
Проблемы метода и их решения
Однопоточность → немасштабируемость
Когда мы попытались перейти на такую систему — всё заработало, данные доходили до Intercom, лимиты не исчерпывались. Но возникла другая проблема — каждое обращение к внешнему сервису занимает какое-то время, и когда все вызовы API «сместились» в один поток, мы совсем перестали доходить до rate-limit, перформанс customer’a был в несколько раз меньше rate-limit’ов, и стало понятно, что нужно всю эту радость как-то распараллеливать. Redis вполне безопасно (в смысле параллельности) позволяет разбирать свои очереди нескольким consumer’ам. В целом, нет никакой проблемы в том, чтобы запустить несколько consumer’ов, описанных выше, на одни и те же очереди и проблемы не будет. Каждый из них будет точно так же с соблюдением приоритетности разбирать очередь и, при превышении лимитов, ждать, пока внешний сервис сбросит лимит, и далее работать снова до исчерпания лимита.
Но мы решили немного ограничить вызовы с нашей стороны, потерять несколько десятков возможных вызовов в пределах лимитов, и не доводить consumer’ов до ситуации, когда внешний сервис сообщает им о достижении лимита вызовов. Для этого мы рассчитали для каждого consumer’а его собственный лимит на количество вызовов в единицу времени, при достижении которого он перестает разбирать очередь и делать вызовы к API до перехода к следующему временному интервалу.
Одностороннее взаимодействие с API
Иногда бывает нужно не только вызвать какой-то метод во внешнем API, но и получить и обработать его ответ. Мы же перевели наше взаимодействие компонентов с API в асинхронный формат. Проблема получения ответа от сервера и доведения его до исходного компонента — решаемая. Достаточно дополнить данные о методе, который мы хотим выполнить, данными о callback’e, который consumer’у необходимо выполнить при получении ответа от внешнего сервиса. Мы написали несколько стандартных callback’ов, которые складывают полученные ответы в определенные очереди, из которых компоненты могут их прочитать и обработать самостоятельно.
Внедрение такой структуры взаимодействия, безусловно, менее удобное, чем стандартные блокирующие вызовы методов и получение ответа сразу, но обойтись без такой жертвы нам не удалось.
Payloads
Рассмотрим некоторые полезные нагрузки которые могут быть использованы при SSRF.
-
произвольные HTTP GET запросы с отображением ответа
- localhost;
- внутренние ресурсы:
- Gitlab;
- Redmine;
- Jenkins и т.п.
-
произвольные HTTP GET запросы «слепой случай»
- код ошибки;
- время отклика.
- если удастся перехватить запрос, то в нем могут быть полезны
- user-agent — стек технологий;
- дополнительные заголовки при взаимодействии микросервисов;
- cookie или JW token — при большом везении.
-
прочее
- MySQL (Port-3306);
- FastCGI(Port-9000);
- WSGI (Port-9000);
- Memcached (Port-11211);
- Redis (Port-6379);
- Zabbix (Port-10050);
- SMTP (Port-25).
Управление веб-серверами
На аккаунте по умолчанию всегда есть минимум один веб-сервер. Чтобы изменить его версию, выберите нужную в выпадающем списке.
Изменение затронет все сайты, которые обслуживает этот веб-сервер.
