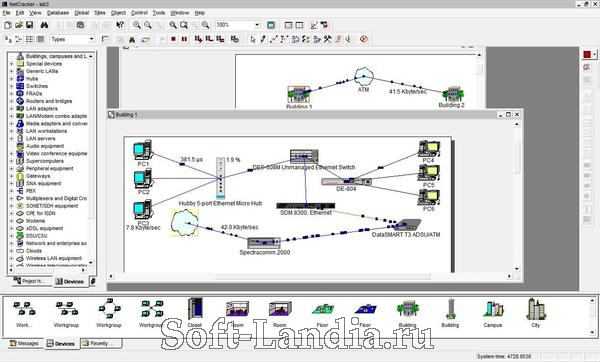
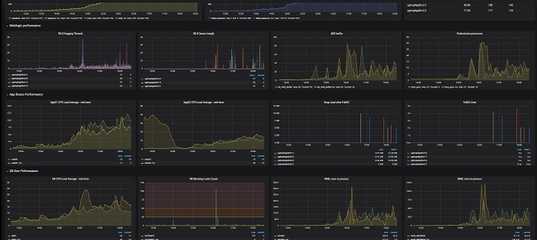
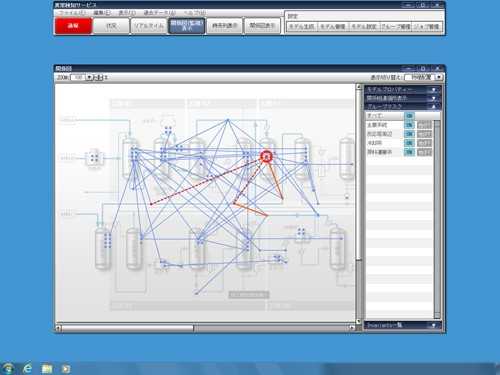
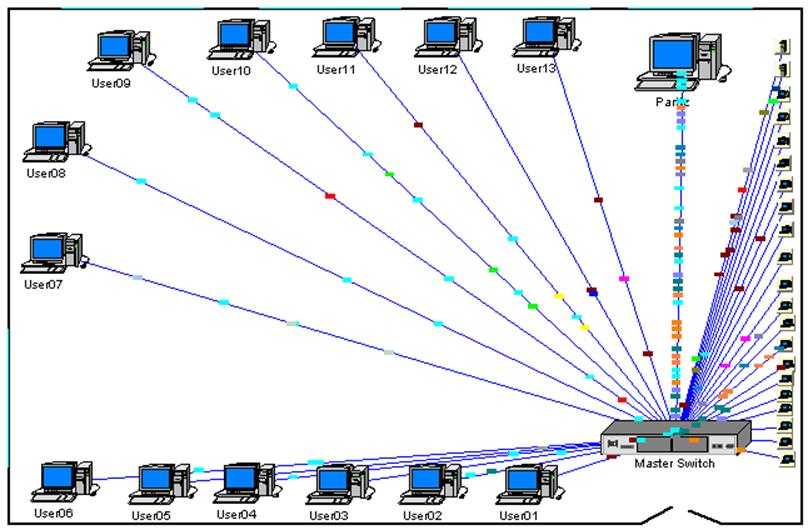
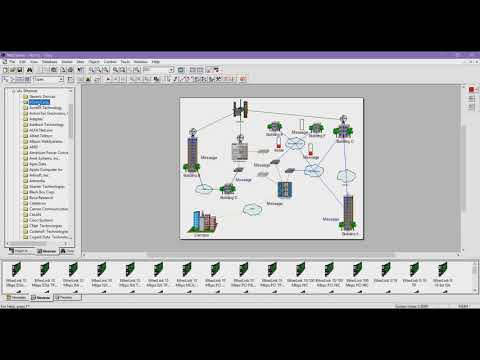
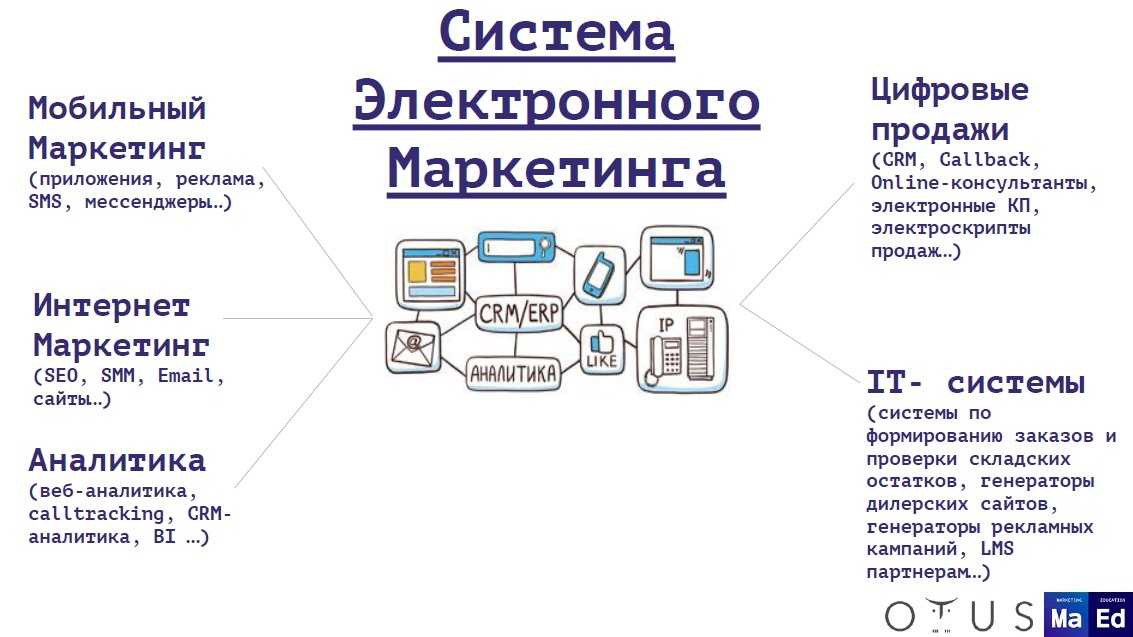
Метрики
Для сбора и просмотра метрик для кластеров AKS и любых других зависимых служб Azure рекомендуется использовать Azure Monitor .
