
HTML5-хранилище в действии
Давайте посмотрим на HTML5-хранилище в действии. Снова обратимся к игре «уголки», которую мы построили в главе про рисование. С этой игрой связана небольшая проблема: если вы закроете окно браузера посередине игры, то потеряете результаты. Но с HTML5-хранилищем мы можем сохранять процесс игры на месте, в самом браузере. Откройте демонстрацию, сделайте несколько ходов, закройте вкладку браузера, а затем снова её откройте. Если ваш браузер поддерживает HTML5-хранилище, демонстрационная страница волшебным образом вспомнит точное положение в игре, в том числе, сколько ходов вы сделали, положение каждой фишки на доске и даже выбранную фишку.
Как это работает? Каждый раз, когда происходит изменение в игре, мы будем вызывать эту функцию.
Как видите, используется объект localStorage для сохранения процесса игры (gGameInProgress, логический тип). Далее перебираются все фишки (gPieces, массив JavaScript) и сохраняется строка и столбец для каждой из них. После чего сохраняются некоторые дополнительные состояния игры, включая выбранную фишку (gSelectedPieceIndex, целое число), фишку, которая находится в середине длинной серии прыжков (gSelectedPieceHasMoved, логический тип) и общее число сделанных ходов (gMoveCount, целое число).
При загрузке страницы вместо автоматического вызова функции newGame(), которая бы вернула все переменные в исходные значения, мы вызываем resumeGame(). Функция resumeGame() с помощью HTML5-хранилища проверяет состояние игры в локальном хранилище. Если оно есть, то восстанавливает значения с использованием объекта localStorage.
Наиболее важной частью этой функции является оговорка, о которой я упоминал ранее в этой главе и повторю здесь: данные хранятся в виде строк. Если вы храните нечто другое, а не строки, вам нужно конвертировать их при получении
К примеру, флаг о том, что игра в процессе (gGameInProgress) является логическим типом. В функции saveGameState() мы просто храним его и не беспокоимся о типе данных.
Но в функции resumeGame() мы должны рассмотреть значение, полученное из локального хранилища в виде строки и вручную построить собственное логическое значение.
Аналогичным образом, число ходов хранится в gMoveCount как целое, в функции saveGameState() мы просто сохраняем его.
Но в функции resumeGame() мы должны конвертировать значение в целое, используя встроенную в JavaScript функцию parseInt().
Работа с дисками в Kubernetes
Работа с дисковыми томами в Kubernetes проходит по следующей схеме:
- Вы описываете типы файловых хранилищ с помощью Storage Classes и Persistent Volumes. Они могут быть совершенно разными от локальных дисков до внешних кластерных систем и дисковых полок.
- Для подключения диска к поду вы создаете Persistent Volume Claim, в котором описываете потребности пода в доступе к хранилищу — объем, тип и т.д. На основе этого запроса используются либо готовые PV, либо создаются под конкретный запрос автоматически с помощью PV Provisioners.
- В описании пода добавляете информацию о Persistent Volume Claim, который он будет использовать в своей работе.
sessionStorage
Объект используется гораздо реже, чем .
Свойства и методы такие же, но есть существенные ограничения:
-
существует только в рамках текущей вкладки браузера.
- Другая вкладка с той же страницей будет иметь другое хранилище.
- Но оно разделяется между ифреймами на той же вкладке (при условии, что они из одного и того же источника).
- Данные продолжают существовать после перезагрузки страницы, но не после закрытия/открытия вкладки.
Давайте посмотрим на это в действии.
Запустите этот код…
…И обновите страницу. Вы всё ещё можете получить данные:
…Но если вы откроете ту же страницу в другой вкладке и попробуете получить данные снова, то код выше вернёт , что значит «ничего не найдено».
Так получилось, потому что привязан не только к источнику, но и к вкладке браузера. Поэтому используется нечасто.
Событие storage
Когда обновляются данные в или , генерируется событие со следующими свойствами:
- – ключ, который обновился (, если вызван ).
- – старое значение (, если ключ добавлен впервые).
- – новое значение (, если ключ был удалён).