Чтобы изменить версию бекенда (PHP, Python, Node.JS) для отдельного сайта, перенесите его на другой веб-сервер. Если подходящего веб-сервера на вашем аккаунте пока нет, создайте его, нажав кнопку «Добавить сервер». В открывшемся окне выберите версию бекенда и добавьте на него сайты, кликнув на поле «Подключить сайты»:
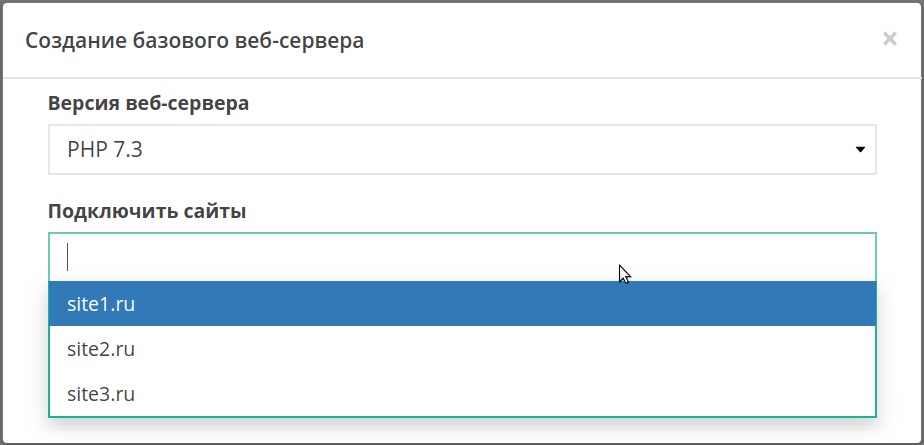
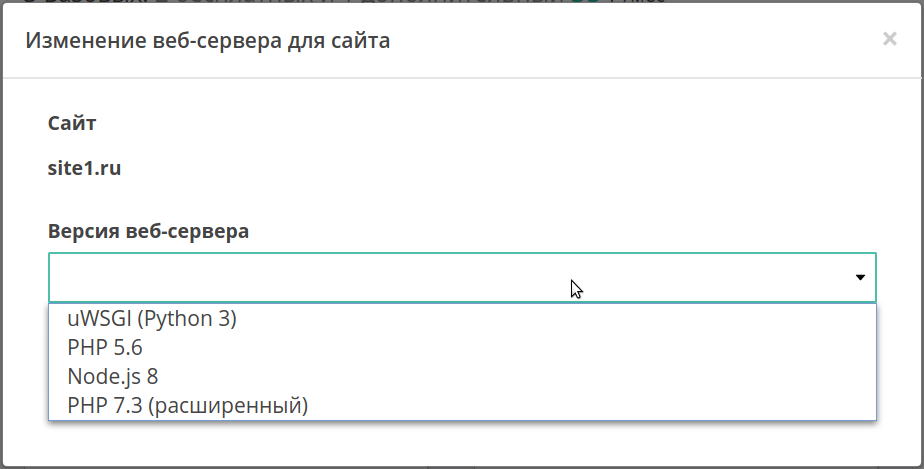
А если нужный бекенд уже есть, просто кликните на имя сайта, а затем выберите искомый веб-сервер в выпадающем списке.
Удалить веб-сервер можно, если на нем нет сайтов. Для этого нажмите на иконку ведра
Пора заканчивать
Все ограничения, которые накладывает браузер, — результат десятилетий изучения атак на веб-приложения. Поэтому фронтенд-разработчику обязательно нужно понимать, как они работают. При проектировании приложения, основываясь на архитектуре и специфике данных, нужно сформировать у себя некоторые правила «гигиены» информационной защиты, придерживаться их и постоянно обновлять чтением литературы.
В завершение приведу слова своего преподавателя по защите информации: «Невозможно создать 100%-защиту. Наша задача — сделать так, чтобы взлом информации обходился дороже, чем сама информация».
Мысли о решении проблемы вслух
Понятно, что хаотичный вызов методов внешнего ограниченного API из разных компонентов когда хочется, может быстро привести к неприятным последствиям. Прогрузка «продвинутых» данных из аналитического контура рано или поздно перебьет и не даст загрузиться важным «базовым» данным из бекенд-компонента, каким бы настойчивым и терпеливым мы его не настроили.
Из-за этого сразу же приходят мысли, что нам нужна «единая точка общения» с этим API, которая будет непосредственно обращаться к API, контролировать исчерпание лимитов и управлять логикой по приоритизации взаимодействия с API. К этой точке, в свою очередь, должны обращаться все желающие взаимодействовать с API компоненты.
Защита кода фронтенда от XSS
XSS-атака опасна только тогда, когда есть возможность вставить вредоносный код во фронтенд-содержимое, JS, HTML или даже CSS. Поэтому, во-первых, нужно стараться устранить такие возможности, а во-вторых, даже если злоумышленник смог поместить свои скрипты пользователю, сделать так, чтобы эти скрипты не достигли цели. С этим нам поможет CSP, описанный выше. Тем не менее, его недостаточно. Нужно обезопасить код одностраничного приложения от попадания чужого кода. О чём нужно помнить для этого при фронтенд-разработке:
1) Не доверяйте на 100% сторонним библиотекам. Собирать фронтенд современными сборщиками и проверять используемые пакеты с помощью npm audit (yarn audit). Если используете CI/CD, добавлять npm audit —audit-level=moderate перед шагом сборки. Если npm audit выявил уязвимости с уровнем moderate или выше, значит необходимо обновить эти библиотеки. Если обновление не помогло, стоит подумать, использовать ли эти пакеты. Эта мера защитит вас от большинства уязвимостей в подключаемых библиотеках.
