
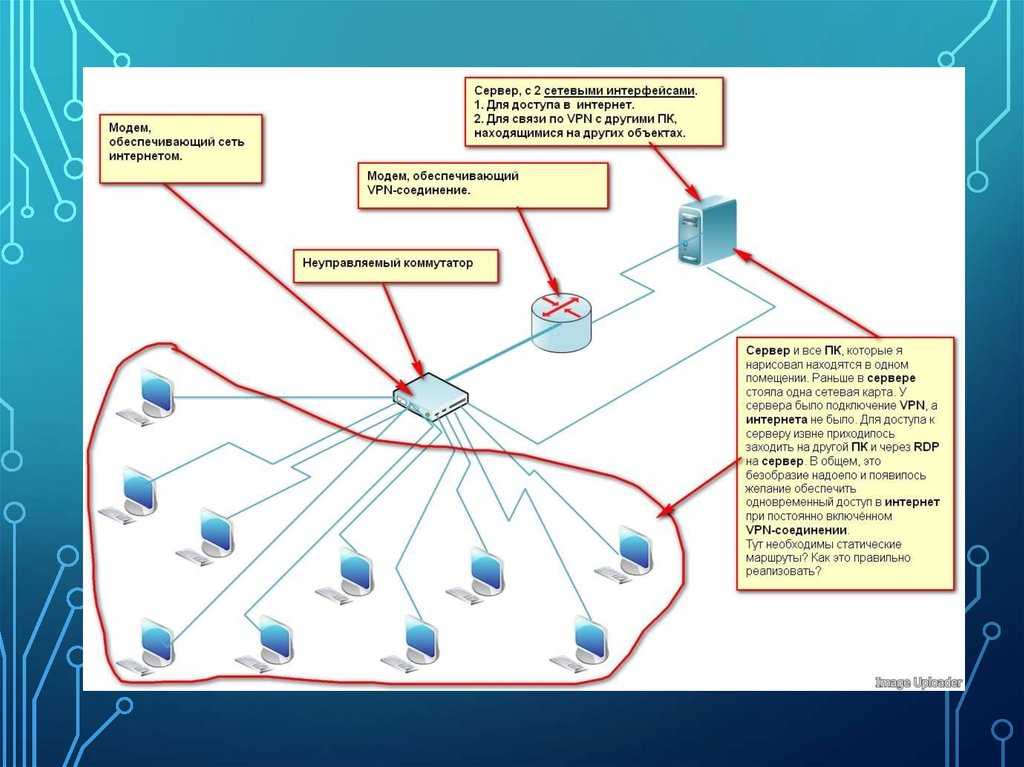
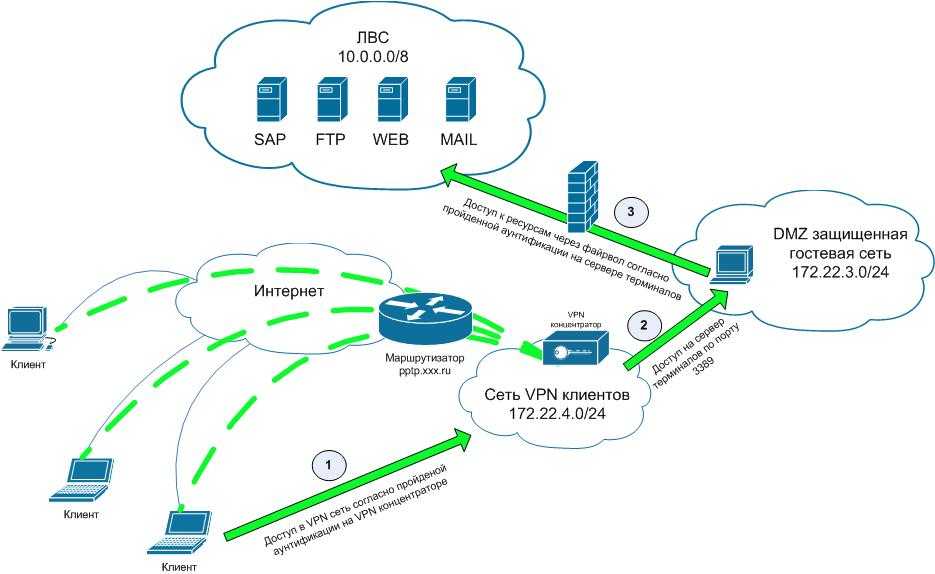
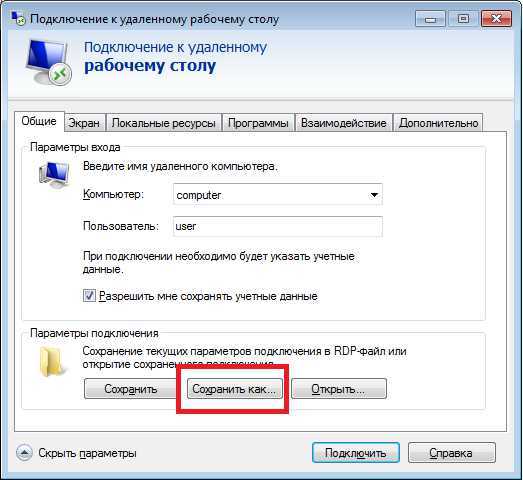
Шаг 4. Управление репликацией
Теперь можно приступить к управлению инфраструктурой межсерверной репликации и ее использованию. вы можете выполнить все приведенные ниже действия на узлах непосредственно или на удаленном компьютере управления, содержащем средства удаленного администрирования сервера Windows Server.
-
Используйте и , чтобы узнать источник и назначение репликации и их текущее состояние.
-
Для измерения производительности репликации выполните командлет на исходном и конечном узлах. Ниже перечислены имена счетчиков.
-
\Статистика ввода-вывода раздела реплики хранилища(*)\Количество раз приостановки записи на диск
-
\Статистика ввода-вывода раздела реплики хранилища(*)\Количество вводов-выводов записи на диск в ожидании
-
\Статистика ввода-вывода раздела реплики хранилища(*)\Количество запросов для последней записи в журнал
-
\Статистика ввода-вывода раздела реплики хранилища(*)\Средняя длина очереди записи на диск
-
\Статистика ввода-вывода раздела реплики хранилища(*)\Текущая длина очереди записи на диск
-
\Статистика ввода-вывода раздела реплики хранилища(*)\Количество запросов записи приложения
-
\Статистика ввода-вывода раздела реплики хранилища(*)\Среднее число запросов в операции записи в журнал
-
\Статистика ввода-вывода раздела реплики хранилища(*)\Средняя задержка записи приложения
-
\Статистика ввода-вывода раздела реплики хранилища(*)\Средняя задержка чтения приложения
-
\Статистика реплики хранилища(*)\Целевая RPO
-
\Статистика реплики хранилища(*)\Текущая RPO
-
\Статистика реплики хранилища(*)\Средняя длина очереди журнала
-
\Статистика реплики хранилища(*)\Длина очереди текущего журнала
-
\Статистика реплики хранилища(*)\Всего байт получено
-
\Статистика реплики хранилища(*)\Всего байт отправлено
-
\Статистика реплики хранилища(*)\Средняя время задержки исходящих данных в сети
-
\Статистика реплики хранилища(*)\Состояние репликации
-
\Статистика реплики хранилища(*)\Средняя задержка приема-передачи сообщения
-
\Статистика реплики хранилища(*)\Время, затраченное на последнее восстановление
-
\Статистика реплики хранилища(*)\Количество транзакций восстановления, записанных на диск
-
\Статистика реплики хранилища(*)\Количество транзакций восстановления
-
\Статистика реплики хранилища(*)\Количество транзакций репликации, записанных на диск
-
\Статистика реплики хранилища(*)\Количество транзакций репликации
-
\Статистика реплики хранилища(*)\Максимальный порядковый номер журнала
-
\Статистика реплики хранилища(*)\Количество полученных сообщений
-
\Статистика реплики хранилища(*)\Количество отправленных сообщений
Дополнительные сведения о счетчиках производительности, доступных в Windows PowerShell, см. в статье Get-Counter.