- – url документа, где произошло обновление.
- – объект или , где произошло обновление.
Важно: событие срабатывает на всех остальных объектах , где доступно хранилище, кроме того окна, которое его вызвало. Давайте уточним
Давайте уточним.
Представьте, что у вас есть два окна с одним и тем же сайтом. Хранилище разделяется между ними.
Вы можете открыть эту страницу в двух окнах браузера, чтобы проверить приведённый ниже код.
Теперь, если оба окна слушают , то каждое из них будет реагировать на обновления, произошедшие в другом окне.
Обратите внимание, что событие также содержит: – url-адрес документа, в котором данные обновились. Также содержит объект хранилища – событие одно и то же для и , поэтому ссылается на то хранилище, которое было изменено
Мы можем захотеть что-то записать в ответ на изменения
Также содержит объект хранилища – событие одно и то же для и , поэтому ссылается на то хранилище, которое было изменено. Мы можем захотеть что-то записать в ответ на изменения.
Это позволяет разным окнам одного источника обмениваться сообщениями.
Современные браузеры также поддерживают Broadcast channel API специальный API для связи между окнами одного источника, он более полнофункциональный, но менее поддерживаемый. Существуют библиотеки (полифилы), которые эмулируют это API на основе и делают его доступным везде.
Установка NextCloud
Изначально было желание использовать Seafile: серверная часть реализована на C, он эффективен и стабилен. Но выяснилось, что в бесплатной версии есть далеко не всё.
Потому, я попробовал Nextcloud и остался доволен. Он предоставляет больше возможностей и полностью бесплатен.
Посмотреть, как он работает в демо-режиме вы можете здесь.
Вот общие точки сопряжения между облачным хранилищем и системой:
- — хранилище облачного сервиса.
- — данные офиса.
- — WEB интерфейс облачного сервиса.
Т.к. конфигурация NextCloud достаточно объёмна и состоит из нескольких файлов, я не буду приводить их здесь.
Всё, что нужно вы найдёте в репозитории на Github.
Там же доступна конфигурация для SeaFile.
Сначала установите и запустите NextCloud.
Для этого надо скопировать конфигурацию в каталог и выполнить:
Будет собран новый образ на основе Nextcloud 13.0.7. Если вы хотите изменить версию базового образа, сделайте это в . Я использую версию 15, но стоит заметить, что в ней не работают многие плагины, такие как загрузчик ocDownloader и заметки, а также я ещё не восстановил работоспособность OnlyOffice.
Кардинальных отличий или сильного улучшения производительности я не заметил.
Ниже я считаю, что вы используете версию 13+.
Далее, зайдите в NextCloud и выбрав в меню справа вверху «Приложения», выполните установку необходимых плагинов.
Потребуются обязательно:
- LDAP user and group backend — сопряжение с LDAP.
- External Storage Support — поддержка внешних хранилищ. Нужна будет далее, с целью интеграции NextCloud и общих файлов, а также сопряжения с внешними облачными хранилищами. Про настройку внешних хранилищ я расскажу в другой статье.
- ocDownloader — загрузчик файлов. Расширяет функциональность облака. Docker образ специально пересобран так, чтобы он работал.
- ONLYOFFICE — интеграция с офисом. Без этого приложения, файлы документов не будут открываться в облаке.
- End-to-End Encryption — сквозное шифрование на клиенте. Если облако используют несколько пользователей, плагин необходим, чтобы удобно обеспечить безопасность их файлов.
Желательные приложения:
- Brute-force settings — защита от подбора учётных данных. NextCloud смотрит в Интернет, потому лучше установить.
- Impersonate — позволяет администратору заходить под другими пользователями. Полезно для отладки и устранения проблем.
- Talk — видеочат.
- Calendar — говорит сам за себя, позволяет вести календари в облаке.
- File Access Control — позволяет запрещать доступ к файлам и каталогам пользователям на основе тэгов и правил.
- Checksum — позволяет вычислять и просматривать контрольные суммы файлов.
- External sites — создаёт ссылки на произвольные сайты на панельке вверху.