2) Не вставляйте в код «чистые» значения переменных, которые потенциально могут содержать пользовательские данные. «Опасные» символы нужно экранировать. Рекомендуется делать это так:
Современные фронтенд-фреймворки сами прекрасно с этим справляются, если вы им не скажете обратного. Например, во Vue для вставки переменной в разметку следует использовать синтаксис mustache (`value`), а не атрибут v-html. Иногда возникают ситуации, когда всё же надо вставлять HTML из внешнего источника. Делать это позволительно только тогда, когда вы полностью этому источнику доверяете. Например, это сервисные сообщения, сгенерированные бэкендом. Но и в этом случае лучше подстраховаться и пропускать такие переменные через, например, HtmlSanitizer.
3) НИКОГДА не используйте в JS конструкцию . Поверьте, должен быть другой способ решения вашей задачи.
4) Не храните важные данные в Сookie. Если нужно хранилище сессий — договоритесь с бэкэнд-разработчиками и используйте только HttpOnly Сookie.
5) Не объединяйте на одном домене сайты разного назначения. Например, у вас есть сайт сервиса на какой-нибудь популярной CMS, доступный по домену service.test. Личный кабинет сервиса на этом же домене, но с другим path, например service.test/account, который использует localStorage. Если злоумышленник найдёт и воспользуется уязвимостью CMS для внедрения XSS, он сможет завладеть localStorage клиента личного кабинета.
6) Дополнительно ознакомьтесь с рекомендациями OWASP.
Как проверить, поддерживает ли HTTPS сервер определённый протокол
По умолчанию s_client будет пытаться использовать лучший протокол для связи с удаленным сервером и сообщать согласованную версию в выходных данных.
Protocol : TLSv1.3
Если вам нужно протестировать поддержку определённых версий протокола, у вас есть два варианта. Вы можете явно выбрать один протокол для тестирования, указав один из ключей —ssl3, -tls1, -tls1_1, -tls1_2 или -tls1_3. Кроме того, вы можете выбрать протоколы, которые вы не хотите тестировать, используя один или несколько из следующих параметров: -no_ssl3, -no_tls1, -no_tls1_1, -no_tls1_2 или -no_tls1_3.
Примечание: не все версии OpenSSL поддерживают все версии протокола. Например, более старые версии OpenSSL не будут поддерживать TLS 1.2 и TLS 1.3, а более новые версии могут не поддерживать более старые протоколы, такие как SSL 2 и SSL 3. К примеру, при попытке использовать опцию -ssl3 на современных версиях OpenSSL возникает ошибка:
s_client: Option unknown option -ssl3
Базовые и расширенные веб-серверы Apache
Мы предоставляем для каждого аккаунта персональные веб-серверы Apache в базовой и расширенной конфигурациях. На расширенном веб-сервере доступно несколько акселераторов и больший, в сравнении с базовым, объем памяти для их работы. Вы сможете использовать несколько декодеров и утилиту для отладки кода.
Настройки веб-серверов перечислены в таблице:
| Базовый | Расширенный | |
|---|---|---|
| Версия | PHP 5.2 – 8.0NodeJS 6 – 12Python 2.7 – 3.8 | PHP 5.2 – 8.0NodeJS 6 – 12Python 2.7 — 3.8 |
| Оптимизация для 1С-Битрикс | UTF8, CP1251 | UTF8, CP1251 |
| Изолирование | ||
| Перезапуск | ||
| Акселераторы | Zend OPCache | Zend OPCache, xCacheeAccelerator, APCAPC-u, APCu-bc |
| Память для кеширования, Мб | 32 | 128–2048 |
| php.ini | PHP_INI_PERDIRPHP_INI_ALL | PHP_INI_PERDIRPHP_INI_ALLPHP_INI_SYSTEM |
| Декодеры | ionCube Loader | ionCube LoaderZendGuardZendOptimizer |
| Диагностические утилиты | – | xDebug |
Вы можете добавить на аккаунт неограниченное количество базовых веб-серверов и до 4 расширенных . Управлять веб-серверами можно в одноименном разделе Панели управления.