-
Для метрик кластера и контейнера включите Azure Monitor для контейнеров. Если эта функция включена, Azure Monitor собирает метрики памяти и процессора из контроллеров, узлов и контейнеров через API метрик Kubernetes. Дополнительные сведения о метриках, доступных в Azure Monitor для контейнеров, см. в статье производительность кластера AKS с Azure Monitor для контейнеров.
-
Для сбора метрик приложения используйте Application Insights . Application Insights — это расширяемая служба управления производительностью приложений (APM). Чтобы использовать его, установите пакет инструментирования в приложении. Данный пакет выполняет мониторинг приложения и отправляет данные телеметрии службе Application Insights. Он также может извлечь данные телеметрии из среды узла. Затем данные отправляются в Azure Monitor. Application Insights также обеспечивает встроенную корреляцию и отслеживание зависимостей (см. раздел ниже).
Application Insights имеет максимальную пропускную способность, измеряемую в событиях в секунду, а также регулируется, если скорость передачи данных превышает ограничение. Дополнительные сведения см. в разделе . Создавайте разные экземпляры Application Insights для каждой среды, чтобы среды разработки и тестирования не конкурируют за рабочую телеметрию для квоты.
Одна операция может создавать несколько событий телеметрии, поэтому, если в приложении большой объем трафика, может произойти регулирование. Чтобы устранить эту проблему, вы можете выполнить выборку для уменьшения трафика телеметрии. Однако при этом ваши метрики будут менее точными. Дополнительные сведения см. в статье Выборка в Application Insights. Вы также можете уменьшить объем данных путем предварительного агрегирования метрик, то есть вычислить статистические значения (например, среднее и стандартное отклонение) и отправить их вместо необработанной телеметрии. В следующей записи блога описывается подход к использованию Application Insights в масштабе: Azure Monitoring and Analytics at Scale (Мониторинг и аналитика в Azure в нужном масштабе среды).
Если скорость передачи данных достаточно высока для запуска регулирования, а выборка или агрегирование неприемлемы, рассмотрите возможность экспорта метрик в базу данных временных рядов, например Prometheus или InfluxDB , выполняющиеся в кластере.
-
InfluxDB — это система принудительной отправки. Агент должен принудительно отправлять метрики. Вы можете использовать стек тактов, настроить мониторинг Kubernetes и отправить его в InfluxDB с помощью Telegraf, который является агентом для сбора и создания отчетов о метриках. InfluxDB можно использовать для нерегулярных событий и строковых типов данных.
-
Prometheus — это система извлечения по запросу. Она периодически извлекает метрики из настроенных расположений. Prometheus может получать метрики, созданные cAdvisor или kube-state-metrics. kube-state-metrics — это служба, которая собирает метрики с сервера API Kubernetes и делает их доступными для Prometheus (или службы, совместимой с конечной точкой клиента Prometheus). Для метрик системы используйте Node exporter. Это средство экспорта Prometheus для метрик системы. Prometheus поддерживает данные с плавающей запятой, а не строки, поэтому эта система подходит для метрик системы, но не для журналов. Сервер метрик Kubernetes — это агрегатор в масштабе кластера данных об использовании ресурсов.
Уровни сбора, обработки и визуализации данных
|
При этом нас интересуют два глобальных типа данных: события о сбоях в тех или иных системах или объектах мониторинга и показатели функционирования – например, параметры доступности, производительности и т. д. Этот уровень модифицируется в зависимости от ИТ-ландшафта, с которым мы работаем, и тех систем, которые есть у заказчика, и он может быть изменен наиболее гибко, — поясняет Валентин Нык, руководитель отдела систем управления ИТ-инфраструктурой «Крок». |
Следующий логический уровень, самый сложный, но также изменяемый – обработка и агрегация данных. Массив данных, который поступил из внешних систем, интеллектуально обрабатывается и принимает форму готовой аналитической информации: к примеру, он позволяет найти первопричину сбоя, аномалию функционирования ИТ-инфраструктуры. На этом уровне включаются различные наработки «Крок»: аналитические движки, элементы машинного обучения, построение ресурсно-сервисных моделей, сложные корреляционные правила на основе которых можно провести сложную аналитику.