-
-
Чтобы изменить направление репликации из одного расположения, используйте командлет .
Предупреждение
Windows Сервер предотвращает переключение ролей при выполнении начальной синхронизации, так как это может привести к утрате данных при попытке переключения перед выполнением начальной репликации. Не принудительно переключайтейте направления, пока не завершится начальная синхронизация.
Проверьте журналы событий и убедитесь, что направление репликации изменено и режим восстановления установлен, а затем выполните согласование. Теперь операции записи смогут использовать хранилище, принадлежащее новому исходному серверу. Изменение направления репликации блокирует операции записи на компьютере, который ранее был исходным.
-
Чтобы удалить репликацию, выполните , , и на каждом узле. Командлет следует выполнять только на том узле, который сейчас является источником репликации, но не на целевом сервере. Выполните на обоих серверах. Например, вот как можно удалить репликацию на двух серверах:
![Fc подключение к схд сервера под linux [colobridge wiki]](https://tehnikaarenda.ru/wp-content/uploads/7/4/2/74210cb4903058e6d9a9a98f7c1d97c1.jpeg)
![Iscsi подключение к схд сервера под windows [colobridge wiki]](https://tehnikaarenda.ru/wp-content/uploads/2/c/d/2cd3a0e5a7fa5dbb60c5dc86109789a2.jpeg)
Настройка виртуального адаптера Fibre Channel Hyper-V в структуре хранилища VMM Set up Hyper-V virtual fibre channel in the VMM storage fabric
В этой статье описывается настройка виртуального адаптера Fibre Channel Hyper-V в структуре хранилища System Center Virtual Machine Manager (VMM). Read this article to set up Hyper-V virtual fibre channel in the System Center — Virtual Machine Manager (VMM) storage fabric.
Виртуальный адаптер Fibre Channel позволяет виртуальным машинам Hyper-V напрямую подключаться к хранилищу на основе Fibre Channel. Virtual fibre channel provides Hyper-V VMs with direct connectivity to fibre channel-based storage. Hyper-V предоставляет порты Fibre Channel в операционных системах на виртуальных машинах, что позволяет виртуализировать приложения и рабочие нагрузки, которые имеют зависимости от хранилища Fibre Channel. Hyper-V provides fibre channel ports within guest operating systems, so that you can virtualize applications and workloads that have dependencies on fibre channel storage. Кроме того, можно кластеризовать операционные системы на виртуальных машинах по Fibre Channel. You can also cluster guest operating systems over fibre channel.
SAN (сеть хранения)
Сегодняшние приложения очень ресурсоемкие, из-за запросов, которые необходимо обрабатывать одновременно в секунду. Возьмите пример веб-сайта электронной коммерции, где тысячи людей делают заказы в секунду, и все они должны быть правильно сохранены в базе данных для последующего поиска. Технология хранения, используемая для хранения таких баз данных с высоким трафиком, должна быть быстрой в обслуживании и ответе запросов (вкратце, это должно быть быстрым на входе и выходе).
В таких случаях (когда вам нужна высокая производительность и быстрый ввод-вывод), мы можем использовать SAN.
Традиционно серверы приложений использовали свои собственные устройства хранения, прикрепленные к ним. Разговор с этими устройствами с помощью протокола, известного как SCSI (Small Computer System Interface). SCSI — это не что иное, как стандарт, используемый для связи между серверами и устройствами хранения. Все обычные жесткие диски, ленточные накопители и т.д. Используют SCSI. Вначале требования к хранилищу сервера выполнялись устройствами хранения, которые были включены внутри сервера (сервер, используемый для разговора с этим внутренним устройством хранения данных, используя SCSI. Это очень похоже на то, как обычный рабочий стол разговаривает с его внутренним жесткий диск.).
Такие устройства, как компакт-диски, подключаются к серверу (который является частью сервера) с использованием SCSI. Основным преимуществом SCSI для подключения устройств к серверу была его высокая пропускная способность. Хотя этой архитектуры достаточно для низких требований, существует несколько ограничений, таких как приведенные ниже.
- Сервер может получать доступ только к данным на устройствах, которые непосредственно привязаны к нему. Если что-то случится с сервером, доступ к данным завершится неудачно (поскольку устройство хранения является частью сервера и подключено к нему с использованием SCSI)
- Ограничение количества устройств хранения, к которым может получить доступ сервер. В случае, если серверу требуется больше места для хранения, не будет больше места, которое можно подключить, поскольку шина SCSI может вместить только конечное число устройств.
- Кроме того, сервер, использующий хранилище SCSI, должен находиться рядом с устройством хранения (поскольку параллельный SCSI, который является обычной реализацией на большинстве компьютеров и серверов, имеет некоторые ограничения на расстояние, он может работать до 25 метров).
Некоторые из этих ограничений можно преодолеть с помощью DAS (непосредственно привязанного хранилища). Смарт, используемый для прямого подключения хранилища к серверу, может быть любым из каналов SCSI, Ethernet, Fiber и т. Д.). Низкая сложность, низкие инвестиции, простота в развертывании привела к тому, что DAS были приняты многими для нормальных требований. Решение было хорошим даже с точки зрения производительности, если оно используется с более быстрыми средами, такими как волоконный канал.
Примером устройства хранения данных DAS является MD1220 от Dell.
Хотя DAS хорош для нормальных потребностей и дает хорошую производительность, существуют такие ограничения, как количество серверов, которые могут получить к нему доступ. Храните устройство или скажем, что хранилище DAS должно находиться рядом с сервером (в той же стойке или в пределах допустимого расстояния используемого носителя).
Можно утверждать, что непосредственно прикрепленное хранилище (DAS) работает быстрее, чем любые другие методы хранения. Это связано с тем, что он не связан с некоторыми издержками передачи данных по сети (вся передача данных происходит на выделенном соединении между сервером и устройством хранения. В основном его последовательно подключен SCSI или SAS). Однако из-за последних улучшений в волоконном канале и других механизмах кэширования SAN также обеспечивает лучшую скорость, подобную DAS, и в некоторых случаях превосходит скорость, предоставляемую DAS.
