраций пользователей, количество активных в данный момент пользователей и так далее.
Если весь ваш бизнес — одна кнопка в браузере, необходимо мониторить, прожимается ли она, работает ли должным образом
Всё остальное не важно
Если у вас этого нет, вы можете попытаться это наверстать в логах приложения, Nginx-логах и так далее, как это сделали мы. Вы должны быть как можно ближе к приложению.

DevOps
Со всеми этими экспортерами для разных систем, баз данных и серверов очевидно, что Prometheus предназначен, в основном, для сферы DevOps.
Мы знаем, что в этой сфере множество конкурирующих поставщиков и персонализированных решений.
Prometheus идеально подходит для DevOps.
Для настройки и запуска экземпляров почти не требуется усилий, и можно легко активировать и настроить любой вспомогательный инструмент.
Благодаря обнаружению целевых объектов — например, через файловый экспортер, —это отличное решение для стеков, где широко используются контейнеры и распределенные архитектуры.
В среде, где экземпляры то и дело создаются и удаляются, ни один стек DevOps не обойдется без обнаружения сервисов.
2. Здравоохранение
Сегодня решения для мониторинга нужны не только в ИТ. Они используются и в крупных отраслях, которые предоставляют гибкие и масштабируемые архитектуры для здравоохранения.
Спрос растет, и ИТ-архитектуры обязаны ему соответствовать. Если у вас нет надежного инструмента для мониторинга всей инфраструктуры, вы рискуете столкнуться с серьезными перебоями в обслуживании. Уж в сфере здравоохранения такую опасность точно надо свести к минимуму.
3. Финансовые услуги
Последний пример приводился на конференции InfoQ, где обсуждалось использование Prometheus в финансовых учреждениях.
Джейми Кристиан (Jamie Christian) и Алан Стрейдер (Alan Strader) показывали, как они используют Prometheus для мониторинга своей инфраструктуры в Northern Trust. Очень содержательно, советую посмотреть.
Prometheus
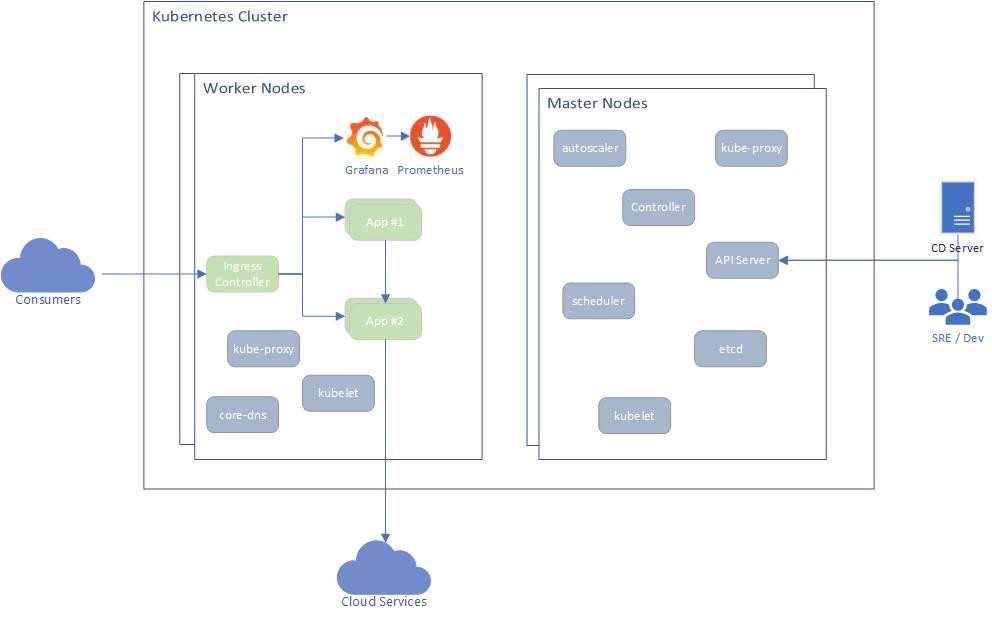
Лучшая система для мониторинга кластера — это Prometheus. Я не знаю ни одного инструмента, который может сравниться с Prometheus по качеству и удобству работы. Он отлично подходит для гибкой инфраструктуры, поэтому когда говорят «мониторинг Kubernetes», обычно имеют в виду именно Prometheus.
Есть пара вариантов, как начать работать с Prometheus: с помощью Helm можно поставить обычный Prometheus или Prometheus Operator.
- Обычный Prometheus. С ним всё хорошо, но нужно настраивать ConfigMap — по сути, писать текстовые конфигурационные файлы, как мы делали раньше, до микросервисной архитектуры.
- Prometheus Operator чуть развесистее, чуть сложнее по внутренней логике, но работать с ним проще: там есть отдельные объекты, абстракции добавляются в кластер, поэтому их гораздо удобнее контролировать и настраивать.
Чтобы разобраться с продуктом, я рекомендую сначала поставить обычный Prometheus. Придётся всё настраивать через конфиг, но это пойдёт на пользу: разберётесь, что к чему относится и как настраивается. В Prometheus Operator вы сразу поднимаетесь на абстракцию выше, хотя при желании покопаться в глубинах тоже будет можно.
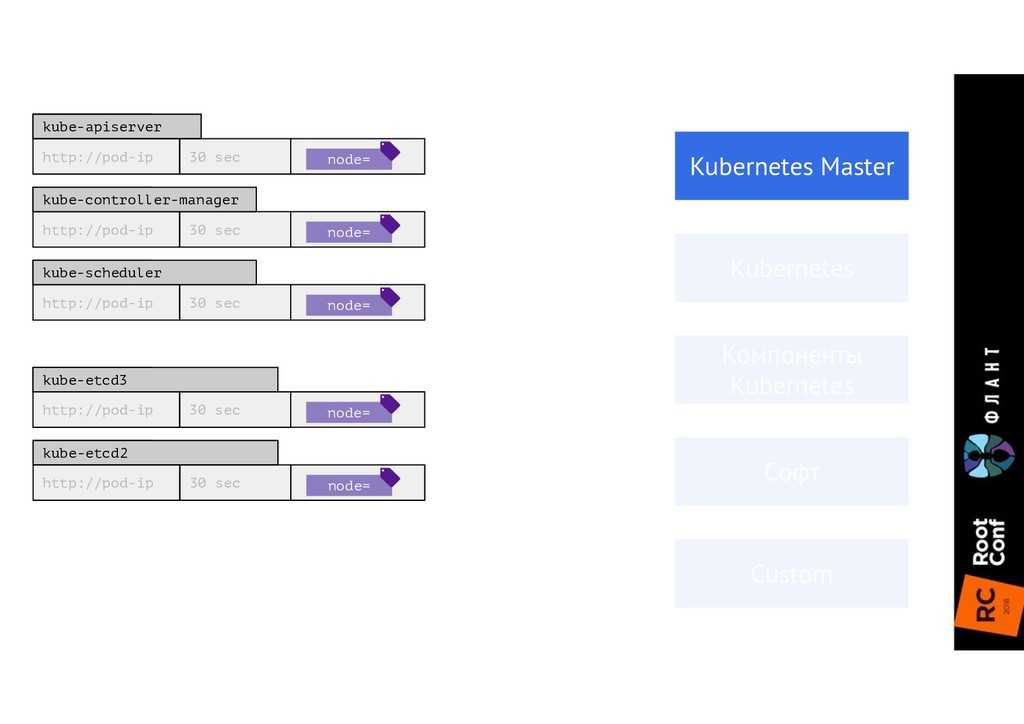
Prometheus хорошо интегрирован с Kubernetes: может обращаться к API Server и взаимодействовать с ним.