Построение адекватной ресурсно-сервисной модели – очень нетривиальная задача, логика расчета в ней достаточно сложная. Ранее эту функцию действительно выполняли только большие закрытые вендорские решения. Но теперь «Крок» тоже умеет делать подобные расчеты, причем на открытом ПО.
|
Кроме того, мы используем машинное обучение в области систем мониторинга. Не секрет, что для адекватного построения модели поведения объекта необходимы большие объемы, и мониторинг — хороший источник для этой, по сути, Big Data. Мы собираем информацию о функционировании объектов инфраструктуры, чтобы делать сложную аналитику, которая позволяет добиться, к примеру, прогнозирования показателей ИТ-инфраструктуры или сервиса, — добавляет Валентин Нык. |
Обработка данных мониторинга движком машинного обучения позволяет модели самостоятельно обучаться выявлению причинно-следственных связей. Это позволит либо предиктивно отреагировать на проблему, либо реактивно ее решить в случае возникновения. Накопленная база знаний о возможных путях решения проблемы помогает оператору системы выбрать наиболее подходящее. Практика показывает, что такой подход позволяет значительно сократить время восстановления после сбоя. Это, по сути, шаг в будущее — когда движки машинного обучения будут предсказывать проблемы предиктивно или реактивно их решать в автоматическом режиме с помощью инструментов автоматизации, основываясь на базе знаний. Будущее систем мониторинга за интеллектуальной обработкой событий.
Третий уровень – визуализация уже обработанной информации: различные дашборды, отчеты – своеобразный ситуационный центр. Здесь «Крок» предлагает интуитивно понятный, функциональный дизайн, индивидуальный для каждого заказчика, используя открытые фреймворки с готовым набором различных графических виджетов и портлетов.
Какие решения для мониторинга есть на рынке
Решения для мониторинга сети можно разделить условно на три класса. Первый — это различные open source-программы, которые можно скачать и использовать бесплатно. Но, как и многие бесплатные продукты, они поставляются не в «коробочном» виде и требуют тонкой настройки под конкретные задачи, что, в свою очередь, требует наличия в штате квалифицированных специалистов. При этом специалисту не стоит забывать, что вся ответственность за работу решения в данном случае лежит на нем, а компании — что специалист может сменить место работы и разобраться в его настройках будет очень непросто.
«Использование open source-программ вполне оправдано при решении базовых задач мониторинга, к примеру — состояния конкретного порта коммутатора, мониторинга не бизнес критичных сервисов, или в том случае, когда нужен какой-то кастомизированный подход», — объясняет Иван Орлов, эксперт по мониторингу сетевой инфраструктуры ИТ-компании КРОК.
Второй класс решений — это инструменты мониторинга, включенные в состав продуктов других производителей. К примеру, компании-поставщики средств виртуализации, а также оборудования сетевой инфраструктуры, предлагают уже готовые системы мониторинга под их решения.





![Мониторинг и отладка voip-сетей с помощью сетевого анализатора [rtfm.wiki]](https://tehnikaarenda.ru/wp-content/uploads/d/f/9/df92889d42a746b1bc86bc8e9612b94c.jpeg)

«Это профессиональный продукт, за разработку и поддержку которого отвечает производитель, опираясь на лучшие мировые практики. Нет явной необходимости что-то дописывать или изобретать — включил и работает. Но нужно понимать, что функциональность такого решения может быть ограничена работой только с определенным набором оборудования или систем», — говорит Иван Орлов.
Третий класс — это специализированные NPMD-решения (network performance monitoring and diagnostic) enterprise уровня. Их производители сфокусированы и специализируются на разработке продуктов для глубокого анализа производительности сетевой инфраструктуры и предлагают наиболее функциональные решения на рынке.
«NPMD уровня enterprise — это не просто анализ состояния сети с точки зрения ее скорости или задержек, это инструмент мониторинга качества работы бизнес-приложений с точки зрения сетевого взаимодействия ее участников. Сети будущего — это сети, ориентированные на приложения. А мониторинг сети, ориентированный на приложения, — это уже настоящее», — объясняет Иван Орлов.
Свежие новости и статьи
Статьи
28 июля 2021
ИТ аутсорсинг и ИТ-аутстаффинг – в чем разница?
От клиентов часто можно услышать: «Нам остро не хватает рабочих рук, все штатные единицы заняты, нужно взять кого-то на подряд». Желание вполне объяснимое, учитывая огромный дефицит ИТ-специалистов, от которого сейчас страдает вся отрасль.
Закрыть потребность во внешних ИТ-специалистах можно по-разному: через ИТ-аутсорсинг или ИТ-аутстаффинг. Многие путают эти понятия, считая их почти равнозначными. Но между ними есть существенные различия. Выясняем, какие именно.
Статьи
15 июля 2021
SLA – три «волшебные» буквы
ИТ-аутсорсинговая компания берет на себя определенный круг задач
и ответственность за их выполнение. Но что делать, если качество в итоге вас не устроило?
Когда речь идет о штатном сотруднике, меры понятны (хотя далеко
не всегда эффективны) – «профилактические беседы», повышение квалификации или, в крайнем случае, увольнение. А как быть
с привлеченным подрядчиком? Ответ в этой аббревиатуре – SLA, Service Level Agreement или соглашение об уровне сервиса

Статьи
29 июня 2021
3 оттенка ИТ-аутсорсинга: какой подходит именно Вам?
Зачем предпринимателю знать различия между несколькими видами ИТ-аутсорсинга? Все просто: даже если сейчас вы пользуетесь каким-то одним набором услуг, все может быстро поменяться и вам понадобится что-то новое. Поэтому сегодня поговорим о том, каким в принципе может быть ИТ-аутсорсинг.

Статьи
18 июня 2021
Зачем бизнесу нужен аудит ИТсистем (ИТ аудит)?
В самом начале сотрудничества ИТ-аутсорсинговая компания часто предлагает провести аудит ИТ-систем в компании. Однако многим собственникам эта услуга кажется лишней: зачем тратить деньги, ведь штатные ИТ-специалисты и без аудита знают все «боли» и проблемные точки в компании с точки зрения ИТ.
Действительно, зачем? Давайте разбираться!
Статьи
8 июня 2021
Шпаргалка по выбору ИТ-аутсорсера часть 3
Критерий, на который часто не обращают внимания. И напрасно!