Прежде чем войти в SAN, давайте разобраться в нескольких типах и методах мультимедиа, которые используются для соединения устройств хранения данных (когда я говорю о устройствах хранения данных, пожалуйста, не рассматривайте его как один жесткий диск. Возьмите его как массив дисков, возможно, на каком-то уровне RAID. Считайте это чем-то вроде Dell MD1200).
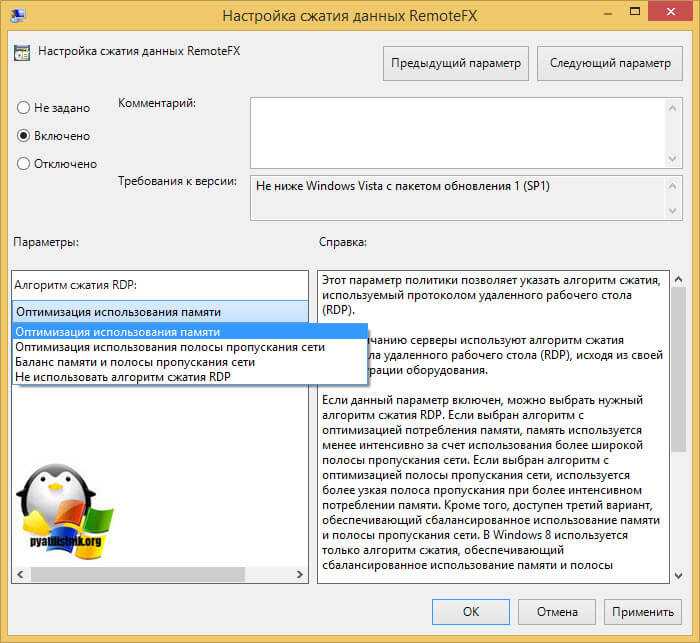
Режим совместимости конфигурации 1С
Приветствую, коллеги! В этой статье будет сделан обзор функции совместимости конфигурации 1С с другими версиями конфигураций 1С, а также рассмотрено, как выбрать и настроить режим совместимости конфигурации с версией 1С 8.3.
Во-первых, разберём главное понятие в этой статье: режим совместимости в конфигурации – это устройство, благодаря которому выводится номер версии системы, под которую станет открыто приложение 1С:Предприятие. Данный режим существует на платформе 1С начиная с версий 8.2 и 8.3 (платформа версии 1С:Предприятие 8.3 совместима с платформой версии 1С:Предприятие 8.2).
Развертывание сетей хранения данных с отказоустойчивыми кластерами
При развертывании сети хранения данных (SAN) с отказоустойчивым кластером руководствуйтесь следующими рекомендациями.
Подтвердите совместимость хранилища. Обратитесь к производителям и поставщикам, чтобы подтвердить, что хранилище, включая драйверы, встроенное ПО и ПО, используемое для хранилища, совместимо с отказоустойчивыми кластерами в используемой версии Windows Server.
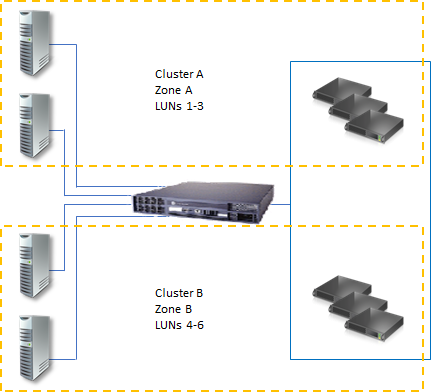
Изолируйте запоминающие устройства по одному кластеру на устройство: серверы из различных кластеров не должны иметь доступа к одним и тем же запоминающим устройствам. В большинстве случаев LUN, используемый для одного набора серверов кластера, должен быть изолирован от всех остальных серверов с помощью маски или зонирования LUN.
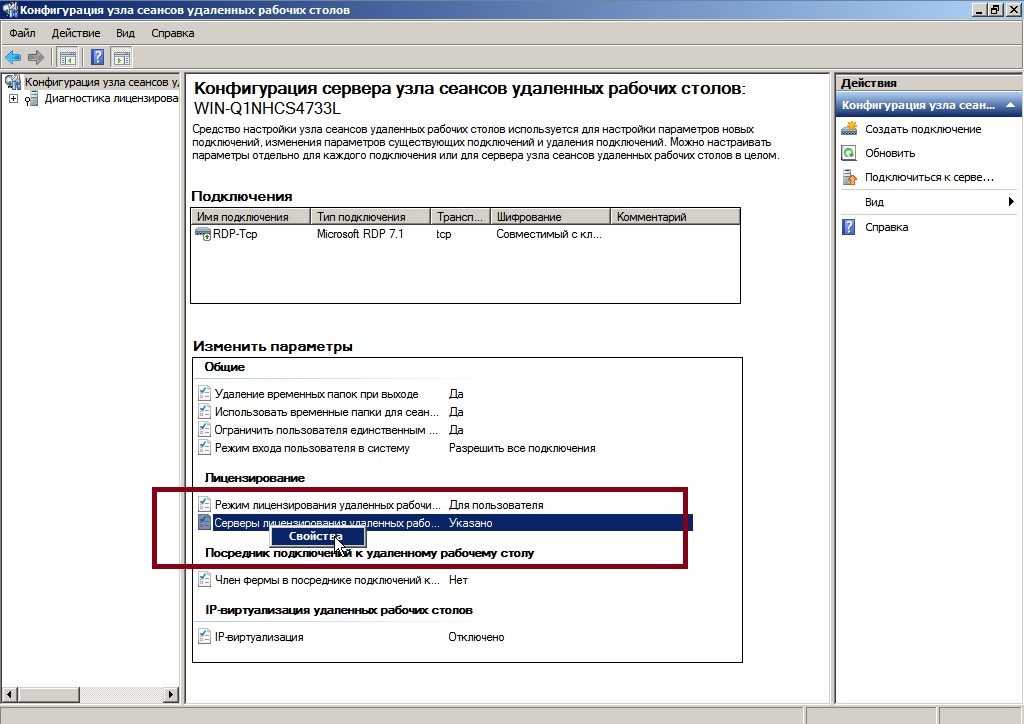
Рассмотрите использование ПО многоканального ввода-вывода или сетевых адаптеров с поддержкой совместной работы: в архитектуре хранилищ с высокой доступностью можно развернуть отказоустойчивые кластеры с несколькими адаптерами шины, используя ПО многоканального ввода-вывода или сетевых адаптеров с поддержкой совместной работы (что также называется отказоустойчивой балансировкой нагрузки — LBFO). Это обеспечивает максимальный уровень резервирования и доступности. для Windows Server 2012 R2 или Windows Server 2012 решение multipath должно быть основано на Microsoft Multipath I/O (MPIO). Поставщики оборудования обычно предоставляют модуль MPIO для конкретного устройства (DSM), но в комплект поставки операционной системы Windows Server также входят один или несколько модулей DSM.