Особенности контейнера:
- Установлен загрузчик Aria2.
- Установлен загрузчик Youtube-DL.
- Установлены inotify-tools.
- Увеличены лимиты памяти для PHP.
- Web-сервер настроен под лучшую работу с LDAP.
Замечу, что если вы установите версию 13+, но потом решите обновиться на версию 15, это и многое другое вы сможете сделать с помощью утилиты occ.
LDAP
Настройка LDAP не тривиальна, потому я расскажу подробнее.
Зайдите в «Настройки->Интеграция с LDAP/AD».
Добавьте сервер 172.21.0.1 с портом 389.
Логин: .
NextCloud может управлять пользователями в базе LDAP и для этого ему потребуется администратор.
Нажимайте кнопку «Проверить конфигурацию DN» и, если индикатор проверки зелёный, кнопку «Далее».
Каждый пользователь имеет атрибут и состоит в группе .
Фильтр будет выглядеть так:
Нажимайте «Проверить базу настроек и пересчитать пользователей», и если всё корректно, должно быть выведено количество пользователей. Нажимайте «Далее».
На следующей странице будет настроен фильтр пользователей, по которому NextCloud их будет искать.
Фильтр:
На этой странице надо ввести логин какого-либо пользователя и нажать «Проверить настройки».
Последний раз «Далее».
Тут нажмите «Дополнительно» и проверьте, что поле «База дерева групп» равно полю «База дерева пользователей» и имеет значение .
Вернитесь в группы и установите в поле «Только эти классы объектов» галочку напротив .
Итоговый фильтр здесь такой:
Поле «Только из этих групп» я не устанавливал, т.к. хочу увидеть в интерфейсе NextCloud всех пользователей, а те кто не входит в группу , отсеиваются фильтром на предыдущем этапе.
Удаление кэша
Кэш — компоненты, несущие в себе дополнительные данные приложений, такие как эскизы страниц, превью фотографий, другие материалы, которые нужны софту для более быстрой работы. Другая сторона медали — он много весит и не всегда помогает работать системе шустрее, иногда даже наоборот. Поэтому его можно смело уничтожать без нанесения вреда работоспособности.
- Зайдите в «Настройки — Хранилище».
- Выберите там «Данные кэша», и вам предложат безвозвратно удалить все материалы.
- Соглашайтесь.
Через пару мгновений процесс завершится.
Можно еще стереть кэш отдельной программы.
- Перейдите в «Настройки — Хранилище — Приложения».
- Выберите там то, что много занимает места, посмотрите, сколько весит кэш.
- Если весит много, то нажмите «Очистить кэш».
Сторонние программы на Андроиде помогают это делать в автоматическом режиме, но в конце мы объясним, почему ими пользоваться не стоит.
Принцип работы
Локальные дисковые пространства являются развитием дисковых пространств, впервые представленных в Windows Server 2012. В них используется множество существующих возможностей Windows Server, таких как отказоустойчивая кластеризация, файловая система CSV, протокол SMB3 и, конечно, дисковые пространства. В них также были реализованы новые технологии, в первую очередь шина Software Storage Bus.
Ниже представлен обзор стека локальных дисковых пространств.
Оборудование для сетевого взаимодействия. Для обмена данными между серверами локальные дисковые пространства используют протокол SMB3, включая SMB Direct и SMB Multichannel, работающий через Ethernet. Мы настоятельно рекомендуем использовать Ethernet со скоростью передачи данных более 10 Гбит/с и удаленным доступом к памяти (RDMA) — iWARP или RoCE.
Оборудование хранилища. От 2 до 16 серверов с локально подключенными дисками SATA, SAS или NVMe. Каждый сервер должен иметь по крайней мере 2 твердотельных накопителя и 4 дополнительных диска. Устройства SATA и SAS должны располагаться за адаптером шины (HBA) и расширителем SAS. Мы настоятельно рекомендуем использовать тщательно спроектированные и протестированные платформы от наших партнеров (ожидаются в ближайшее время).
Отказоустойчивая кластеризация. Встроенная функция кластеризации Windows Server используется для подключения серверов.