Сегодня речь пойдет о доверии и безопасности, без которых в ИТ-аутсорсинге не обойтись. Как только вы заключаете контракт, ИТ-аутсорсер получает доступ к «сердцу» вашего бизнеса: финансовой информации, базам данных, личным данным персонала и контрагентов. Однако собственники бизнеса недооценивают фактор безопасности и больше смотрят на стоимость, количество выездов специалистов и т.д. На основе практики ALP GROUP расскажем, что можно предпринять уже на старте сотрудничества, чтобы обезопасить свой бизнес.
Контроллер
- С2000-КДЛ — базовая модель (обозначение расшифровывается как «Система 2000 — Контроллер Двухпроводной Линии связи»);
- С2000-КДЛ-2И — добавлены гальванические развязки для RS-485 и ДПЛС;
- С2000-КДЛ-Modbus — в конструкцию С2000-КДЛ-2И добавлен преобразователь протокола Modbus С2000-ПП.
ДПЛС
- относятся к конфигурируемому типу, а не программируемому (т.е. нужно только настроить параметры, а не разрабатывать программу);
- поддержка в ДПЛС до 127 адресных устройств (С2000-ВТ имеет два адреса), причем многие пуско-наладчики не рекомендуют использовать больше 100-110;
- двойной ввод по питанию DC 12-24В;
- не слишком удобная конструкцию корпуса (все подключаемые провода невозможно спрятать в корпусе прибора и приходится их убирать сзади прибора).
- кольцевой шлейф — обрыв шлейфа в одном месте не влияет на наличие сигналов от адресных датчиков;
- использование ответвительно-изолирующих блоков (БРИЗ) — позволяет делать радиальные ответвления, а также изолировать сегмент шлейфа, в котором произошло замыкание «ДПЛС+» и «ДПЛС-».
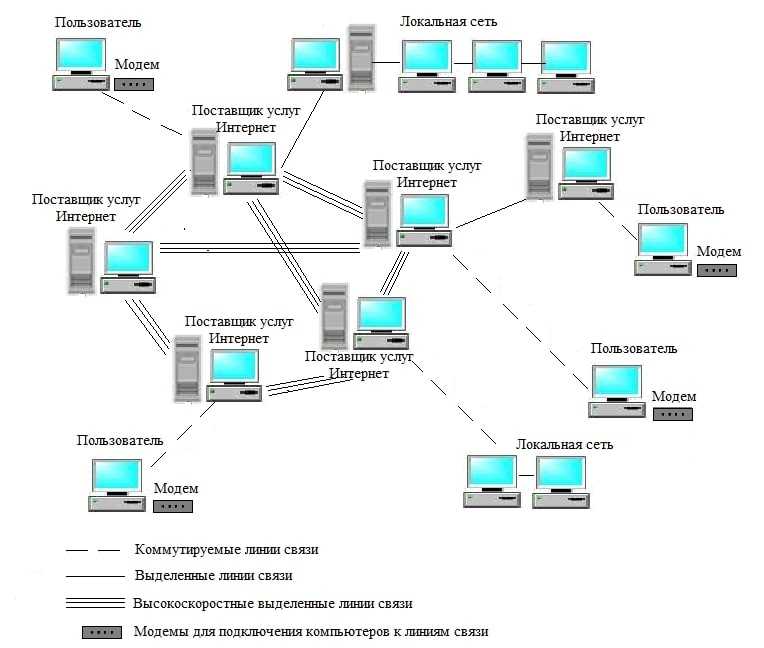
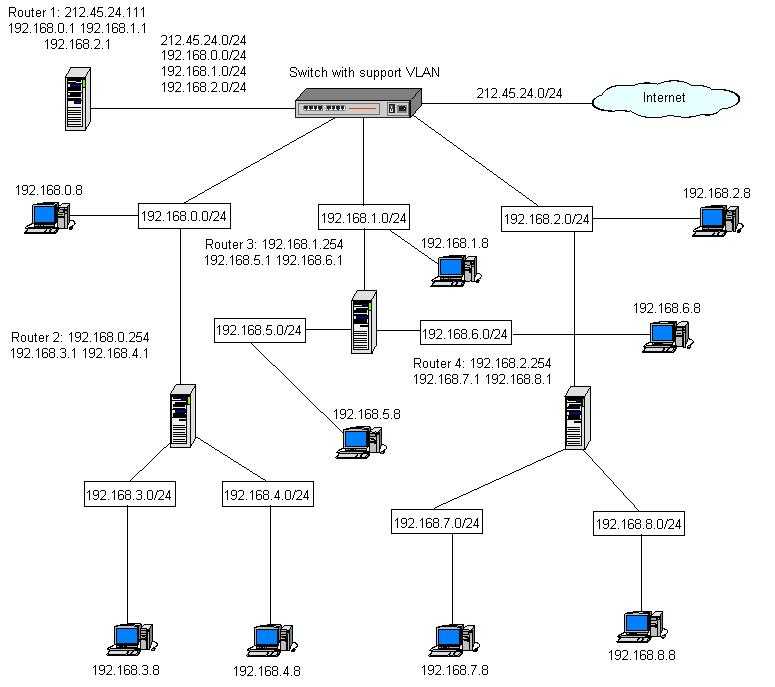
Мониторинг VoIP-сетей
В этой главе будут рассмотрены основные параметры сети, мониторинг которых должен осуществляться анализатором сетевого трафика в проводных и беспроводных VoIP-сетях (беспроводные VoIP-сети часто обозначаются аббревиатурами «VoWLAN» или «VoFi»).