дополнительные сведения о LBFO см
в статье обзор объединения сетевых карт в технической библиотеке Windows Server.
Важно!
Некоторые адаптеры шины и программное обеспечение многоканального ввода-вывода сильно зависят от версий. При реализации многоканального решения для кластера следует проконсультироваться с поставщиком оборудования, чтобы выбрать правильные адаптеры, встроенное программное обеспечение и программное обеспечение для используемой версии Windows Server.
рассмотрите возможность использования дисковые пространства
если планируется развертывание кластеризованного хранилища serial attached SCSI (SAS), настроенного с помощью дисковые пространства, см. раздел развертывание кластерных дисковые пространства для требований.
Облака и эфемерные хранилища
Логическим продолжением перехода на виртуализацию является запуск сервисов в облаках. В предельном случае сервисы разбиваются на функции, запускаемые по требованию (бессерверные вычисления, serverless)
Важной особенностью тут является отсутствие состояния, то есть сервисы запускаются по требованию и потенциально могут быть запущены столько экземпляров приложения, сколько требуется для текущей нагрузки. Большинство поставщиков (GCP, Azure, Amazon и прочие) облачных решений предлагают также и доступ к хранилищам, включая файловые и блочные, а также объектные
Некоторые предлагают дополнительно облачные базы, так что приложение, рассчитанное на запуск в таком облаке, легко может работать с подобными системами хранения данных. Для того, чтобы все работало, достаточно оплатить вовремя эти услуги, для небольших приложений поставщики вообще предлагают бесплатное использование ресурсов в течение некоторого срока, либо вообще навсегда.
Из недостатков: могут заблокировать аккаунт, на котором все работает, что может привести к простоям в работе. Также могут быть проблемы со связностью и\или доступностью таких сервисов по сети, поскольку такие хранилища полностью зависят от корректной и правильной работы глобальной сети.
![Fc подключение к схд сервера под windows [colobridge wiki]](https://tehnikaarenda.ru/wp-content/uploads/5/7/7/5773a9e7913564a29f34f5ee575057aa.jpeg)
Создание нового раздела
С:
- В окне Диспетчера серверов откройте расположенное в верхней части меню «Средстива», а в нем — «Управление компьютером».
- В открывшемся окне выберите в левой панели оснастку «Управление дисками». Вы увидите единственный диск, на котором расположена операционная система.
- Щелкните на диске правой клавишей мыши и выберите «Сжать том». При общем объеме диска в 40 Гбайт в поле «Размер сжимаемого пространства, Мб» я прописал значение 25 000, посчитав, что для работы винде хватит 15 Гбайт дискового пространства.
- Щелкните мышью на кнопке «Сжать», и дожидитесь, пока Windows освободит место на диске.
- Щелкните правой клавишей мыши в нераспределенной области, и в контекстном меню выберите пункт «Создать простой том»;
- В окне «Мастера создания простого тома» нажмите «Далее», убедитесь, что размер тома соответствует объему неразмеченной области, снова нажмите «Далее».
- Введите букву диска (по умолчанию «D:») и опять нажмите «Далее».
- Выберите в качестве файловой системы NTFS, размер кластера — «по умолчанию», установите флажок «Быстрое форматирование». Остальные параметры можно оставить без изменений. Нажмите «Далее». Затем щелкните мышью на кнопке «Готово».