Ошибка Service not found при обращении к веб-сервису 1С:Предприятия
Пример полного текста ошибки:
| 1 | Service notfound |
Описание:
При обращении к веб-сервису, после авторизации(если таковая требуется) – возникает ошибка, что сервис не найден. То есть публикация самой базы отвечает, но веб-сервиса нет или он не отвечает.
Ошибка часто связана с ошибками в именах самого веб-сервиса или его ссылки.
Решение:
Проверить имена веб-сервисов и ссылок на них.
-
- Конфигурационный файл публикации базы *.vrd
| 1 | vim/var/www/e1c/base/default.vrd |
следующего содержания:
|
1 |
<?xml version=»1.0″ encoding=»UTF-8″?> <point xmlns=»http://v8.1c.ru/8.2/virtual-resource-system» xmlns:xs=»http://www.w3.org/2001/XMLSchema» xmlns:xsi=»http://www.w3.org/2001/XMLSchema-instance» base=»/base» ib=»Srvr=1s-on-1c-1; Ref=base»> <ws> <point name=»ws_1s_on_1″ alias=»ws_1s_on_1.1cws» enable=»true»/> <point name=»ws_1s_on_2″ alias=»ws_1s_on_2.1cws» enable=»true»/> </ws> </point> |
point name – имя сервиса в конфигураторе;
alias – это имя ссылки, по которой будем обращаться к веб-сервису. Именно это имя необходимо вводить в браузер при проверке работы веб-сервиса.
В нашем случае веб-сервиса ws_1s_on_3.1cws нет в файле.
Доступ к файловой базе 1с через интернет в браузере
Теперь перемещаемся на виртуальную машину с nginx. Предварительно не забудьте добавить dns запись в каком-то домене, по которой вы будете ходить в базу через интернет. Она нам нужна, чтобы выпустить бесплатный tls сертификат, чтобы ходить в базу по https. Я не буду привязываться к какой-то конкретной операционной системе и рассказывать, как все делать именно в ней. Систему выбирайте на свой вкус. Настройка будет одинаковой. Нам нужны будут в системе 2 пакета: nginx и certbot. Установите их:
# yum install nginx certbot
или
# apt install nginx certbot
На данную виртуальную машину должны быть проброшены 80 и 443 порты с внешнего ip адреса. Как это будет сделано, зависит от ваших сетевых настроек. В случае с proxmox я настраиваю подобный проброс с самого хоста с помощью iptables. Пример настройки iptables читайте в отдельной статье. Там есть и про проброс. Не буду на этом задерживаться в статье про 1С.
Теперь нам нужно получить сертификат. Для этого запускайте в консоли certbot и следуйте инструкциям. Перед этим остановите nginx. Для быстрого получения сертификата certbot предлагает временно запустить свой веб сервер на 80-м порту.
# systemctl stop nginx # certbot certonly
Подробно получение сертификата let’s encrypt с помощью certbot я рассматриваю в статье про . Результатом работы certbot должны быть tls сертификаты в директории /etc/letsencrypt/live. Используем их в настройке виртуального хоста nginx для публикации баз 1С. Создаем в директории /etc/nginx/conf.d/ конфиг 1c.site.ru.conf примерно следующего содержания. Взял его с рабочего сервера.
server {
listen 443 ssl http2;
server_name 1c.site.ru;
access_log /var/log/nginx/1c-access.log;
error_log /var/log/nginx/1c-error.log;
ssl_certificate /etc/letsencrypt/live/1c.site.ru/fullchain.pem;
ssl_certificate_key /etc/letsencrypt/live/1c.site.ru/privkey.pem;
location /.well-known/acme-challenge/ {
root /tmp;
}
location / {
auth_basic "Restricted Access";
auth_basic_user_file /etc/nginx/htpasswd.1c;
proxy_pass http://10.10.10.11:80;
proxy_set_header Host $host;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-Proto https;
}
}
server {
listen 80;
server_name 1c.site.ru;
return 301 https://1c.site.ru$request_uri;
}
В данном случае 10.10.10.11 — локальный ip адрес виртуальной машины с windows, где опубликована база 1С через apache. Доступ к 1С сразу же закрыт отдельным паролем и механизмом веб сервера auth basic. Создадим файл с именем пользователя и паролем, указанным в конфиге.