Prometheus популярен, поэтому его поддерживает большое количество приложений и языков программирования. Поддержка нужна, так как у Prometheus свой формат метрик, и для его передачи необходима либо библиотека внутри приложения, либо готовый экспортёр. И таких экспортёров довольно много. Например, есть PostgreSQL Exporter: он берёт данные из PostgreSQL и конвертирует их в формат Prometheus, чтобы Prometheus мог с ними работать.
Пример приложения
Все ресурсы, которые мы используем в этой серии статей, доступны в репозитории на GitHub: https://github.com/jonathanbc92/observability-quickstart/tree/master/part1
Пример приложения для этой серии статей будет развернут на Minikube. Оно состоит из трех контейнеров Node.js:
- People Service — сервис с простым запросом на получение данных из таблицы в MySQL.
- Format Service — сервис, который форматирует сообщение, используя значения из People Service.
- Hello Service — сервис, который вызывает предыдущие сервисы и отправляет итоговое сообщение пользователю.
У всех микросервисов уже есть дефолтные и кастомные метрики в файле metrics.js.
Чтобы задеплоить весь набор (включая Prometheus), выполните команду .
Чтобы протестировать приложение, пробросьте порт на порт hello service 8080, а затем сделайте запрос на localhost:8080/sayHello/{name}
Операционная система
- количество доступной памяти в %;
- активность использования swap: vmstat swapin, swapout;
- количество доступных inode и свободного места на файловой системе в %
- средняя загрузка;
- количество соединений в состоянии tw;
- заполненность таблицы conntrack;
- качество работы сети можно мониторить с помощью утилиты ss, пакетом iproute2 — получать из её вывода показатель RTT-соединений и группировать по dest-порту.
Также на уровне операционной системы у нас появляется такая сущность, как процессы