Хотя цена и технические преимущества инфраструктуры VoIP находятся уровнем выше по сравнению с сетями POTN, конечных пользователей всегда привлекает высокое качество и надежность переговоров. Если пожертвовать качеством связи, многие пользователи не захотят перейти на новую технологию.








Во многих случаях, особенно когда используются локальные сети (LAN), сетевой администратор может относительно просто управлять качеством передаваемого голоса, контролируя такие параметры сети, как загрузка сети, уровни потери пакетов и задержки. Следовательно, помимо факторов, относящихся непосредственно к приложениям VoIP, сетевой анализатор должен быть способен регистрировать другие параметры работы сети и нагрузку на нее.
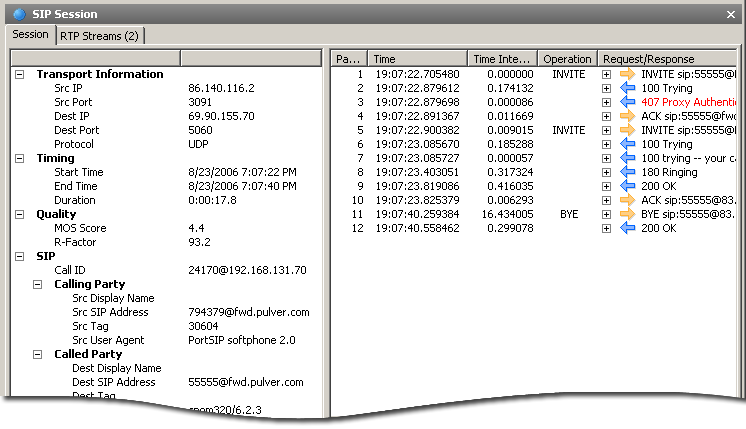
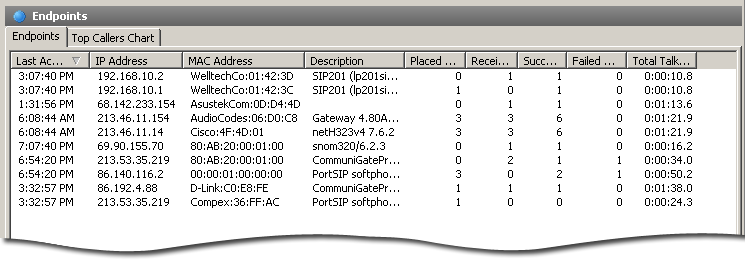
Статус текущих звонков
Сетевой анализатор может показывать состояние всех VoIP-звонков, по запросу выдавая дополнительную информацию по выбранному звонку. На следующих иллюстрациях приведены типичные данные, которые может показывать сетевой анализатор по каждому звонку.
Подробная информация о текущих звонках
Возможность просмотра детальной информации о текущих звонках позволяет идентифицировать и решить проблемы со связью на сетевом и протокольном уровнях. В детализацию звонка входят IP-адреса источника и точки назначения, время начала и окончания разговора, длительность разговора, статус звонка, показатели качества, названия VoIP-устройств пользователей, а также дополнительные данные, зависящие от протокола, такие как информация по аутентификации и типы кодеков.
Используя эти данные о звонках (проиллюстрированные ниже с помощью CommView), можно идентифицировать многие сетевые проблемы. Помимо высокоуровневой и статистической информации, показанной на панели слева, пользователь может увидеть низкоуровневый журнал с записями по сигнальной сессии на панели справа.
Загрузка сети
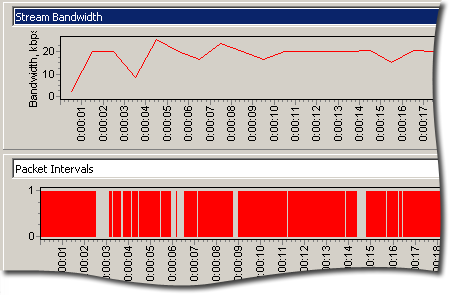 Необходимость мониторинга загрузки и контроля условий в сети является первостепенной для обеспечения ожидаемого качества звука в VoIP-системе. VoIP накладывает строгие ограничения на загрузку сети, что вынуждает постоянно следить за сетью при нормальной и максимальной нагрузках, по крайней мере на стадии внедрения и в процессе отладки качества звонков. Для понимания разницы между оптимальной средой передачи и той средой, которая существует в текущий момент времени, очень важна возможность оценить нагрузку на сеть в реальном времени. Зачастую такая оценка позволяет сетевым администраторам понять, что простой шейпинг трафика способен значительно повысить качество звонков, проходящих по сети.
Необходимость мониторинга загрузки и контроля условий в сети является первостепенной для обеспечения ожидаемого качества звука в VoIP-системе. VoIP накладывает строгие ограничения на загрузку сети, что вынуждает постоянно следить за сетью при нормальной и максимальной нагрузках, по крайней мере на стадии внедрения и в процессе отладки качества звонков. Для понимания разницы между оптимальной средой передачи и той средой, которая существует в текущий момент времени, очень важна возможность оценить нагрузку на сеть в реальном времени. Зачастую такая оценка позволяет сетевым администраторам понять, что простой шейпинг трафика способен значительно повысить качество звонков, проходящих по сети.
Загрузку сети можно наблюдать по графику «Stream bandwidth» (или «Полоса пропускания потока», если вы пользуетесь русским интерфейсом CommView), как показано на рисунке слева. Нерегулярный характер графика, резкие скачки и неравномерные интервалы между пакетами дают повод предположить, что текущие условия загрузки сети не дают VoIP-приложению возможности равномерно и надежно передавать голосовой поток.