# htpasswd -c /etc/nginx/htpasswd.1c user1c
Если у вас нет в системе утилиты htpasswd, то установите пакет httpd-tools. Она из него. user1c — имя пользователя. Пароль вам предложат задать в консоли.
Теперь можно запускать nginx и проверять доступ к базе 1с по https с дополнительной авторизацией. Так как в конфиге nginx настроен proxy_pass всех запросов через location / , то на самой виртуалке с 1С вы можете публиковать сколько угодно баз через алиасы, например /buh3, /zup3 и т.д. Все они будут автоматом направляться с nginx на apache. При этом на самом nginx конфигурацию менять не придется.
Вот и все. Можно относительно безопасно выставлять такую конструкцию в интернет. В случае необходимости можно настроить fail2ban, если кто-то надумает перебирать пароли или просто выполнять непонятные запросы к веб серверу с опубликованными базами. При желании в том же nginx с помощью директив allow и deny можно ограничить доступ к виртуальному хосту с базами на уровне ip адресов. Это на случай, если не умеете делать то же самое на фаерволе. В nginx проще и быстрее.
Не забудьте настроить автоматическое обновление tls сертификатов. Как это сделать, я рассказываю в статье с настройкой web сервера. Ссылку на нее я дал выше.
Вводные данные
Меня зовут Юрий Гаврилов, я работаю в команде Data Platfrom в ManyChat. У нас в компании есть маркетинговый отдел, который, среди всего прочего, любит общаться с нашими клиентами через сервис Intercom, позволяющий отправлять удобные In-App сообщения пользователю прямо в нашем веб-приложении. Чтобы эти коммуникации были осмысленными, Intercom должен получать некоторую информацию о наших клиентах (имя, дату регистрации, различные простые метрики их аккаунтов и т.д.). За предоставление этих данных в Intercom отвечает наш довольно-таки монолитный бекенд-компонент, хранящий информацию о наших пользователях. А ещё, совсем недавно, мы построили классный аналитический контур (о котором обязательно расскажем в следующих статьях), также хранящий кучу информации о наших пользователях, и довольно изолированный от упомянутого выше бекенд-компонента. В этом контуре аналитики обсчитывают более сложные пользовательские метрики, гоняют ML-алгоритмы и хранят витрины с результатами всех этих вычислений. Для ещё более крутых коммуникаций с клиентами, часть из этих результатов также хотелось бы иметь в Intercom.
И тут мы сталкиваемся с проблемой: есть разные, изолированные друг от друга компоненты, желающие делать вызовы внешнего API с довольно сильным ограничением в 1000 запросов в минуту. При этом, ограничение применяется в рамках всего аккаунта Intercom, а не рассчитывается индивидуально для каждого компонента.
Что делать, когда запросов становится настолько много, что очереди разгребаются часами/днями/неделями?
Здесь мы точно не волшебники, и запрограммировать свое взаимодействие с внешним API так, чтобы превышать его rate-limit, мы точно не можем. По задачам загрузки данных наших клиентов мы внедрили у себя систему по учету тех данных, что уже были отправлены во внешний сервис. Когда наступает очередная выгрузка данных о пользователях, отправляются только данные о тех пользователях, которые обновились, и, тем самым, уменьшается необходимое количество запросов.
В остальном, в данной ситуации не остаётся ничего иного, кроме как разговаривать со внешним сервисом на тему увеличения лимита запросов.
Ручная настройка EFA
Мы же пошли сложным путем, но более гибким. Настройку EFA под себя делали не через интерактивное меню, а правили конфигурационные файлы. Мы хотели не просто всё настроить, а еще и разобраться во всех компонентах и понять, что и как работает.
Первым делом в файле main.cf настроек postfix добавили mynetworks, с которых принимались соединения по SMTP. Затем прописали ограничения по helo запросам, отправителям, получателям, и указали пути к картам с политиками ACCEPT или REJECT при соблюдении определенных условий. Также, inet_protocols был изменен на ipv4, чтобы исключить соединения по ipv6.