Шина Software Storage Bus. Шина Software Storage Bus — это новая технология, представленная в локальных дисковых пространствах. Она охватывает весь кластер и создает программно-определяемую структуру хранения, в которой каждый сервер имеет доступ к локальным дискам любого другого сервера. Это можно рассматривать как замену дорогостоящим и ограниченным в своих возможностях подключениям Fibre Channel или Shared SAS.
Кэш уровня шины хранилища. Шина Software Storage Bus динамически связывает самые быстрые диски (например, SSD) с более медленными дисками (например, жесткими дисками) для обеспечения кэширования при чтении и записи на стороне сервера с целью ускорить ввод-вывод и повысить пропускную способность.
служба хранилища Подключений. Набор дисков, которые образуют основу для дисковых пространств, называется пулом носителей. Он создается автоматически, и все подходящие диски обнаруживаются и добавляются в него также автоматически. Мы настоятельно рекомендуем использовать один пул носителей в каждом кластере с параметрами по умолчанию. Прочитайте раздел Глубокое погружение в пул носителей, чтобы узнать больше.
дисковые пространства. дисковые пространства обеспечивает отказоустойчивость виртуальных дисков с помощью зеркального отображения, очистки кодирования или и того и другого. Их можно представить как распределенный программно-определяемый массив RAID на основе дисков в пуле. В локальных дисковых пространствах виртуальные диски обычно устойчивы к одновременному сбою двух дисков или серверов (то есть применяется трехстороннее зеркалирование, при котором каждая копия данных размещается на отдельном сервере), хотя также доступна отказоустойчивость на уровне шасси или стоек.
Resilient File System (ReFS). ReFS — это файловая система с превосходными возможностями, предназначенная специально для виртуализации. Она позволяет существенно ускорить операции с файлами VHDX, такие как создание, расширение и объединение контрольных точек, а также имеет встроенные средства проверки контрольной суммы для обнаружения и исправления ошибок на уровне отдельных битов. В ней также реализовано переключение уровней в режиме реального времени, позволяющее переносить данные между «активными» и «пассивными» уровнями хранения в режиме реального времени в соответствии с интенсивностью использования.
Общие тома кластера. Файловая система CSV объединяет все тома ReFS в единое пространство имен, доступное с любого сервера, так что для каждого сервера все тома представляются как локально подключенные.
масштабируемый файловый сервер. Этот последний уровень необходим только в конвергентных развертываниях. Он обеспечивает удаленный доступ к файлам со стороны клиентов, например другого кластера Hyper-V, через сеть по протоколу SMB3. Таким образом локальные дисковые пространства по сути превращаются в подключенное к сети хранилище (NAS).
Освобождаем хранилище на Android
О том, как выполнить очистку памяти на девайсах Android, F1comp уже рассказывал. Я лишь немного дополню.
Просканируйте гаджет на вирусы
Определить, чем заполнено хранилище «здорового» устройства, обычно несложно – достаточно открыть настройки и перейти в раздел «Память». Здесь приведена детальная информация о том, сколько места занимает операционная система, сколько – приложения вместе с их данными, сколько – изображения, видео, музыка, закачки, кэш и т. д. И если вы что-то удалите (перенесете на другой носитель, например, карточку microSD), в памяти гаджета появится свободное место.
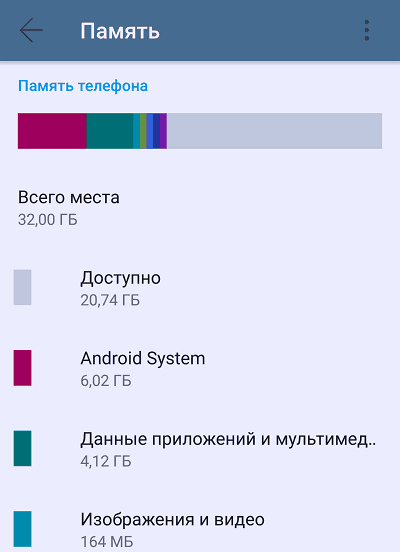
В случае заражения вредоносными программами картина может быть такой:
- Память вроде бы не переполнена, но свободного места, которое обозначено как доступное, несоизмеримо мало. Например, память устройства составляет 32 Гб, контент занимает 10 Гб, а незанятого пространства всего 10 Мб.