Станции
Существует множество видов устройств конечного пользователя (станций) — программные IP-телефоны (софтфоны), обычные IP-телефоны, VoIP-адаптеры и шлюзы. Станции отвечают за инициацию, ведение и завершение разговора. В разнородных VoIP-сетях могут содержаться различные виды устройств с разной степенью совместимости как с VoIP-сервером, так и между собой. Это особенно справедливо для VoIP-сетей на базе SIP.
Сетевой анализатор определяет и отображает наименования устройств-станций, что позволяет отслеживать проблемы со связью и быстро их устранять простым апгрейдом ПО или прошивки без необходимости тщательного поиска и «инвентаризации» устройств сети.
Питание и монтаж
- большинство датчиков имеет небольшой кусочек торчащего кабеля. Нарастить кабель, можно применяя либо пайку с термоусадкой, либо двухпарную распачную коробку КС-2 (компактная, но качество изготовления «хромает»), либо соединение RJ11 (RJ45);
- перед монтажом в датчики нужно прописать их адреса (как это делается рассмотрено далее) и отмаркировать;
- при подключении датчиков нужно соблюдать полярность «ДПЛС+» и «ДПЛС-» (см. документацию — какой цвет имеет ДПЛС+, как правило цветной) — если перепутаете, то датчик не определится в системе.
- кабель витая пара 2-х парный, неэкранированнный;
- «мешок» разъемов RJ11 (6P4C или 6P6C);
- разветвители RJ11 со входами типа гнездо (бывают самые разнообразные варианты по очень симпатичным ценам).
Кто ведет наблюдение
Мониторинг сетевого оборудования, часто в рамках ИТ аутсорсинга, наряду со штатными системными администраторами проводят специализирующиеся в данном виде деятельности организации. При обслуживании клиентской компании должно быть осуществлено внедрение системы мониторинга сетевого оборудования. Поручать столь сложную и ответственную задачу следует профильным фирмам, обладающим достаточным опытом построения систем мониторинга разного масштаба, начиная от наблюдения за оборудованием небольших предприятий, которым необходимо быть уверенными в работоспособности внутренних сервисов, и заканчивая построением комплексных систем для контроля над корпоративной инфраструктурой.
От бесперебойной работы серверов и сопутствующего оборудования зачастую зависит и непрерывная работа всего предприятия в целом. Поэтому обслуживание ИТ инфраструктуры можно поручать только хорошо зарекомендовавшим себя в данной сфере компаниям. Применение специализированного программного обеспечения поможет организовать управление и контроль ИТ инфраструктуры на нужном для ее надежного функционирования уровне.
Подготовка
Без системы мониторинга поиск причины плохо работающего сервиса напоминает блуждание в темной комнате. Перед ее внедрением следует:
Осознать необходимость использования систем мониторинга
|
Логистическая компания мигрировала с одной платформы на другую, а в результате «пострадал» портал для заказа услуг. Клиенты оформляли контейнерные перевозки, но заказы слетали. Поиск проблемы зашел в тупик. Задействовано было несколько подрядчиков, и никто из них не брал на себя ответственность за случившееся. После внедрения системы мониторинга был разработан сценарий синтетических тестов, эмулирующих типовые действия пользователя на портале при заказе услуги, и информативный dashboard для вывода результатов тестов. Мы видели, как обрабатывался каждый шаг этого сценария, где он «зависал» – регулярно подтормаживала отправка данных в платежную систему. Так нам удалось сузить круг поиска проблемы. В итоге вскрылось несколько существенных изъянов, и заказчик потребовал от подрядчика доработать портал, предъявив объективные доказательства проблемы. Алексей Акопян, руководитель направления мониторинга «Инфосистемы Джет» |
Проанализировать процессы компании
Система строится от бизнес-сервиса, иначе она лишь фиксирует факт «пожара» на ограниченном участке, но не показывает причины и результатов сбоя.
| Отсутствие сервисного подхода – одна из самых критичных ошибок. Без него тот или иной компонент ИТ-инфраструктуры рассматривается сам по себе, в отрыве от бизнес-функции, которую он поддерживает, – поясняет Алексей Акопян. – Более действенно, если система мониторинга строится от бизнес-сервиса. Например, компания хочет понимать, как работает ее документооборот или финансовое приложение. Тогда, опираясь на структуру сервиса, система мониторинга «покрывает» компоненты ИТ-инфраструктуры, поддерживающее эти сервисы, отслеживает их доступность и качество. |
Разработать архитектуру
Оптимальное решение должно учитывать:
Геораспределенность инфраструктуры,
Количество и типы целевых объектов,
Число пользователей системы и их роли,
Объем, частоту сбора и длительность хранения входных данных.
При создании системы мониторинга используется золотое врачебное правило «Не навреди». Порой данные собираются с помощью специализированных агентов, устанавливаемых на объекты мониторинга
Важно контролировать дополнительную нагрузку, которую агенты оказывают на «поднадзорную» систему, их оптимальная настройка требует особого внимания, – подчеркивает Алексей Акопян. – У некоторых решений мониторинга есть встроенные механизмы защиты от перегрузки: агенты выключаются, если начинают потреблять больше ресурсов, чем определено лимитом.