Затем изменили политику Spam Actions на Store в конфигурационном файле /etc/MailScanner/MailScanner.conf. Это значит, что если письмо будет определено как спам, оно уйдет в карантин. Это помогает дополнительно обучать SpamAssassin.
После таких настроек мы столкнулись с первой проблемой. На нас обрушились тысячи писем от адресатов you@example.com, fail2ban@example.com, root@localhost.localdomain и т.д. Получатели были схожие. Также получили письма, отправленные MAILER-DAEMON, то есть фактически без отправителя.
В итоге получили забитую очередь без возможности найти среди «красного полотна» нормальные, письма не-спам. Решили делать REJECT подобных писем, используя стандартный функционал Postfix карт: helo_access, recipient_access, sender_access. Теперь вредные адресаты и подобные стали успешно REJECT’иться. А те письма, которые отправлялись MAILER-DAEMON отфильтровываются по helo запросам.
Когда очередь вычистили, а наши нервы успокоились, начали настраивать SpamAssassin.
Через веб-интерфейс
Первый способ — через веб-интерфейс MailWatch. В каждом письме можно увидеть заголовки, тело, а также оценку по алгоритму Байеса и других показателях. Выглядит это так:
| Score | Matching Rule | Description |
|---|---|---|
| -0.02 | AWL | Adjusted score from AWL reputation of From: address |
| 0.80 | BAYES_50 | Bayes spam probability is 40 to 60% |
| 0.90 | DKIM_ADSP_NXDOMAIN | No valid author signature and domain not in DNS |
| 0.00 | HTML_MESSAGE | HTML included in message |
| 1.00 | KAM_LAZY_DOMAIN_SECURITY | Sending domain does not have any anti-forgery methods |
| 0.00 | NO_DNS_FOR_FROM | Envelope sender has no MX or A DNS records |
| 0.79 | RDNS_NONE | Delivered to internal network by a host with no rDNS |
| 2.00 | TO_NO_BRKTS_HTML_IMG | To: lacks brackets and HTML and one image |
| 0.00 | WEIRD_PORT | Uses non-standard port number for HTTP |
Открыв письмо, можно поставить галку в чекбоксе «SA Learn» и выбрать одно из нескольких действий:
- As Ham — пометить письмо как чистое (тренировка алгоритма Байеса);
- As Spam — пометить письмо как спам (тренировка алгоритма Байеса);
- Forget — пропустить письмо;
- As Spam+Report — пометить письмо как спам и отправить информацию о нём в сети по обнаружению спама (razor + pyzor);
- As Ham+Revoke — пометить письмо как чистое и отправить информацию о нём в сети по обнаружению спама (razor + pyzor).
Через консоль
Делается это просто. Команда выглядит следующим образом:
В этой команде письмо с ID: 0DC5B48D4.A739D, которое находится в архиве спам писем за определенную дату /20170224/spam/, помечается как чистое (не спам) .
Бытует мнение, что достаточно обучать SpamAssassin только для эффективной фильтрации почты. Мы решили тренировать SpamAssassin, скармливая ему абсолютно все письма, как чистые, так и спам. В дополнение, мы нашли базу спам-писем и отдали SA на растерзание.
Такая тренировка помогла более точно откалибровать Байесовский алгоритм. В результате фильтрация происходит гораздо эффективнее. Такие тренировки мы проводим тогда, когда почтовый трафик не очень высок, чтобы успеть проанализировать и захватить максимальное количество писем.
Для того, чтобы SpamAssassin начал работать на полную мощность, на старте ему необходимо скормить около 1000 различных писем. Поэтому наберитесь терпения и приступайте к тренировке.
Пока еще рано говорить о полной победе над спамом. Однако, сейчас количество жалоб на спам с наших серверов равно нулю. Более детально рассказывать о самом процессе обучения сейчас не будем— не хочется раскрывать все фишки. Хотя, если поковыряться в настройках, разобраться не сложно.
P.S.: Эта статья не является панацеей. Мы просто решили поделиться с вами одним из наших методов борьбы со спамом.