D:
Траблшутинг
\\ip-адрес-нашего-сервера
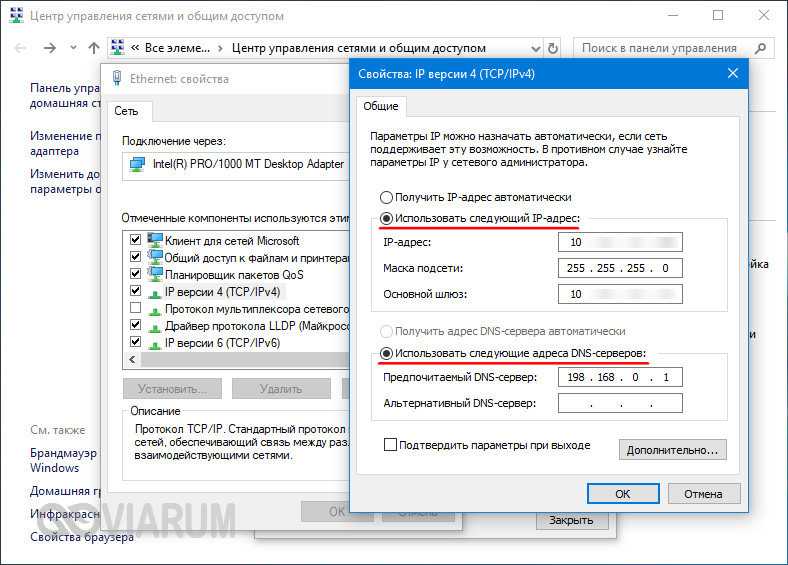
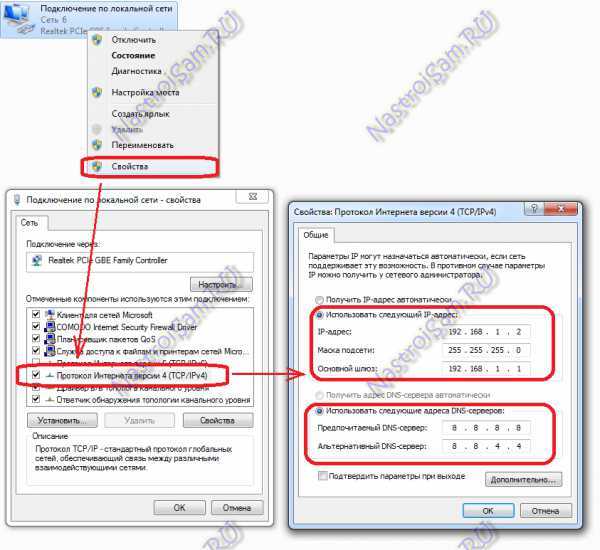
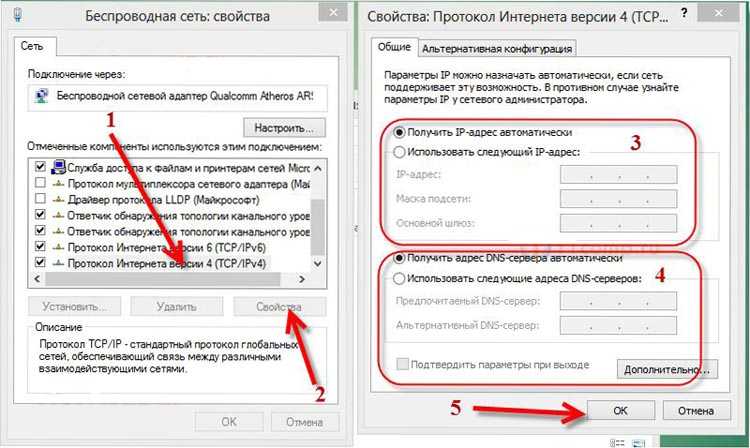
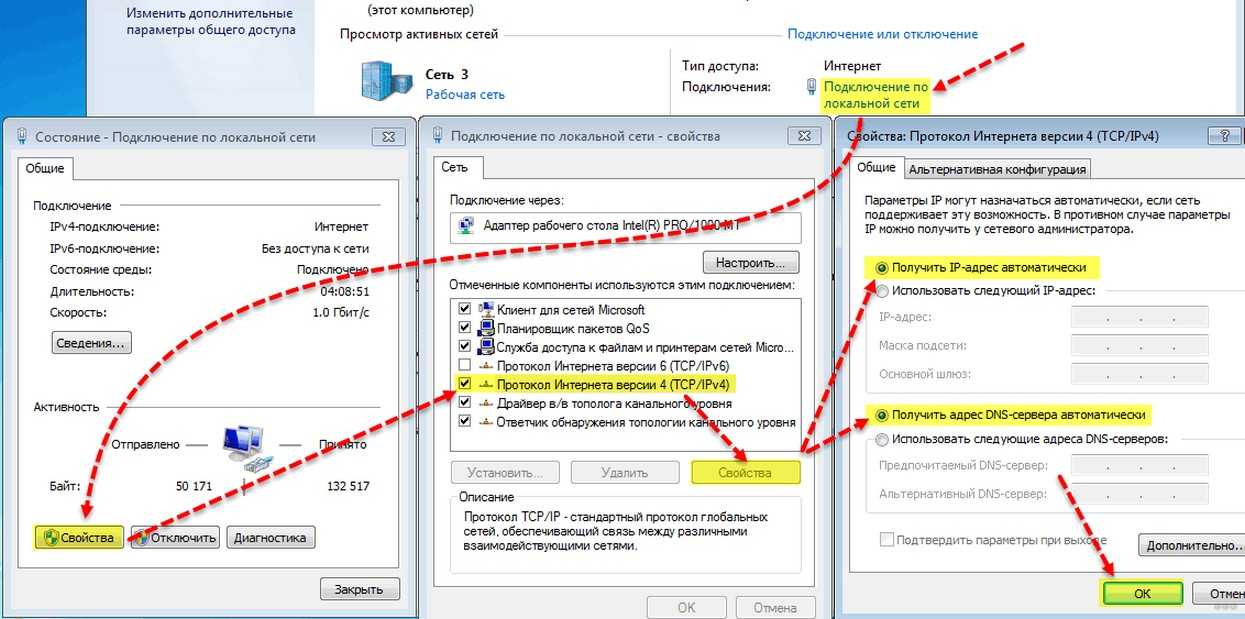
- Вновь подключаемся к серверу по RDP, щелкаем правой кнопкой мыши на значке подключения к сети в трее и выбираем в контекстном меню «Открыть Параметры сети и интернет».
- В открывшемся окне проматываем содержимое вниз и жмем на надпись «Центр управления сетями и общим доступом».
- В расположенной слева панели жмем на надпись «Изменить дополнительные параметры общего доступа».
- Устанавливаем переключатель в положение «Включить сетевое обнаружение».
- Переходим в раздел «Все сети» чуть ниже, устанавливаем переключатель в положение «Включить общий доступ, чтобы сетевые пользователи могли читать и записывать файлы в общих папках».
- Жмем «Сохранить изменения».
services.msc
- DNS-клиент (DNS Client)
- Обнаружение SSDP (SSDP Discovery)
- Публикация ресурсов обнаружения функции (Function Discovery Resource Publication)
- Узел универсальных PNP-устройств (UPnP Device Host)
- На своей рабочей машине откройте Проводник, щелкните правой клавишей мыши на значке «Этот компьютер» и выберите в контекстном меню пункт «Подключить сетевой диск».
- В открывшемся окне выберите букву сетевого диска, в поле «Папка» введите IP-адрес сервера и сетевое имя общей папки, установите флажки «Восстанавливать подключение при входе в систему» и «использовать другие учетные данные».
- Нажмите на кнопку «Готово».
Создание и развертывание уровня службы Create and deploy a service tier
- С помощью конструктора шаблонов службсоздайте шаблон службы и добавьте подходящие шаблоны виртуальных машин, предварительно созданных для шаблона службы. Using the Service Template Designer, create a service template and add the applicable VM templates you previously created to the service template.
- Добавьте новый виртуальный адаптер Fibre Channel (виртуальный адаптер шины) на странице Настройка оборудования шаблона службы. Add a new virtual fibre channel adapter (vHBA) to the Configure Hardware page of the service template. Для каждого созданного виртуального адаптера шины укажите динамические или статические назначения портов WWPN и выберите классификацию структуры. For each vHBA that you create, specify dynamic or static WWPN port assignments and select the fabric classification.
- Из шаблона службы создайте уровень службы и назначьте его уровню компьютера. Create service tier from the service template and assign the service tier to a computer tier.
- Разверните уровень. Deploy the tier.
- После его развертывания на узле можно соотнести зоны массива хранения данных виртуального адаптера Fibre Channel с уровнем службы. After you deploy it, you can zone a virtual fibre channel storage array to the service tier. Затем создайте LUN для массива и зарегистрируйте его (снимите маску) на нужном уровне. Then create a LUN for the array and register (unmask) it to the tier.
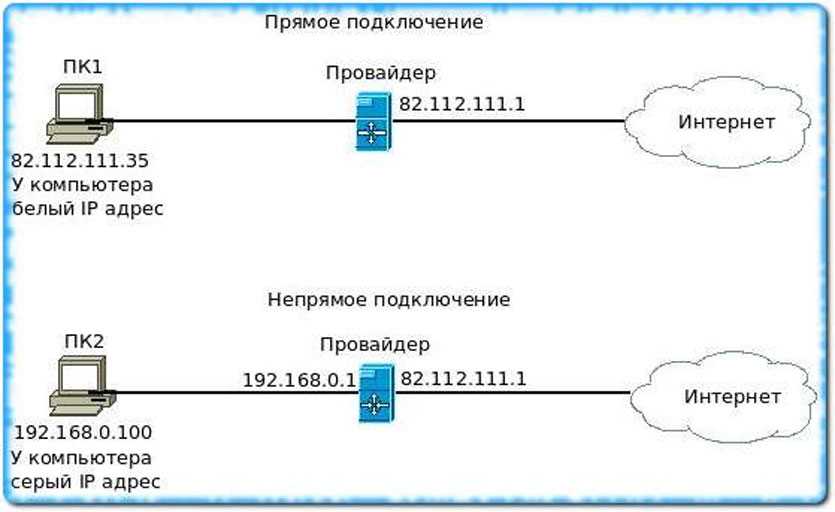
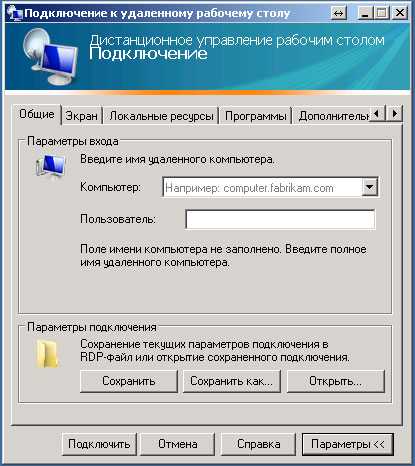
Соединение с компонентом Database Engine с другого компьютера
После настройки компонента Компонент Database Engine на прослушивание определенного порта и открытия порта в брандмауэре можно подключиться к SQL Server с другого компьютера.