- Память почти полностью заполнена данными приложений и мультимедиа, но удаление установленных программ не приводит к ее освобождению.
- Система показывает, что в хранилище устройства есть свободное место, но при попытке установить приложение или сохранить файл вы получаете сообщение, что память переполнена.
Переместите обновления приложений в /system/app
На устройствах с небольшим объемом памяти, особенно тех, которые работают на старых версиях Андроида, часто возникает проблема с нехваткой места в каталоге установки приложений /data/app. Стандартная очистка кэша, перенос программ на SD-карту и удаление лишних данных помогают мало. Но есть одна хитрость, которая позволяет освободить до 30-50% места в этой области – это перемещение обновлений некоторых программ в другой каталог.
К сожалению, использовать эту хитрость возможно только на девайсах, где получены права root. Кроме того, вам понадобится бесплатная утилита SystemCleanup (если ее некуда устанавливать, придется временно пожертвовать каким-нибудь другим приложением).
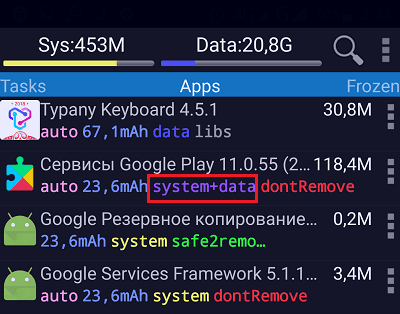
Итак, запустите утилиту и откройте вкладку Apps. В ней находится список всех программ, которые установлены на устройстве. Под каждой из них – строка основных свойств, в том числе каталог установки. У одних приложений это /system, у других – /data, а у третьих – /system+data. Последнее означает, что программа установила свои обновления в оба каталога, то есть занимает в 2 раза больше места, чем ей положено.
Чтобы разгрузить каталог установки пользовательских приложений, обновления таких программ нужно удалить из папки /data и оставить только в /system.
Откройте долгим касанием строки контекстное меню приложения, в свойствах которого указано system+data.
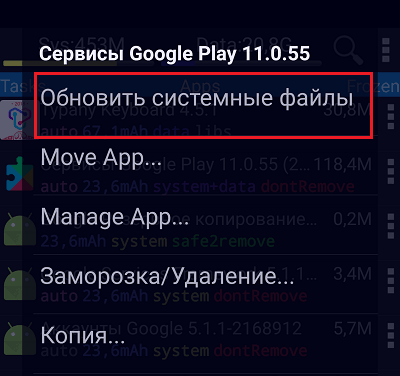
- Коснитесь команды «Обновить системные файлы» либо «Обновить системные файлы иOdex». Если в меню есть оба пункта, предпочтительнее выбрать второй – одексированные приложения работают быстрее и стабильнее.
- Подтвердите согласие на выполнение операции.
После этого в каталоге установки программ появится свободное место.
“>
Перебор ключей
Методы, которые мы видим, позволяют читать/писать/удалять данные. А как получить все значения или ключи?
К сожалению, объекты веб-хранилища нельзя перебрать в цикле, они не итерируемы.
Но можно пройти по ним, как по обычным массивам:
Другой способ – использовать цикл, как по обычному объекту .
Здесь перебираются ключи, но вместе с этим выводятся несколько встроенных полей, которые нам не нужны:
…Поэтому нам нужно либо отфильтровать поля из прототипа проверкой :
…Либо просто получить «собственные» ключи с помощью Object.keys, а затем при необходимости вывести их при помощи цикла:
Последнее работает, потому что возвращает только ключи, принадлежащие объекту, игнорируя прототип.
Хранилище Xenserver и метод восстановления после потери виртуальной машины
http-equiv=»Content-Type» content=»text/html;charset=UTF-8″>style=»clear:both;»>
Оригинал изhttp://www.lvtao.net/html/21.html, В настоящее время недоступен. Ссылка на эту статьюhttps://www.cnblogs.com/Kelly123/p/4352707.html Переизданные статьи организованы в соответствии с реальной ситуацией.