Важно выделить в системе набор процессов, которые играют важную роль в её работе. Если, к примеру, у вас есть несколько pgpool, то необходимо собирать информацию по каждому из них
Набор метрик следующий:
- CPU;
- память — в первую очередь, резидентная;
- IO — желательно в IOPS;
- FileFd — открытые и лимит;
- существенные отказы страницы — так вы сможете понять, какой процесс свапается.
Весь мониторинг у нас развернут в Docker, для сбора данных метрик мы используем Сadvisor. На остальных машинах применяем process-exporter.
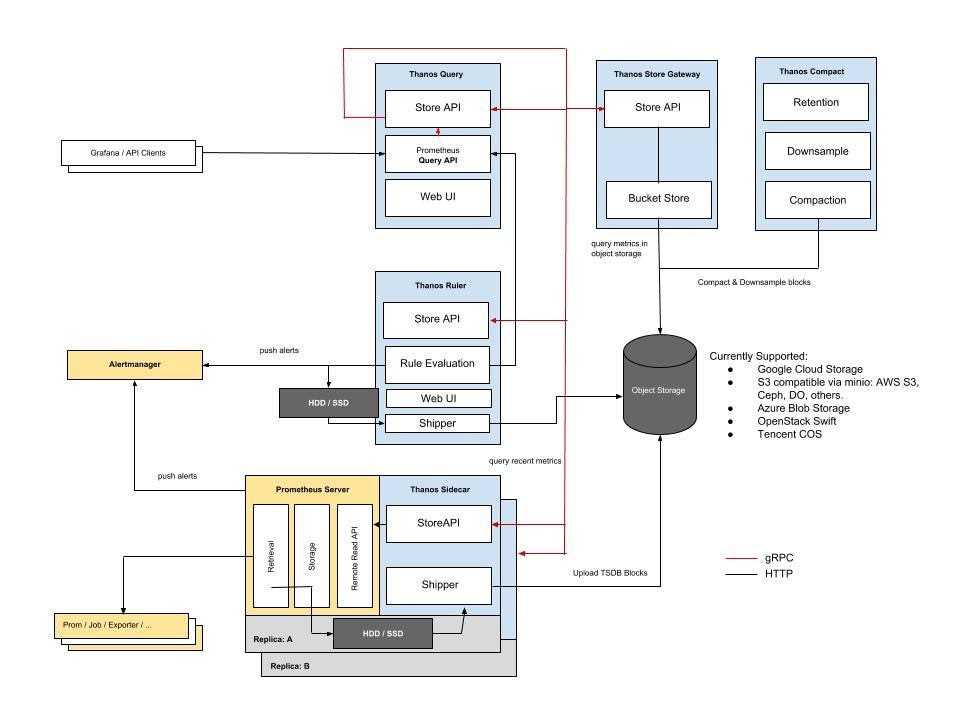
Thanos
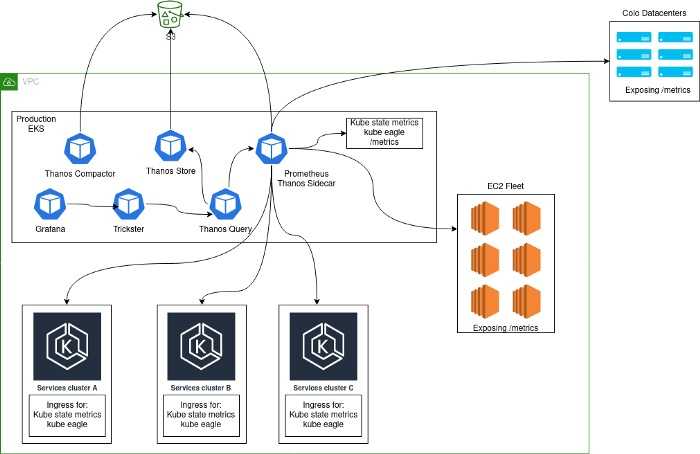
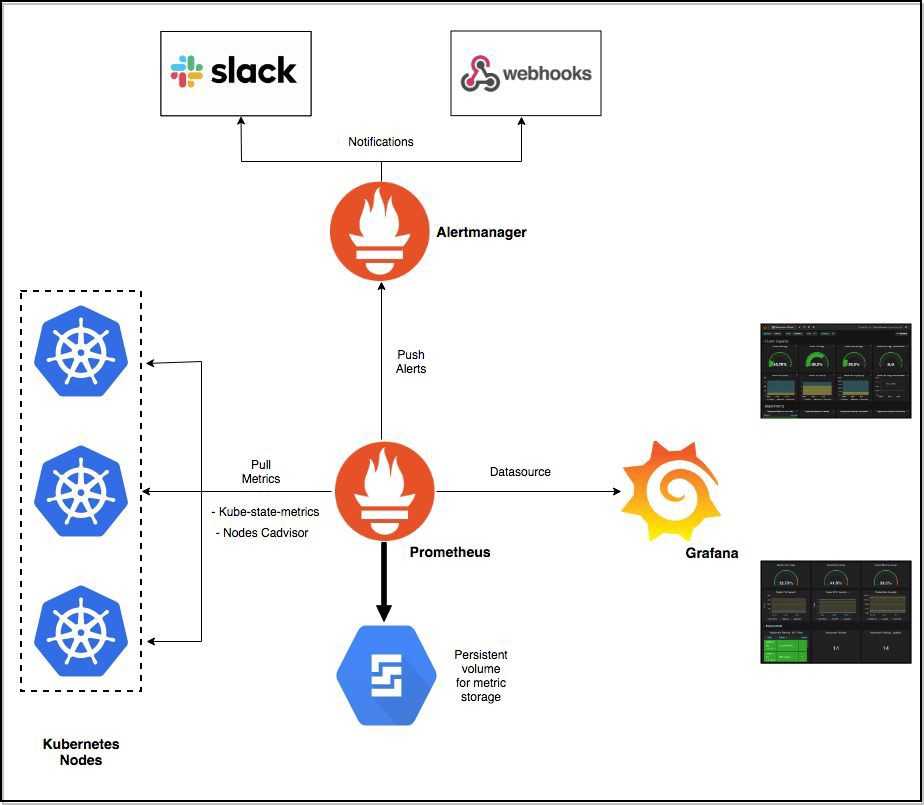
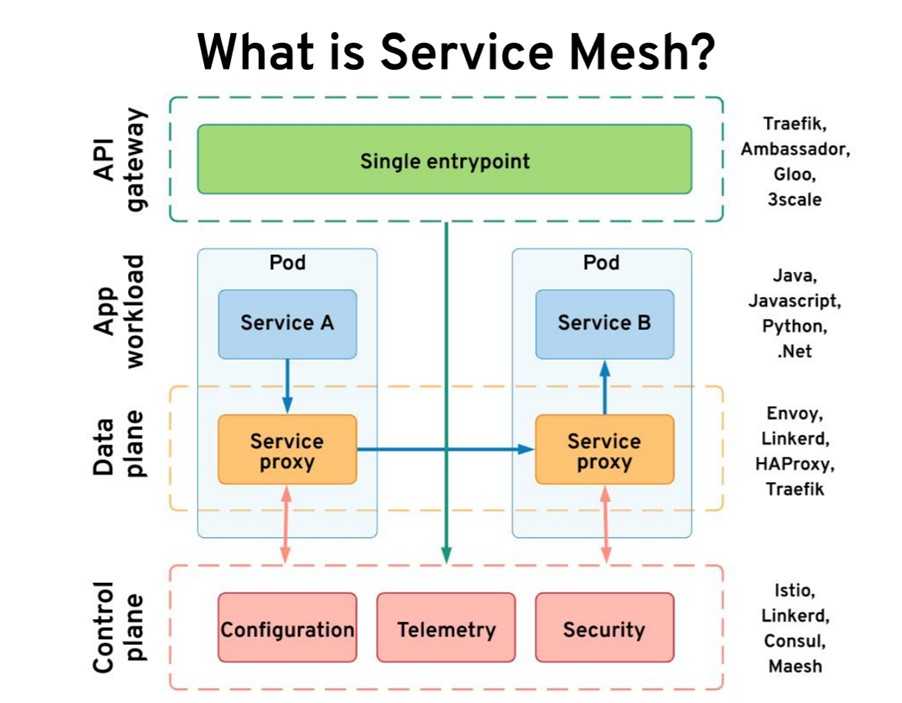
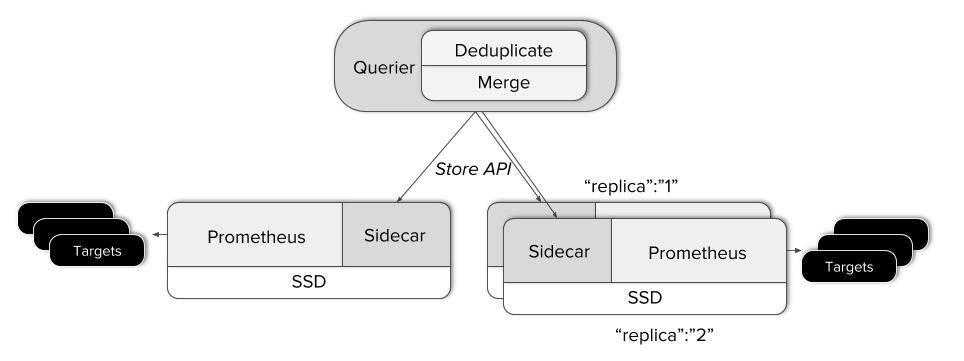
Thanos — это проект с открытым исходным кодом, на основе которого можно построить высокодоступную систему сбора метрик с неограниченным размером хранилища, бесшовно интегрирующуюся с существующими экземплярами Prometheus.
Для хранения исторических данных Thanos использует формат хранения Prometheus и может хранить метрики в любом объектном хранилище. Кроме того, он обеспечивает global view для всех экземпляров Prometheus.
Основные компоненты Thanos:
-
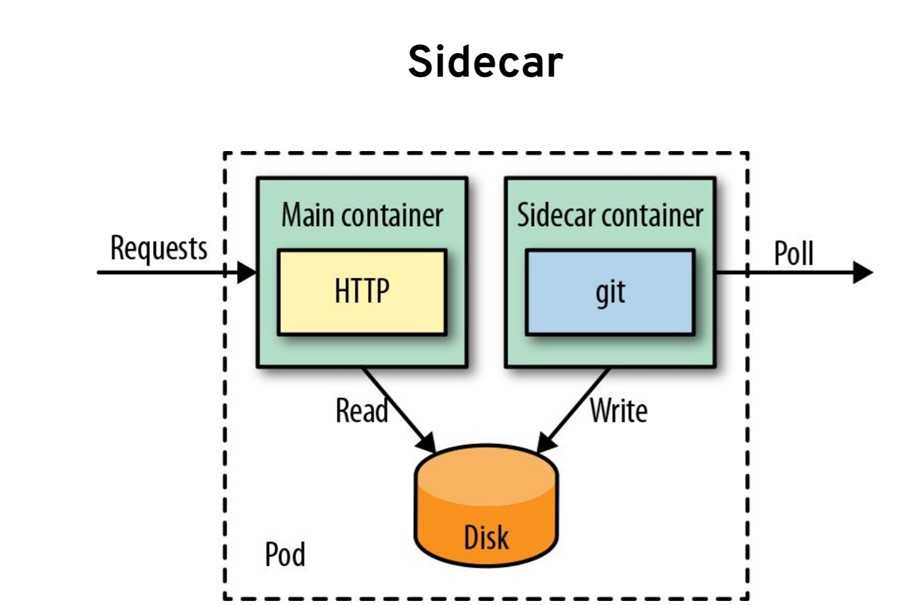
Sidecar. Подключается к Prometheus и использует его для запросов в реальном времени через Query Gateway и/или загружает его данные в облачное хранилище для длительного хранения.
-
Query Gateway. Реализует Prometheus API для агрегирования данных из нижележащих компонент (таких как Sidecar или Store Gateway).
-
Store Gateway. Предоставляет доступ к содержимому облачного хранилища.
-
Compactor. Делает уплотнение и даунсэмплинг (downsampling) данных в облачном хранилище.
-
-
Receiver. Получает данные из remote-write WAL Prometheus, предоставляет их и/или загружает в облачное хранилище.
-
Ruler. Вычисляет recording rules и alerting rules для данных в Thanos.