Если служба браузера SQL Server на сервере запущена и в брандмауэре открыт порт UDP 1434, то подключение можно установить, используя имя компьютера и имя экземпляра. В целях повышения безопасности в нашем примере не используется служба браузера SQL Server .
Соединение с ядром СУБД с другого компьютера
-
На втором компьютере, содержащем клиентские средства SQL Server , войдите под учетной записью, для которой разрешено подключение к SQL Server, и откройте среду Среда Management Studio.
-
В диалоговом окне Соединение с сервером выберите Компонент Database Engine в списке Тип сервера .
-
В поле Имя сервера введите tcp: , чтобы указать протокол, за которым должны следовать имя компьютера, запятая и номер порта. При подключении к экземпляру по умолчанию подразумевается номер порта 1433. Этот номер можно опустить, поэтому введите tcp: <имя_компьютера> . В этом примере для именованного экземпляра введите tcp: <имя_компьютера> ,49172.
Примечание
Если не указать tcp: в поле Имя сервера , то клиент попытается использовать все включенные протоколы в порядке, указанном в конфигурации клиента.
-
В поле Проверка подлинности подтвердите значение Проверка подлинности Window, а затем нажмите Подключиться.
Новые архитектуры хранилищ данных
Panoply
- Анализ запросов и данных — определение наилучшей конфигурации для каждого варианта использования, корректировка ее с течением времени и создание индексов, сортировочных ключей, дисковых ключей, типов данных, вакуумирование и разбиение.
- Идентификация запросов, которые не следуют передовым методам — например, те, которые включают вложенные циклы или неявное приведение — и переписывает их в эквивалентный запрос, требующий доли времени выполнения или ресурсов.
- Оптимизация конфигурации сервера с течением времени на основе шаблонов запросов и изучения того, какая настройка сервера работает лучше всего. Платформа плавно переключает типы серверов и измеряет итоговую производительность.
По ту сторону облачных хранилищ данных
Загрузка данных в облачные хранилища данных нетривиальна, а для крупномасштабных конвейеров данных требуется настройка, тестирование и поддержка процесса ETL
Эта часть процесса обычно выполняется сторонними инструментами;
Обновления, вставки и удаления могут быть сложными и должны выполняться осторожно, чтобы не допустить снижения производительности запросов;
С полуструктурированными данными трудно иметь дело — их необходимо нормализовать в формате реляционной базы данных, что требует автоматизации больших потоков данных;
Вложенные структуры обычно не поддерживаются в облачных хранилищах данных. Вам необходимо преобразовать вложенные таблицы в форматы, понятные хранилищу данных;
Оптимизация кластера
Существуют различные варианты настройки кластера Redshift для запуска ваших рабочих нагрузок. Различные рабочие нагрузки, наборы данных или даже различные типы запросов могут потребовать иной настройки. Для достижения оптимальной работы, необходимо постоянно пересматривать и при необходимости дополнительно настраивать конфигурацию;
Оптимизация запросов — пользовательские запросы могут не соответствовать передовым методам и, следовательно, будут выполняться намного дольше. Вы можете работать с пользователями или автоматизированными клиентскими приложениями для оптимизации запросов, чтобы хранилище данных могло работать так, как ожидалось
Резервное копирование и восстановление — несмотря на то, что поставщики хранилищ данных предоставляют множество возможностей для резервного копирования ваших данных, их нетривиально настроить и они требуют мониторинга и пристального внимания
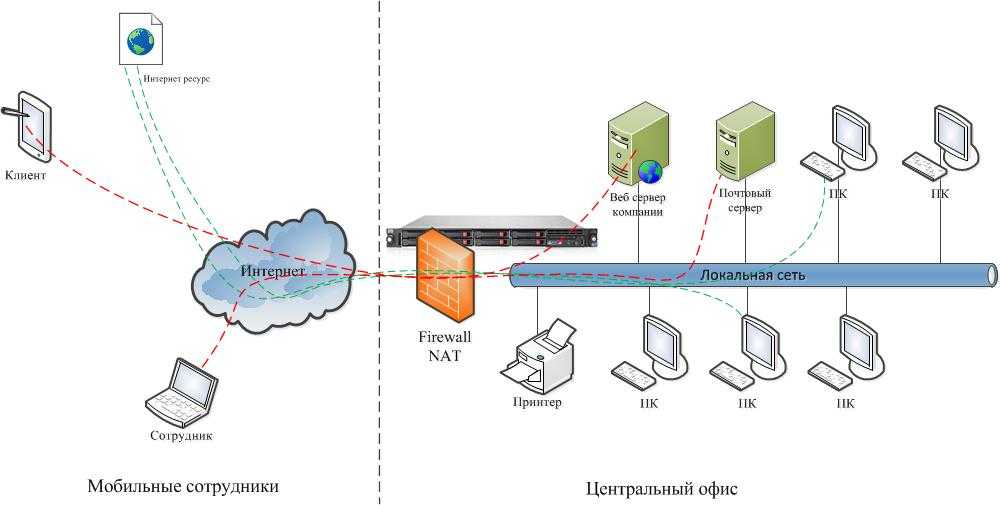
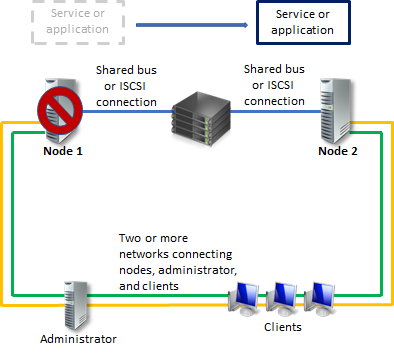
Общие сведения о кластере файлового сервера с двумя узлами
Серверы в отказоустойчивом кластере могут работать в различных ролях, включая роли файлового сервера, сервера Hyper-V или сервера базы данных, а также обеспечивают высокий уровень доступности для различных служб и приложений. В этом руководство описано, как настроить кластер файлового сервера с двумя узлами.
Отказоустойчивый кластер обычно включает в себя единицу хранения, которая физически подключена ко всем серверам в кластере, хотя каждый заданный том в хранилище доступен только одному серверу за раз. На следующей схеме показан отказоустойчивый кластер с двумя узлами, подключенный к единице хранения.