Подготовить физическую инфраструктуру
Ошибка в этом может привести к тому, что львиная доля усилий потом будет посвящена оптимизации системы мониторинга, а не настройке ее функционала.
| В проектах часто мы имеем дело с оборудованием, которое не «умеет» отдавать данные для мониторинга по стандартным протоколам. Например, устаревшие телефонные станции или инженерное оборудование, – рассказывает Алексей Акопян. – Это требует доработки и иногда установки дополнительного оборудования: физических конвертеров или специализированных контроллеров. |
Подготовить системы сбора данных
Система мониторинга должна иметь широкие возможности по сбору данных: специализированные агенты, стандартный набор протоколов взаимодействия, открытый API
Особое внимание нужно обратить на тип базы данных для хранения данных мониторинга. База данных может быть:
классическая реляционная;
база данных временных рядов (по сути это ответ вендоров на все возрастающий объем обрабатываемых метрик);
их комбинация
| Самое главное – отказаться от практики «давайте мониторить все, собирать максимальное число метрик, а потом отсечем ненужное», – рекомендует Алексей Акопян. – Лучше изначально продумать, какая информация от мониторинга будет пригодна, а что только создаст шум. |
Представить структуру сервиса
Его можно разложить на компоненты и воплотить графически – приложения front-end, back-end, базы данных и пр.
Пример визуализации сервисной модели
Поставить триггеры
Желательно поставить триггеры на каждый из элементов и посмотреть, как компоненты влияют друг на друга
Это поможет понять взаимосвязь компонентов сервиса, и система сама будет определять важность того или иного события. Например, если упал веб-сервер, но он зарезервирован и в целом сервис не пострадал, то нет смысла генерировать инцидент с высоким приоритетом.
Каналы оповещения
- повсеместно распространенная технология,
- обладает достаточно высокой (но не абсолютной) гарантией доставки,
- позволяет принимать данные даже когда получатель не находится непосредственно на связи,
- позволяет сортировать сообщения по папкам различного смысла и приориета обработки.
Оценивая особенности применения jabber и SMS следует иметь в виду следующее обстоятельство:
Смысл данных каналов — в быстрой доставке сообщений, причем даже в ситуациях, когда получатель не находится у терминала (прием на мобильное устройство) и привлечение внимания путем подачи сигнала при поступлении сообщения.
Увы, в настоящий момент нет общепринятых средств, позволяющих дифференцировать вид сигнала в зависимости от содержимого принятого сообщения, поэтому распространение по данным каналам алертов важности ниже «H, D» будет неоправданным зашумлением
Датчики
ДПЛС
- С2000-ВТ — комбинированный датчик температуры и влажности для использования внутри помещений (IP41). Имеет сертификат средства измерения, погрешность всего 0,5°С и рекомендованную розничную цену всего 1200 руб.!
- С2000-СМК (и его вариации) — датчик «открытия двери» (магнито-контактный извещатель, геркон). Рекомендованная розничная цена — 300 руб.;
- С2000-ДЗ — точечный датчик затопления (делается совместно с Риэлта, поэтому корпус «неформат»). Рекомендованная розничная цена — 800 руб.;
- С2000-АР1, С2000-АР2, С2000-АР8 — адресные расширители на 1, 2 и 8 подключений, могут использоваться как «приемники» сигналов типа «сухой контакт» (вкл./откл.) с другого оборудования (например, с прибора пожаротушения или помпы кондиционера);
- С2000-СП2 — релейный блок (на 2 выхода), с помощью которого можно управлять устройствами (например, лампой сигнализации — световым индикатором). Рекомендованная розничная цена — 1200 руб.
официальном сайте производителя
Как подключить?
Для подключения услуги предусмотрено всего три шага:
- заявка на сайте;
- уточнение параметров;
- заключение договора.
Дальнейшая настройка также несложная. Администратор настраивает учетную запись и загружает необходимые задачи. В интерфейсе распределяются роли пользователей, подгружаются сотрудники и объекты. Эта работа производится автоматически, лишь в сложных случаях выполняется вручную.






Исполнителю остается принимать и исполнять назначенные задачи. По итогам выполнения формируются отчеты.
Администратор анализирует и контролирует полученные данные, выгружает отчеты из интерфейса. Принципы тарификации учитываются автоматически, по условиям подключенного пакета.
Подключение Modbus
- предпочтительный — преобразователь Modbus RTU/Modbus TCP с подключением к той же локальной сети, где находится наш сервер с ПО;
- дешевый — преобразователь RS-485/USB с подключением непосредственно к серверу. Отмечу, что есть много нареканий на надежность данных USB-стиков (можно брать практически любые, я заказывал из Китая за 100 рублей, использовал связку конвертер RS-232/RS-485 и переходник USB/RS-232 и все продолжало работать!).
- напрямую с С2000-ПП/C2000-КДЛ-Modbus, когда указанные устройства работают в режиме «Орион-Master» (выбирается перемычкой на плате) и выполняют роль опросчика системы «Орион»;
- с использованием пульта «С2000М», когда он собирает информацию с контроллеров и только потом отдает ее в Modbus через С2000-ПП/C2000-КДЛ-Modbus (режим «Орион-Slave»). Данная схема хороша тем, что пульт можно использовать как «локальный терминал» (посмотреть события на встроенном ЖК-экране), а также продолжать фиксировать события в случае поломки сервера с ПО мониторинга. Минус: чуть сложнее настройка и пульт имеет весьма специфичный внешний вид.