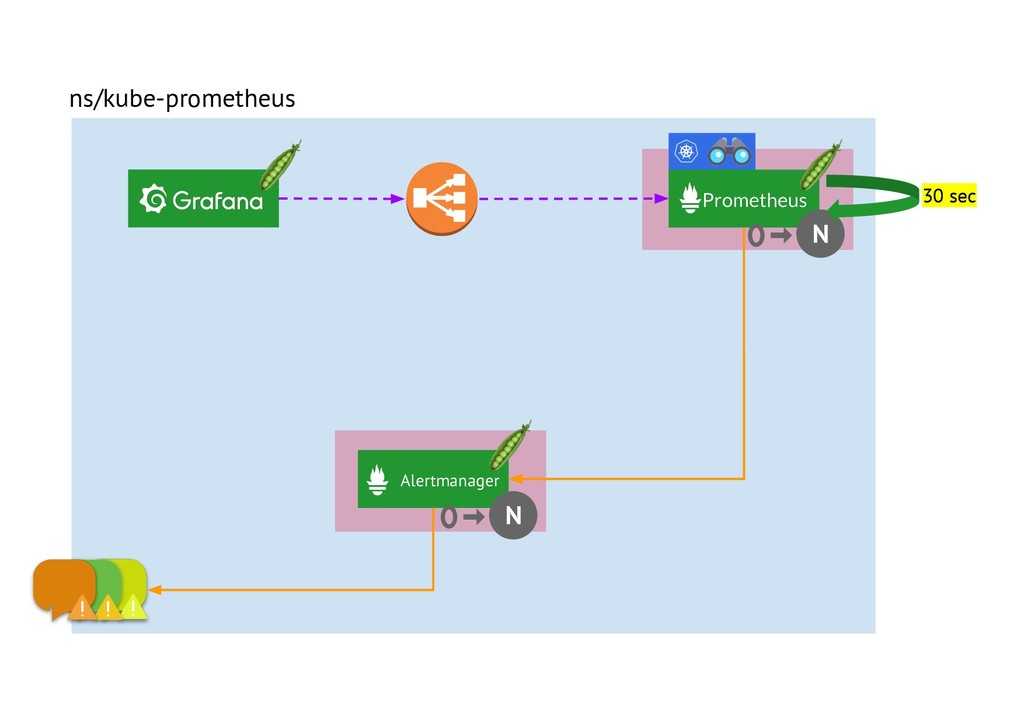
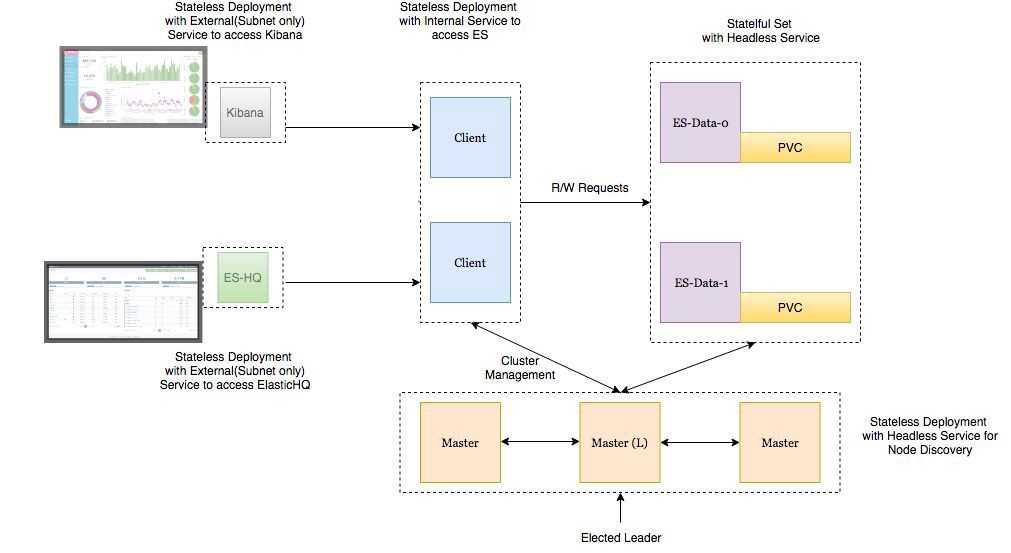
В этой статье мы сосредоточимся на первых трех компонентах.
В чем преимущество Prometheus?
Прочитав мое сравнение этих двух систем мониторинга, может показаться, что Zabbix по всем статьям лучше Prometheus. Конечно, это не так
Стоит принять во внимание то, что Zabbix я использую очень давно и хорошо знаю, поэтому я не объективен. На мой взгляд, Prometheus похож на некий framework, на базе которого строится полноценная система мониторинга
Вот его наиболее сильные стороны:
- Prometheus query language. Это свой язык запросов, очень крутая штука, аналогов которой вроде и нет нигде. С его помощью очень удобно и быстро можно построить запрос на выборку данных. В Zabbix ничего и близко нет.
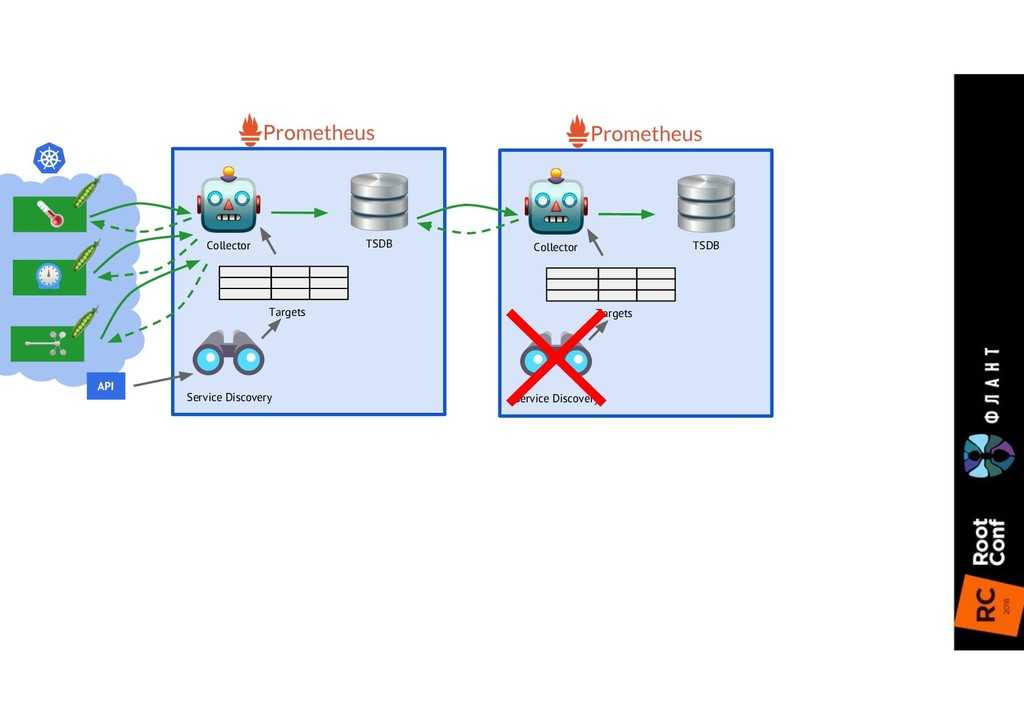
- Service discovery. Прометеус отлично подходит для динамических систем, например Kubernetes. Он автоматически находит необходимые таргеты и ставит на мониторинг.
- Exporters. Формат данных Prometheus поддерживает огромное количество софта. Они сразу из коробки выдают все метрики для Prometheus. Вам остается их только направить в него. Zabbix движется в этом направлении, создает шаблоны для приема данных с экспортеров prometheus, пишет свои шаблоны, но тут он в роли сильно отстающего.
- Highload. За счет TSDB, Prometheus может принять и обработать несравнимо больше метрик, чем Zabbix. Правда, актуально это становится для тех, у кого реально очень высокая нагрузка.
Настройка
В библиотеке есть множество опций конфигурации, посмотрите в README проекта их примеры с кратким объяснением.
Базовая конфигурация показана вверху. Просто создайте экземпляр PrometheusMetrics, назовем его metrics, а затем с его помощью определите дополнительные метрики, которые вы хотите собирать, декорировав функции:
Счетчики подсчитывают вызовы, а остальные собирают метрики в зависимости от продолжительности этих вызовов. Вы можете определить метки для каждого из них, потенциально используя свойства запроса или ответа. Например:
В приведенном выше примере нажатие на конечную точку /collection/10002/item/76 приведет к увеличению счетчика, например cnt_collection{collection = «10002», status = «200»}, плюс вы получите метрики по умолчанию (для каждой конечной точки в этом примере ) из библиотеки по умолчанию:
-
— Продолжительность HTTP-запроса в секундах для всех запросов Flask по методу, пути и статусу
-
— Общее количество HTTP-запросов по методам и статусам
Есть варианты пропустить отслеживание определенных конечных точек, зарегистрировать дополнительные метрики по умолчанию или пропустить те, что указаны выше, или применить одну и ту же настраиваемую метрику к нескольким конечным точкам. Ознакомьтесь с README проекта, чтобы узнать, что доступно.