служба хранилища тома или номера логических устройств (lun), предоставляемые узлам в кластере, не должны предоставляться другим серверам, включая серверы в другом кластере. Это показано на схеме ниже.
Обратите внимание, что для обеспечения максимальной доступности любого сервера важно следовать рекомендациям по управлению сервером, например, тщательному управлению физической средой серверов, тестированию изменений программного обеспечения перед их полным внедрением и тщательно отслеживать обновления программного обеспечения и изменения конфигурации на всех кластеризованных серверах. В следующем сценарии описано, как можно настроить отказоустойчивый кластер файлового сервера. Общие файлы находятся в хранилище кластера, а кластеризованный сервер может работать как файловый сервер, который их использует
Общие файлы находятся в хранилище кластера, а кластеризованный сервер может работать как файловый сервер, который их использует
В следующем сценарии описано, как можно настроить отказоустойчивый кластер файлового сервера. Общие файлы находятся в хранилище кластера, а кластеризованный сервер может работать как файловый сервер, который их использует.
![Iscsi подключение к схд сервера под windows [colobridge wiki]](https://tehnikaarenda.ru/wp-content/uploads/d/6/a/d6ab9ea3eb5526f56366cd40178a1c28.jpeg)
![Fc подключение к схд сервера под windows [colobridge wiki]](https://tehnikaarenda.ru/wp-content/uploads/1/8/9/189f1be485b4a7c58d3ec50aeb8ff27f.jpeg)
Технология разветвленной разработки конфигураций 1С
Вся групповая разработка любой организации, где работает более 2-х программистов, в превосходящем большинстве случаев строится вокруг хранилища конфигурации.
Те из нас, кто обращался к стандартам разработки 1С как минимум раз в жизни и читал их полностью (а может, и просто слышал от коллег), наверняка знают, что существует «Технология разветвленной разработки конфигураций» https://its.1c.ru/db/v8std#content:709:hdoc но не все поняли, как на самом деле эту замечательную вещь применять на практике, а кто-то понял и вероятнее всего думает, что «это к нам не относится, командная разработка по такой технологии в нашей организации не получится в силу определённых причин и потому применять её, к сожалению, я один не могу и не буду», до конца не разобравшись во всех аспектах, но это ошибочное мнение. В этой статье я постараюсь описать свой опыт, рассказать о преимуществах использования данной технологии, дать понять, что технология разветвленной разработки конфигураций на самом деле вещь индивидуальная и каждый для себя решает сам, применять её или нет, а также внести понимание, что у вас вообще нет никакой зависимости от своих коллег, работая в хранилище конфигурации при использовании этой технологии.
Открытие портов в брандмауэре
Системы брандмауэров предотвращают несанкционированный доступ к ресурсам компьютера. Для подключения к SQL Server с другого компьютера при включенном брандмауэре в брандмауэре необходимо открыть порт.
Важно!
Открытие портов на брандмауэре может привести к незащищенности сервера от вредоносных атак. Поэтому для открытия портов требуется понимание работы систем брандмауэров. Дополнительные сведения см. в разделе Security Considerations for a SQL Server Installation.
После настройки компонента Компонент Database Engine на использование фиксированного порта следуйте приведенным ниже инструкциям, чтобы открыть в брандмауэре Windows нужный порт. (Нет необходимости настраивать фиксированный порт для экземпляра по умолчанию, потому что он уже настроен на подключение к TCP-порту 1433.)
Открытие порта в брандмауэре Windows для доступа по TCP (Windows 7)
-
В меню Пуск выберите команду Выполнить, введите WF.mscи нажмите кнопку ОК.
-
На левой панели Брандмауэр Windows в режиме повышенной безопасностищелкните правой кнопкой мыши раздел Правила для входящих подключенийи выберите на панели действий пункт Создать правило .
-
В диалоговом окне Тип правила выберите Порти нажмите кнопку Далее.
-
В диалоговом окне Протокол и порты выберите протокол TCP. Выберите Определенные локальные портыи введите номер порта экземпляра компонента Компонент Database Engine. Для экземпляра по умолчанию введите 1433. Если в предыдущей задаче был настроен фиксированный порт, а сейчас настраивается именованный экземпляр, введите 49172 . Щелкните Далее.
-
В диалоговом окне Действие выберите Разрешить соединениеи нажмите кнопку Далее.
-
В диалоговом окне Профиль выберите профили, описывающие среду соединения компьютеров, который нужно подключить к компоненту Компонент Database Engine, и нажмите кнопку Далее.
-
В диалоговом окне Имя введите имя и описание правила и нажмите кнопку Готово.
Дополнительные сведения о настройке брандмауэра, включая инструкции для Windows Vista, см. в разделе Настройка брандмауэра Windows для доступа к компоненту Database Engine. Дополнительные сведения о настройках брандмауэра Windows по умолчанию и описание портов TCP, влияющих на компонент Database Engine, службы Analysis Services, службы Reporting Services и службы Integration Services, см. в разделе Настройка брандмауэра Windows для разрешения доступа к SQL Server.
Шаг 2. Создание виртуального диска
Затем необходимо создать один или несколько виртуальных дисков из пула носителей. При создании виртуального диска можно выбрать способ размещения данных на физических дисках. Это влияет как на надежность, так и на производительность. Также можно выбрать, создавать ли диски с тонкой или фиксированной подготовкой.
-
Если мастер создания виртуального диска еще не открыт, на странице Пулы носителей в диспетчере серверов в разделе ПУЛЫ НОСИТЕЛЕЙ выберите нужный пул носителей.
-
В разделе Виртуальные диски выберите список задачи , а затем выберите новый виртуальный диск. Откроется мастер создания виртуальных дисков.
-
На странице перед началом выполнения нажмите кнопку Далее.
-
На странице Выбор пула носителей выберите нужный пул носителей и нажмите кнопку Далее.
-
На странице Указание имени виртуального диска введите имя и описание (необязательно), а затем нажмите кнопку Далее.
-
На странице Выбор макета хранилища выберите нужный макет, а затем нажмите кнопку Далее.
Примечание
При выборе макета, в котором недостаточно физических дисков, при нажатии на кнопку Далее появится сообщение об ошибке. Сведения о том, какой макет следует использовать, а также требования к диску, см. в разделе .
-
-
Если в качестве структуры хранилища выбрано зеркало , а в пуле имеется пять или более дисков, появится страница Настройка параметров устойчивости . Выберите один из следующих параметров:
- Двухстороннее зеркало
- Трехстороннее зеркало
-
На странице Укажите тип подготовки выберите один из следующих параметров, а затем нажмите кнопку Далее.
-
Тонкая
При тонкой подготовке пространство выделяется по необходимости. Это оптимизирует использование доступного хранилища. Однако поскольку такой вариант делает возможным чрезмерное выделение пространства хранения, необходимо внимательно следить за доступным дисковым пространством.