Рабочее место сотрудника клиентской службы
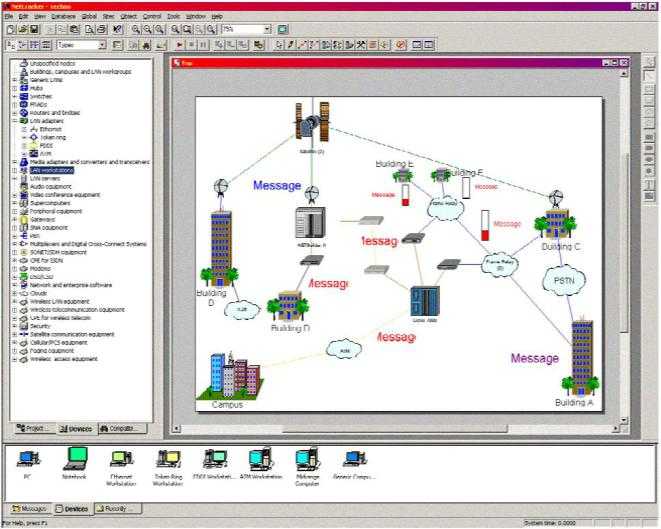
Интерфейс для оператора колл-центра, разработанный в компании Netcracker.
- Average handle time
- After call work
- First call resolution
- Learning curve и др.
Определение важности данных и частоты обращения к ним. Это повлияло на последовательность и расположение виджетов.
Обеспечение динамической компоновки данных в зависимости от контекста разговора
Наверх поднимаются виджеты, соответствующие текущему сценарию.
Применение подхода actionable analytics. Из всего множества данных мы делаем акцент на то, что связано с контекстом обращения клиента.
- На стартовом экране плотность данных гораздо выше. Оператор видит финансы, подключенные сервисы, немонетарные балансы, историю последних обращений.
- Многие параметры и элементы управления не имеют подписей, встречаются сокращения, применено цветовое кодирование.
- Подсказок и справочной информации мало. Большую часть оператор знает наизусть.
- Scripting — последовательность вопросов, которые оператор должен задать клиенту. Она зависит от сценария и часто меняется.
- Статусы продуктов, сервисов, объектов биллинга и процессинга. В личном кабинете клиент видит только малую часть этого.
- Показатели лояльности клиента, в том числе те, что пришли из социальных сетей.
- Up-sell/Cross-sell — анализ того, что клиент уже купил, чтобы продать ему дополнительные продукты и услуги.
- Next best action — сложная и объемная аналитика поведения клиента. Она анализирует то, с чем обратился клиент, и предугадывает, что может сделать его счастливее.
- Interaction Log — здесь фиксируют взаимодействие с клиентом. Описывают проблемы и их решения, создают заявки в back end, категоризируют обращения для последующего анализа статистики.
Различия в пользовательской и операторской системах обусловлены двумя причинами:
-
Разные требования к системе
У оператора и клиента разные навыки и сценарии взаимодействия с системой. Для клиента важны интуитивность (возможность быстро разобраться в интерфейсе) и удовлетворенность (впечатление от работы системы в целом). Для операторов же главное — производительность и скорость работы, т.е. возможность обработать обращение как можно быстрее, чтобы клиент остался доволен. -
Разные цели
Клиенту ни к чему помнить, когда и зачем он заходил в личный кабинет. Цель клиента — узнать об услугах. Цель компании — больше продать. Компания собирает и систематизирует обращения, чтобы предугадать, что еще можно предложить клиенту. Кроме того, компания заботится о том, как повысить лояльность клиента. Это напрямую влияет на то, будет ли клиент и дальше пользоваться услугами.
Преимущества перед проприетарными продуктами
Независимость от вендора в нештатных ситуациях. Ожидание новой версии проприетарного продукта может длиться месяцами, заказные доработки приводят к непредсказуемому поведению работывсего программного комплекса и росту ИТ-бюджета.
Модульная архитектура. Решение «Крок» разработано с учетом существующей рыночной ситуации и позволяет интегрироваться с любыми продуктами ведущих разработчиков. При этом заказчик может подобрать те функции, которые актуальны именно для него, и отказаться от ненужных.
Высокая кастомизация интерфейса. При использовании проприетарных систем заказчик подстраивается под преднастроенные индикаторы, зачастую не получая нужной ему детализации отображения.
Простая встройка в существующий ИТ-ландшафт. Проприетарные продукты могут не иметь необходимых заказчику инструментов для сбора данных. Это ставит под угрозу весь мониторинг как таковой и приводит к дополнительным расходам на доработку решения. При этом часть необходимой функциональности может остаться недоступной.
|
В случае использования решения «Крок» при сборе данных мы не ограничены в источниках или поддерживаемых технологиях — так как готовы к тому, что многие вещи нужно будет дорабатывать под заказчика. Мы изначально открыты к расширению функционала и включению в систему определенных, первоначально не поддерживаемых источников данных, — поясняет Валентин Нык. |
Выявление важных алертов
Ключ подхода к вопросу эффективного оповещения видится в том, чтобы определить набор алертов, которые должны вызывать безусловную реакцию персонала. Для этого необходимо:
Разделить контролируемую систему на жизненно важные сервисы.
Для каждого сервиcа определить как минимум одно или два критических состояния, которые должны обрабатываться безусловно:
сервис не работает;
сервис прекратит работу в течение 1 часа (возможны варианты, но не более 4 часов).
Алерты о данных состояниях должны доставляться как можно быстрее и обрабатываться незамедлительно.
Все имеющиеся алерты должны быть просеяны на однозначное соответствие двум упомянутым состояниям
Для несоответствующих критерию алертов уровень важности должен быть понижен.
Для критических алертов, выдающих flip-flop эффект из-за проблем со связью или способом измерения должны вводиться загрубляющие характеристики (вычисление среднего или задержка) до того уровня, когда безусловная реакция на них начнет иметь смысл. Если такое загрубление делает алерт бесполезным, следует от него отказаться и искать другой способ определения критического состояния.