В библиотеке есть удобные расширения для популярных многопроцессорных библиотек, таких как uWSGI и Gunicorn. Вы также можете найти небольшие примеры целевых вариантов использования, в том числе многопроцессорных.
Виртуальные машины
Хостинг выделяет нам процессор, диск, память и сеть. И с первыми двумя у нас были проблемы. Итак, метрики:
CPU stolen time — когда вы покупаете виртуалку на Amazon (t2.micro, к примеру), следует понимать, что вам выделяется не целое ядро процессора, а лишь квота его времени. И когда вы её исчерпаете, процессор у вас начнут забирать.
Эта метрика позволяет отслеживать такие моменты и принимать решения. Например, надо ли взять тариф пожирнее или разнести обработку фоновых задач и запросов в API на разные сервера.
IOPS + CPU iowait time — почему-то многие облачные хостинги грешат тем, что недодают IOPS. Более того, график с низкими IOPS для них не аргумент. Поэтому стоит собирать и CPU iowait. С этой парой графиков — с низкими IOPS и высоким ожиданием ввода-вывода — уже можно разговаривать с хостингом и решать проблему.
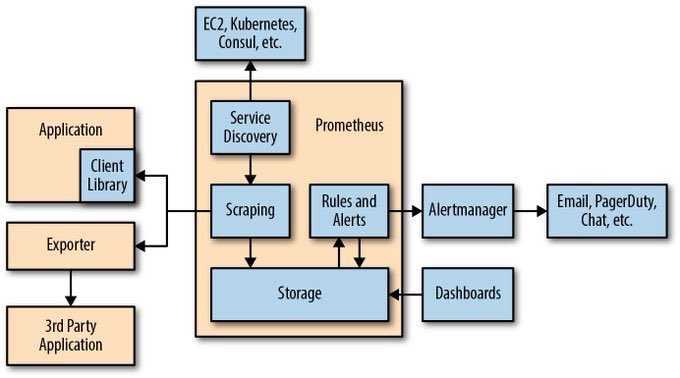
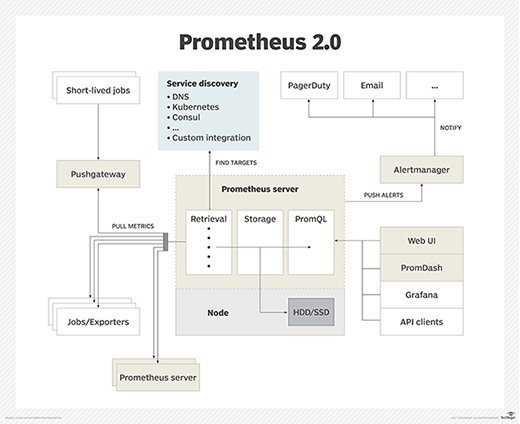
Часть I. Что такое Prometheus?
Prometheus — это база данных временных рядов. Если вы не в курсе, что такое база данных временных рядов, почитайте первую часть руководства по InfluxDB.
Но Prometheus — не просто база данных временных рядов.
К нему можно присоединить целую экосистему инструментов, чтобы расширить функционал.
Для этого Prometheus периодически скрейпит свои целевые объекты.
Что такое скрейпинг?
Prometheus извлекает метрики через HTTP-вызовы к определенным конечным точкам, указанным в конфигурации Prometheus.
Возьмем, например, веб-приложение, расположенное по адресу http://localhost:3000. Приложение передает метрики в текстовом формате на некоторый URL. Допустим, http://localhost:3000/metrics.
По этому адресу Prometheus с определенными интервалами извлекает данные из целевого объекта.
1. Как работает Prometheus?
Как мы уже сказали, Prometheus состоит из самых разных компонентов.
Во-первых, вам нужно, чтобы он извлекал метрики из ваших систем. Тут есть разные способы:
- Инструментирование приложения, то есть ваше приложение будет предоставлять совместимые с Prometheus метрики по заданному URL. Prometheus определит его как целевой объект и будет скрейпить с указанным интервалом.
- Использование готовых экспортеров. В Prometheus есть целая коллекция экспортеров для существующих технологий. Например, готовые экспортеры для мониторинга машин Linux (Node Exporter), для распространенных баз данных (SQL Exporter или MongoDB Exporter) и даже для балансировщиков нагрузки HTTP (например, HAProxy Exporter).
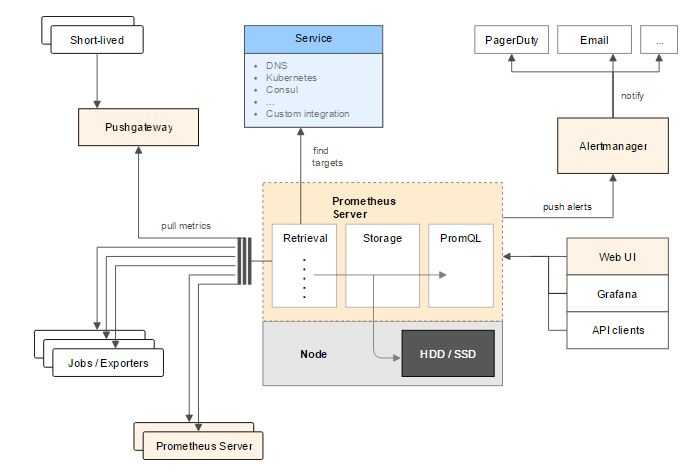
- Использование Pushgateway. Иногда приложения или задания не предоставляют метрики напрямую. Они могут быть не предназначены для этого (например, пакетные задания) или вы сами решили не предоставлять метрики напрямую через приложение.
Как вы уже поняли, Prometheus сам собирает данные (исключая редкие случаи, когда мы используем Pushgateway).
Что это значит?
Зачем это нужно?
2. Сбор vs. отправка
У Prometheus есть заметное отличие от других баз данных временных рядов: он активно сканирует целевые объекты, чтобы получить у них метрики.
InfluxDB, например, работает иначе: вы сами напрямую отправляете ему данные.
Оба подхода имеют свои плюсы и минусы. На основе доступной документации мы составили список причин, по которым создатели Prometheus выбрали такую архитектуру:
Prometheus сам решает, где и как часто проводить скрейпинг.
Если объекты сами отправляют данные, есть риск, что таких данных будет слишком много, и на сервере произойдет сбой. Когда система собирает данные, можно контролировать частоту сбора и создавать несколько конфигураций скрейпинга, чтобы выбирать разную частоту для разных объектов.