-
Фиксированный формат
При фиксированной подготовке емкость хранилища выделяется немедленно в момент создания виртуального диска. Таким образом, при фиксированной подготовке используется пространство из пула носителей, эквивалентное размеру виртуального диска.
Совет
Для дисковых пространств можно создавать виртуальные диски с тонкой и фиксированной подготовкой в одном пуле носителей. Например, можно использовать виртуальный диск с тонкой подготовкой для размещения базы данных, а виртуальный диск с фиксированной подготовкой для размещения связанных файлов журнала.
-
-
На странице Указание размера виртуального диска выполните следующие действия.
Если на предыдущем шаге вы выбрали фиксированную подготовку, выберите один из следующих элементов:
-
Задать размер
Если используется структура хранилища, отличная от простой, виртуальный диск использует больше свободного пространства, чем будет указано. Во избежание возможной ошибки, когда размер тома превышает свободное пространство пула носителей, можно установить флажок Создать максимально большой виртуальный диск вплоть до указанного размера.
-
Максимальный размер
Выберите этот вариант, чтобы создать виртуальный диск, который использует максимальную емкость пула носителей.
-
-
На странице Подтверждение выбора Проверьте правильность параметров и нажмите кнопку создать.
-
На странице Просмотр результатов убедитесь, что все задачи завершены, а затем нажмите кнопку Закрыть.
Совет
По умолчанию флажок Создать том при закрытии мастера установлен. После этого вы перейдете сразу же к следующему шагу.
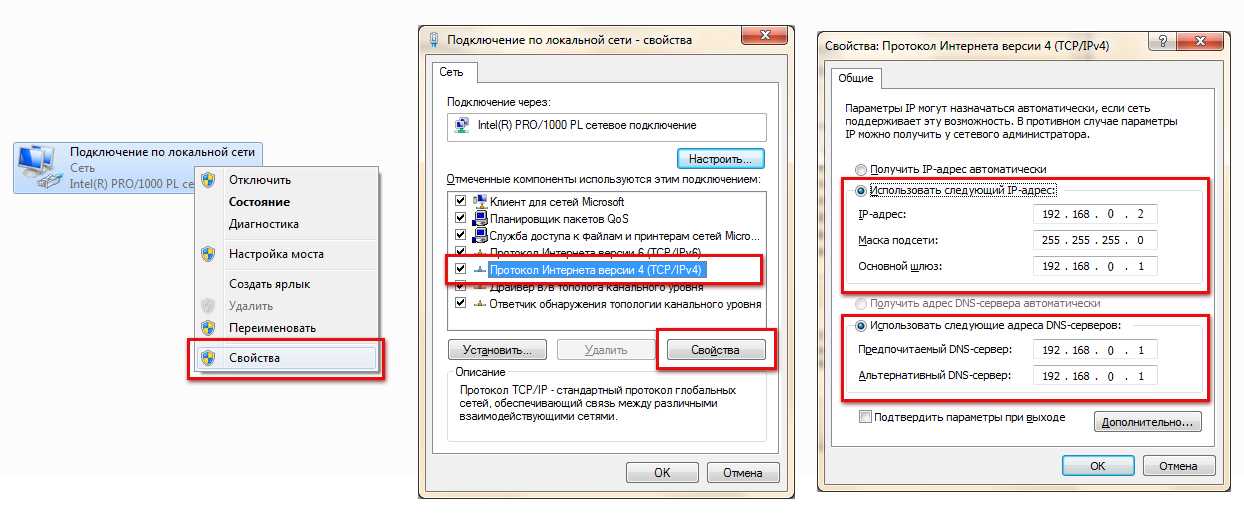
Windows PowerShell эквивалентные команды для создания виртуальных дисков
Следующие командлеты Windows PowerShell выполняют ту же функцию, что и предыдущая процедура. Вводите каждый командлет в одной строке, несмотря на то, что здесь они могут отображаться разбитыми на несколько строк из-за ограничений форматирования.
В следующем примере создается виртуальный диск 50 ГБ с именем VirtualDisk1 в пуле носителей с именем StoragePool1.
В следующем примере создается зеркальный виртуальный диск с именем VirtualDisk1 в пуле носителей с именем StoragePool1. Диск использует максимальный объем хранилища для пула носителей.
В следующем примере создается виртуальный диск 50 ГБ с именем VirtualDisk1 в пуле носителей с именем StoragePool1. Для диска используется тонкая подготовка.
В следующем примере создается виртуальный диск с именем VirtualDisk1 в пуле носителей с именем StoragePool1. Для диска используется трехстороннее зеркальное отображение, а его размер фиксирован и равен 20 ГБ.
Примечание
Для работы этого командлета в пуле носителей должно быть по крайней мере пять физических дисков. (Сюда не относятся диски, выделенные для горячего резерва.)
![Fc подключение к схд сервера под linux [colobridge wiki]](https://tehnikaarenda.ru/wp-content/uploads/3/0/8/3088427e63af655bf5006c0635689c13.jpeg)
Общие папки в отказоустойчивом кластере
В следующем списке описаны функции конфигурации общих папок, интегрированные в отказоустойчивую кластеризацию.
-
Область отображения ограничена только кластеризованными общими папками (без смешивания с некластеризованными общими папками). когда пользователь просматривает общие папки, указывая путь к кластеризованному файловому серверу, на экран будут включены только общие папки, которые являются частью конкретной роли файлового сервера. Она будет исключать некластеризованные общие папки и использует часть отдельных ролей файлового сервера, которые находятся на узле кластера.
-
Перечисление на основе доступа. можно использовать перечисление на основе доступа, чтобы скрыть указанную папку от представления пользователей. Вместо того чтобы разрешить пользователям просматривать папку, но не обращаться к ней, можно запретить им просматривать папку. Перечисление на основе доступа для кластеризованной общей папки можно настроить так же, как и для некластеризованной общей папки.
-
Автономный доступ. можно настроить автономный доступ (кэширование) для кластеризованной общей папки таким же образом, как и для некластеризованной общей папки.
-
кластерные диски всегда распознаются как часть кластера: независимо от того, используется ли интерфейс отказоустойчивого кластера, обозреватель Windows Explorer или оснастка управления общими папками и служба хранилища, Windows распознает, назначен ли диск в хранилище кластера. Если такой диск уже был настроен в оснастке управления отказоустойчивыми кластерами как часть кластеризованного файлового сервера, можно использовать любой из упомянутых выше интерфейсов для создания общего ресурса на диске. Если такой диск не был настроен как часть кластеризованного файлового сервера, создать на нем общую папку по ошибке невозможно. Вместо этого для предоставления общего доступа необходимо сначала настроить диск в составе кластеризованного файлового сервера.
-
интеграция служб для сетевой файловой системы. роль файлового сервера в Windows Server включает в себя дополнительную службу ролей под названием службы для nfs. установив службу роли и настроив общие папки службами для NFS, можно создать кластеризованный файловый сервер, поддерживающий клиенты на основе UNIX.