Онлайн сервис для анализа веб-логов Apache
Пример журнала:

Очевидно, что эти записи весьма объёмны, поскольку содержат сведения об отдельных запросах. Например, если пользователь открывает страницу вашего сайта, на который используется один файл стилей CSS, один JavaScript файл и пять картинок, то в общей сложности к серверу будет сделано восемь запросов (HTML код, CSS код, JavaScript код и 5 запросов для получения изображений). Вся эта информация сохраняется в журналах веб-сервера.
Вручную можно найти, например, информацию об определённом IP адресе, но для любых статистических исследований, нужно применять специальные программы.
Пример такой программы — goaccess. Вообще-то, это программа для Linux — там она устанавливается одной командой. Но не спешите обламываться: во-первых, если немного заморочиться, то можно её установить и в Windows, а во-вторых, есть онлайн сервис, куда вы загружаете свои логи, а он вам выводит полный отчёт.
Начнём с онлайн сервиса, его адрес: https://suip.biz/ru/?act=goaccess (всё абсолютно бесплатно и без регистраций).
Данный онлай сервис извлекает всю возможную информацию и проводит анализ логов Apache.
Для каждого лога Apache выводится такая информация как:
- сводные данные (количество запросов, количество неудачных запросов, общее количество посетителей, количество запрошенных файлов, объём переданных данных в Гигабайтах, количество ошибок «404 Страница не найдена» и прочее)
- детальная информация о датах посещений и количестве хитов, посетителей и переданных данных за каждую дату
- запрошенные файлы с возможностью сортировать список по частоте запросов или по количеству переданных данных
- статистика запросов с возможностью сортировать список по частоте запросов или по количеству переданных данных
- запросы, вызвавшие ошибку «404 Страница не найдена»
- посетители сделавшие наибольшее количество запросов к серверу с информацией о стране и городе (с возможностью сортировки данных ко количеству переданной информации)
- об операционных системах с разделением на версии
- о веб-браузерах с разделением на версии
- о распределении активности на сервере по часам
- о страницах, с которых пришли посетители
- о сайтах, с которых пришли посетители
- поисковые слова с которых пришли из Google
- HTTP коды статусов (200, 404 и другие)
- расположение посетителей по странам и населённым пунктам
Поддерживаемые форматы логов:
- Комбинированный формат логов
- Комбинированный формат логов с Виртуальными хостами
- Обычный формат логов
- Обычный формат логов с Виртуальными хостами
- Расширенный формат логов W3C
- Родной формат логов Squid
- Amazon CloudFront Web Distribution
- Облачное хранилище Google
- Amazon Elastic Load Balancing
- Amazon Simple Storage Service (S3)
Всё до безобразия просто: скачиваете с хостинга лог, который хотите изучить, здесь присоединяете файл и отправляете его — мгновенно получаете готовый отчёт.
Ошибка веб-сервера Apache при публикации 1С «Syntax error on line…»
Полный текст ошибки:
|
1 |
сен 16 11:41:54 1s-on-web-1 httpd: AH00526: Syntax error on line 6 of /etc/httpd/e1c/base.conf: сен 16 11:41:54 1s-on-web-1 httpd: Invalid command ‘forceHandler’, perhaps misspelled or defined by a module not included in the server configuration |
Описание ошибки:
Ошибка связана с ошибками или «опечатками» в файле настроек base.conf. Иными словами, в данном файле есть некорректные строки, которые новичку бывает сходу не так просто найти.
Решение:
Исправить ошибку в строке сообщения. В данном случае допущена опечатка в имени команды.
| 1 | vim/etc/httpd/e1c/base.conf |
Пример ошибочной строки. Команды forceHandler — на самом деле не существует :
|
1 |
Alias «/base» «/var/www/e1c/base/» <Directory «/var/www/e1c/base/»> AllowOverride All Options None Require all granted forceHandler 1c-application ManagedApplicationDescriptor «/var/www/e1c/base/default.vrd» </Directory> |
Исправим файл. Укажем корректное наименвоание команды — SetHandler:
|
1 |
Alias «/base» «/var/www/e1c/base/» <Directory «/var/www/e1c/base/»> AllowOverride All Options None Require all granted SetHandler 1c-application ManagedApplicationDescriptor «/var/www/e1c/base/default.vrd» </Directory> |