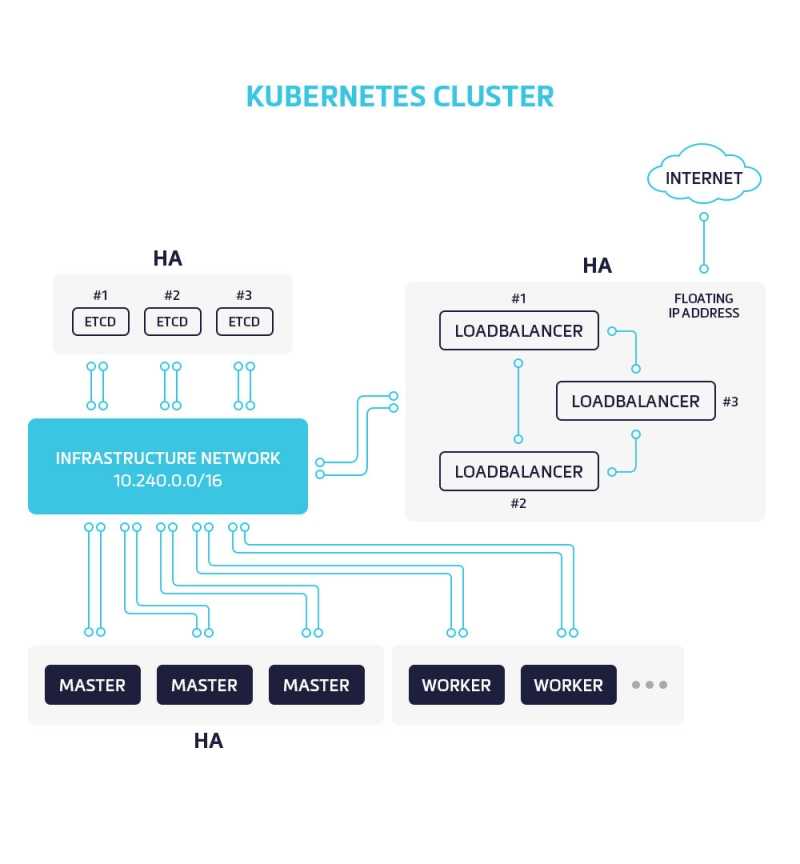
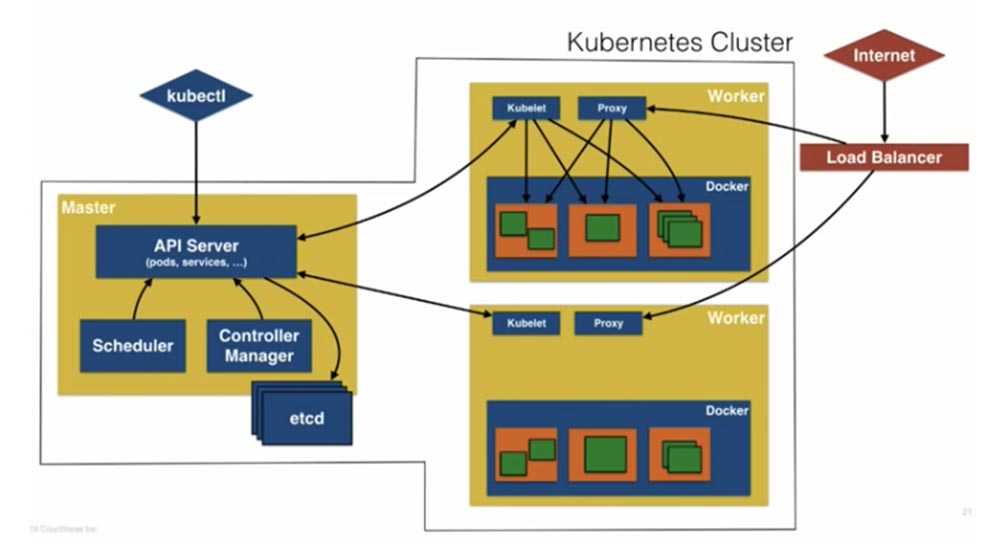
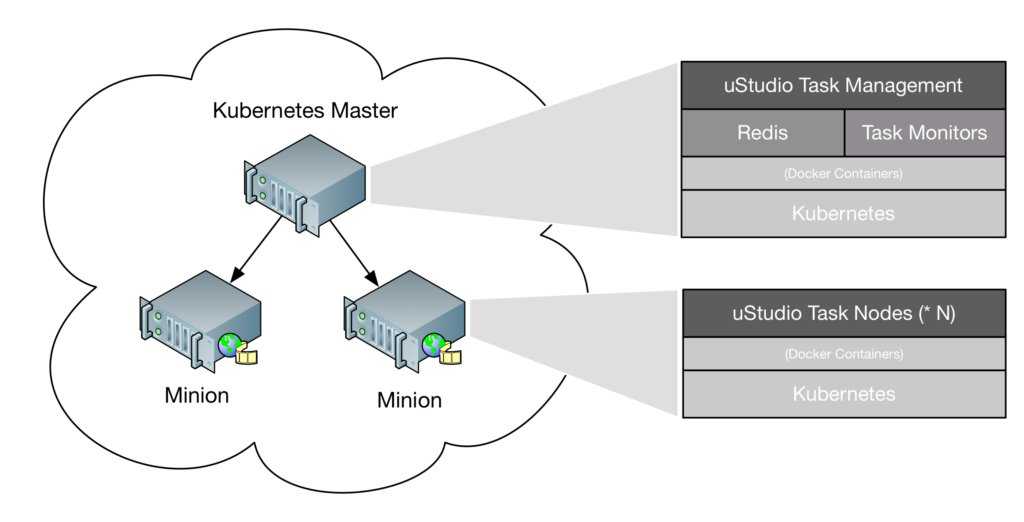
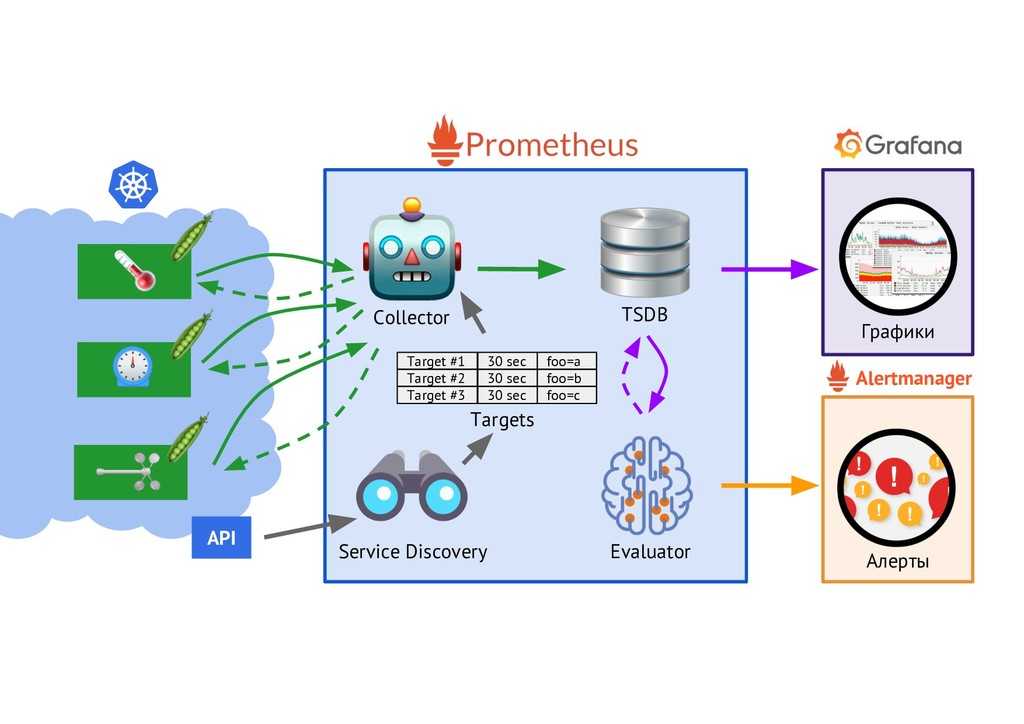
Это дополнение к первой части, где мы обсуждали роль Prometheus.
Prometheus не основан на событиях и этим сильно отличается от других баз данных временных рядов. Он не перехватывает отдельные события с привязкой ко времени (например, перебои с сервисом), а собирает предварительно агрегированные метрики о ваших сервисах.