1. Восстановить SR Идея обработки: восстановление через UUID pbd, а UUID pbd можно получить через заданные sruuid, scsi ID и идентификатор хоста.
1. Сначала укажите том и запишите uuid.pvscanPV /dev/sda3 VG VG_XenStorage- lvm2 [1.81 TB / 1.26 TB free] Total: 1 / in use: 1 / in no VG: 0
2. Создайте хранилище для этого UUID.xe sr-introduce uuid= type= lvm name-label=”Local storage” content-type= user(Тип здесь должен соответствовать формату до хранения, иначе произойдет ошибка, что очень хлопотно)
3. Найдите SCSI ID устройства хранения данных или раздела SR.ls -l /dev/disk/by-id/total 0 lrwxrwxrwx 1 root root 9 Nov 22 14:31 scsi-SAdaptec_bootos_A46A2A2C -> …/…/sda lrwxrwxrwx 1 root root 10 Nov 22 14:31 scsi-SAdaptec_bootos_A46A2A2C-part1 -> …/…/sda1 lrwxrwxrwx 1 root root 10 Nov 22 14:31 scsi-SAdaptec_bootos_A46A2A2C-part2 -> …/…/sda2 lrwxrwxrwx 1 root root 10 Nov 22 14:31 -> …/…/sda3
4. Перечислите UUID хоста сервера.xe host-listuuid ( RO) : name-label ( RW): xenserver-mdqhgghe name-description ( RW): Default install of XenServer
5. Определите pdb uuid, установив sr uuid, scsi ID, host ID.xe pbd-create sr-uuid= device-config:device=/dev/disk/by-id/ host-uuid=
Получить pbd uuid:
6. Восстанавливаем это хранилище через pbd uuidxe pbd-plug uuid=
(Необязательно) Создайте ISO-диск и установите систему позже mkdir -p /iso_storage xe sr-create name-label=iso_storage type=iso device-config:location=/iso_storage device-config:legacy_mode=true content-type=iso
7, мы можем перезапустить XAPIservice xapi restart или перезапустите интерфейс инструмента xenxe-toolstack-restart
Два, восстановить VPS Создайте VPS самостоятельно, подключите жесткие диски один за другим и получите данные. Этот метод занимает много времени, при большом количестве VPS потребуется несколько дней. А если вы являетесь VPS, вам необходимо связаться с клиентом, чтобы получить соответствующие данные.
Интеллектуальная рекомендация
Глава первая: Причина В большинстве анекдотов в Интернете говорится, что программисты относительно тупые, плохие слова и в основном мужчины. Я один из тысяч программистов. Обычно я не знаю, как правил…
Всегда был спрос, надеясь увидеть в реальном времени рейтинг моего сайта в Baidu Я использовал некоторые инструменты, либо медленный ответ, либо результаты не точные или в режиме реального времени Поэ…
Алгоритм обнаружения характерных точек Обнаружение угла Харриса Обнаружение функции SIFT…
По просьбе пользователей сети напишите пример использования Selenium Grid для управления несколькими системами и несколькими браузерами для параллельного выполнения тестов. Поскольку у меня здесь две …
Эта проблема возникает, когда используется openrowset. Просто выполните следующий код: http://www.cnblogs.com/wayne-ivan/archive/2008/01/07/1028759.html…
Вам также может понравиться
В проекте .net я часто сталкиваюсь с необходимостью автоматически делать скриншот кадра после загрузки видео. Вот метод использования ffmpeg для автоматического создания скриншота Сначала загрузите фа…
Ленивая загрузка не удалась, потому что @Responsebobode JSON преобразует Getroles по умолчанию, которая заканчивается пользователем, поэтому ленивая загрузка недействительна. Если вы предоставляете TO…
virtualenv установка Основное использование Создайте виртуальную среду для проекта: virtualenv venv создаст папку в текущем каталоге, содержащую исполняемые файлы Python и копию библиотеки pip, чтобы …
Java.io.fileNotfoundException: файл: \ d: \ Code \ xml-load \ target \ xx.jar! \ Xxx (имя файла, имя каталога или синтаксис громкости неверно.) 1. При использовании Spring Boot для применения к JAR не…
Недавно я попытался установить MySQL под Windows, ссылаясь на документацию в Интернете, но я также сказал, что столкнулся с некоторыми проблемами во время реальной работы. Пожалуйста, запишите здесь д…
Слежение за областью HTML5-хранилища
Если вы хотите программно отслеживать изменения хранилища, то должны отлавливать событие storage. Это событие возникает в объекте window, когда setItem(), removeItem() или clear() вызываются и что-то изменяют. Например, если вы установили существующее значение или вызвали clear() когда нет ключей, то событие не сработает, потому что область хранения на самом деле не изменилась.