Если конкретно, веб-сервис не отправляет сообщение об ошибке 404 и сообщение с причиной ошибки. Отправляется сообщение о факте, что сервис получил сообщение об ошибке 404 за последние пять минут.
Это главное различие между базами данных временных рядов, которые собирают агрегированные метрики, и теми, что собирают необработанные метрики.
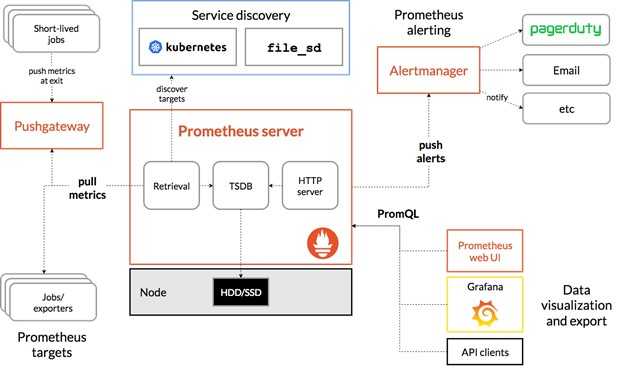
3. Развитая экосистема Prometheus
По сути Prometheus — база данных временных рядов.
Но при работе с такими базами данных часто нужно визуализировать данные, анализировать их и настраивать по ним оповещения.
Prometheus поддерживает следующие инструменты, расширяющие его функционал:
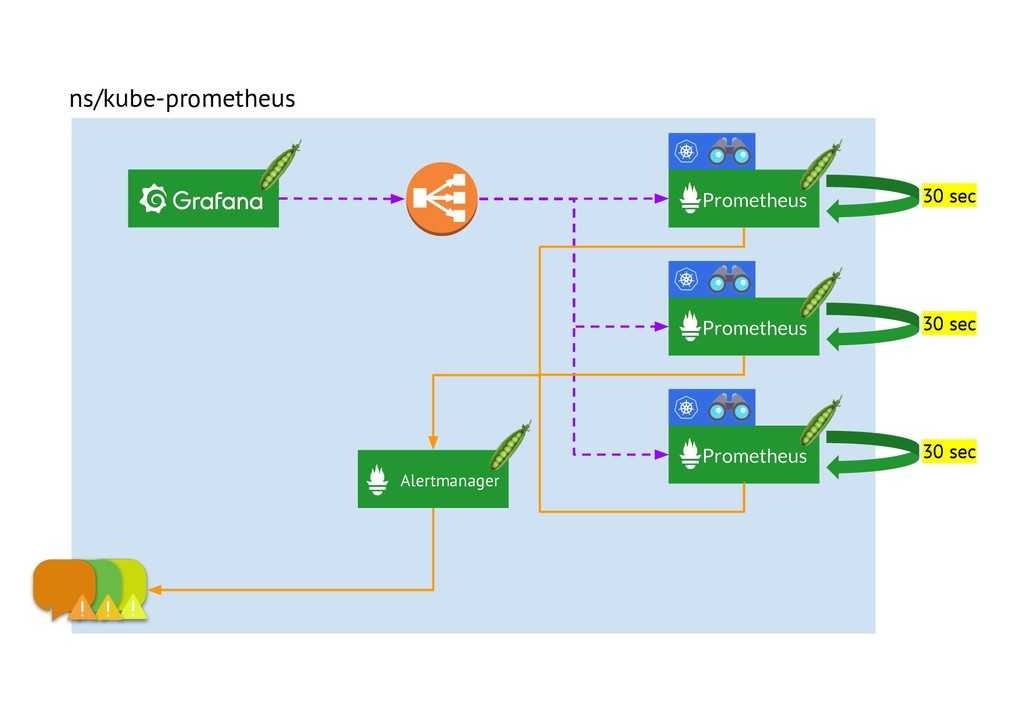
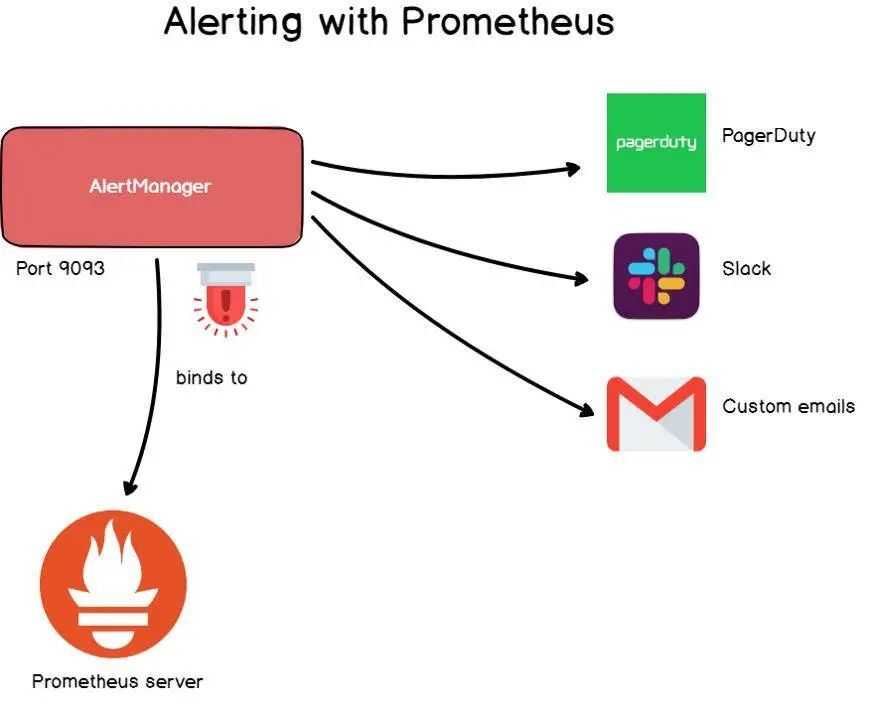
- Alertmanager. Prometheus отправляет оповещения в Alertmanager на основе кастомных правил, определенных в файлах конфигурации. Оттуда их можно экспортировать в разные конечные точки (например, Pagerduty или Slack).
- Визуализация данных. Как и в Grafana, вы можете визуализировать временные ряды прямо в пользовательском веб-интерфейсе Prometheus. Вы можете фильтровать данные и составлять конкретные обзоры происходящего в разных целевых объектах.
- Обнаружение сервисов. Prometheus динамически обнаруживает целевые объекты и автоматически скрейпит новые цели по запросу. Это особенно удобно, если вы работаете с контейнерами, которые динамически меняют адреса в зависимости от спроса.
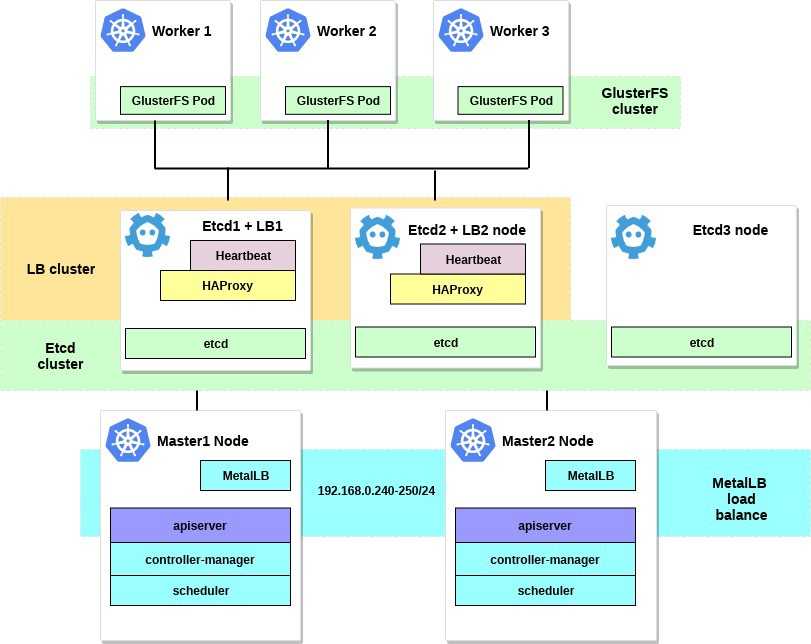
Кластер Thanos
На диаграмме развертывания Thanos, приведенной выше, вы могли заметить, что я решил развернуть Thanos в отдельном кластере. Это потому что мне нужен выделенный кластер, который можно было бы при необходимости легко воссоздать и предоставить инженерам доступ к нему, а не к продакшену.
Для развертывания компонентов Thanos я решил использовать этот Helm чарт (он пока еще не официальный, но следите за обновлениями, когда примут мой PR).
Создайте файл thanos-values.yaml, чтобы переопределить настройки чарта по умолчанию.
Поскольку для Thanos Store Gateway требуется доступ к blob-хранилищу, мы также создадим секрет хранилища в этом кластере.
Для развертывания этого чарта мы возьмем те же сертификаты, которые использовали ранее.
Это команда установит Thanos Query Gateway и Thanos Storage Gateway, настроив их на использование защищенного канала.
Теория
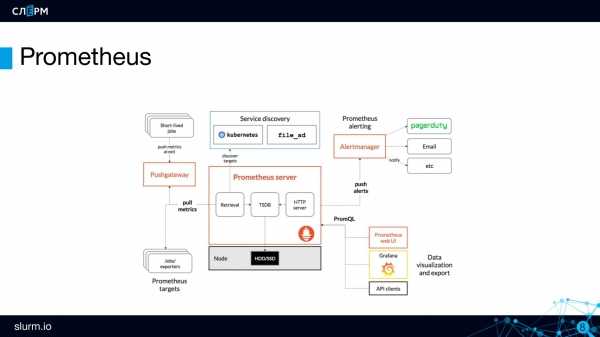
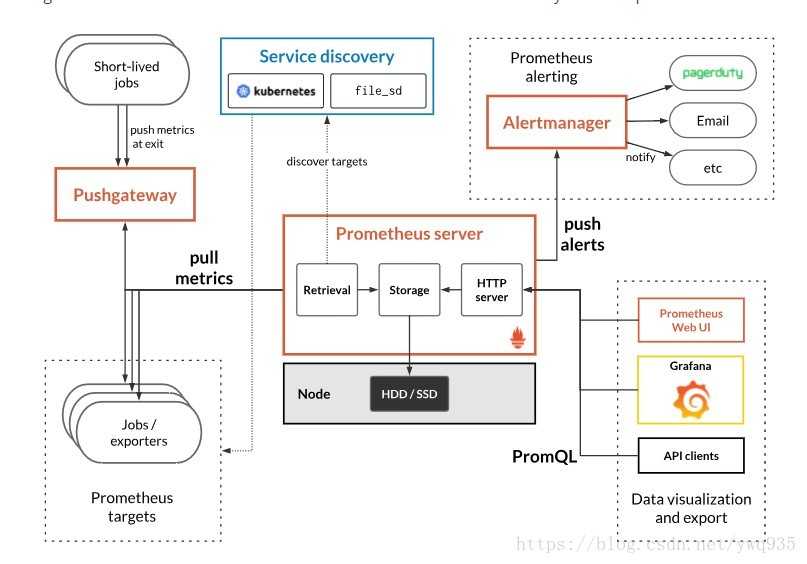
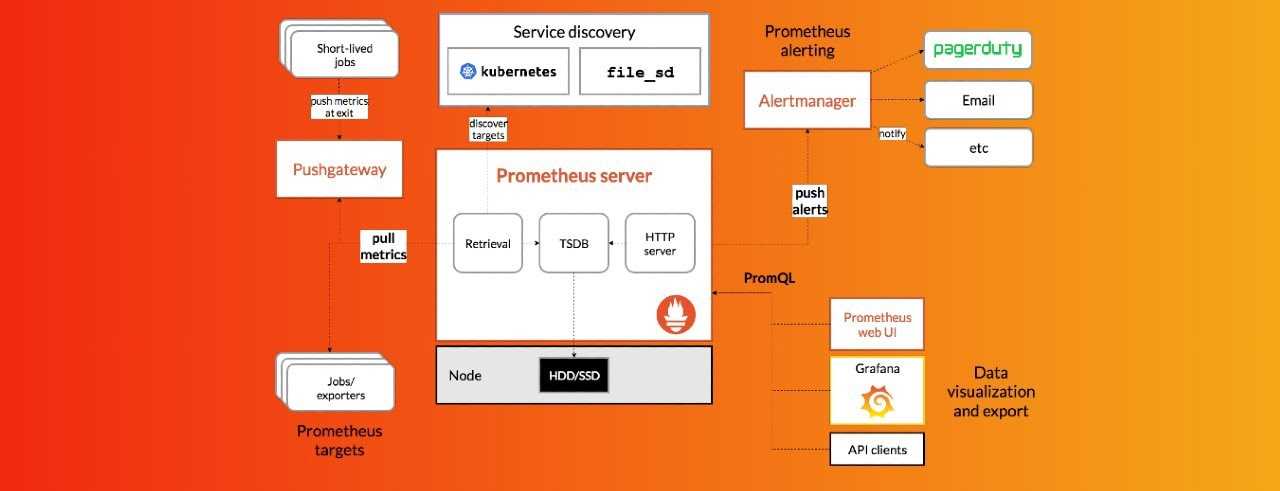
Prometheus сам собирает все данные с целевого объекта, для этого есть разные способы:
- Приложение может быть написано так, что само отдает метрики в нужном формате.
- Используются готовые экспортеры. Например, есть экспортеры для MySQL, Nginx или машины с GNU/Linux.
- Pushgateway. Применяется, когда нет возможности использовать Pull-запросы для снятия метрик стандартными средствами. Применяется, например, при выполнении задач в crontab.
Так как приём и обработка данных происходит в самом Prometheus, он является центральным звеном всей схемы мониторинга, где происходит вся настройка
Формат получаемых метрик в Prometheus — ключ-значение, это важно запомнить
Из дополнительных инструментов присутствуют:
- Alertmanager – для оповещения, его данная статья не коснётся.
- Data visualization – простой способ визуализации из коробки, из внешних можно использовать Grafana.
- Service discovery – динамическое обнаружение сервисов, также в данной статье не рассматривается.
А также присутствует PromQL – собственный язык запросов для извлечения метрик из базы данных.
Заключение
На этом по сравнению Zabbix vs Prometheus у меня все. Сел писать небольшую заметку в Telegram, но, как обычно, не смог ограничиться его форматом. Чтобы раскрыть тему, нужна полноценная статья, которая в итоге и получилась. Надеюсь, она вам была полезна. Про Прометеус не так много информации на русском языке, в отличие от Zabbix. Так что если не знакомы с продуктами, быстро сравнение сделать не получится, придется погружаться.
Онлайн курс «DevOps практики и инструменты»
Если у вас есть желание научиться строить и поддерживать высокодоступные и надежные системы, научиться непрерывной поставке ПО, мониторингу и логированию web приложений, рекомендую познакомиться с онлайн-курсом «DevOps практики и инструменты» в OTUS. Курс не для новичков, для поступления нужны базовые знания по сетям и установке Linux на виртуалку. Обучение длится 5 месяцев, после чего успешные выпускники курса смогут пройти собеседования у партнеров.
Проверьте себя на вступительном тесте и смотрите программу детальнее по .