Событие storage поддерживается везде, где работает объект localStorage, включая Internet Explorer 8. IE 8 не поддерживает стандарт W3C addEventListener (хотя он, наконец-то, будет добавлен в IE 9), поэтому, чтобы отловить событие storage нужно проверить, какой механизм событий поддерживает браузер (если вы уже проделывали это раньше с другими событиями, то можете пропустить этот раздел до конца). Перехват события storage работает так же, как и перехват других событий. Если вы предпочитаете использовать jQuery или какую-либо другую библиотеку JavaScript для регистрации обработчиков событий, то можете проделать это и со storage тоже.
if (window.addEventListener) {
window.addEventListener(«storage», handle_storage, false);
} else {
window.attachEvent(«onstorage», handle_storage);
};
Функция обратного вызова handle_storage будет вызвана с объектом StorageEvent, за исключением Internet Explorer, где события хранятся в window.event.
function handle_storage(e) {
if (!e) { e = window.event; }
}
В данном случае переменная e будет объектом StorageEvent, который обладает следующими полезными свойствами.
| Свойство | Тип | Описание |
|---|---|---|
| key | string | Ключ может быть добавлен, удален или изменен. |
| oldValue | любой | Предыдущее значение (если переписано) или null, если добавлено новое значение. |
| newValue | любой | Новое значение или null, если удалено. |
| url* | string | Страница, которая вызывает метод, приведший к изменению. |
* Примечание: свойство url изначально называлось uri и некоторые браузеры поддерживали это свойство перед изменением спецификации. Для обеспечения максимальной совместимости вы должны проверить существует ли свойство url, и если нет проверить вместо него свойство uri.
Событие storage нельзя отменить, внутри функции обратного вызова handle_storage нет возможности остановить изменение. Это просто способ браузеру сказать вам: «Эй, это только что случилось. Вы ничего не можете сделать, я просто хотел, чтобы вы знали».
Удаление информации из папки .thumbnails на Android
Наверное, немногие знают, но при просмотре галереи система Android создаёт эскизы – это небольшие снэпы картинок. Их основная задача заключается в увеличении скорости следующей загрузки файлов. Несложно догадаться, что эти эскизы занимают место и имеют минимальную практическую пользу.
Что делать, если память телефона заполнена:
- Подключаем смартфон к ПК и включаем режим «Передача файлов».
- Открываем раздел «DCIM» в разделе телефона.
- Переходим в каталог «.thumbnails».
- Нажимаем сочетание Ctrl + A и удаляем всё содержимое.
Со временем в данном разделе скапливаются данные на 1-2 Гб. Только их удаление поможет телефону, возможно, он даже перестанет тормозить.
Важно! Это действие рекомендуем выполнять с определенной периодичностью. В зависимости от активности использования смартфона – это 1-3 недели
Если забываем выполнить очистку, в разделе скопиться снова такое же количество файлов.
Заключение
На наглядных примерах я показал, как можно работать с данными в кластере Kubernetes. Можно использовать как отказоустойчивые внешние хранилища для размещения постоянных данных. А можно сырые диски на серверах и использовать кластер для работы какой-то распределенной базы данных или сервиса, которые сами следят за количеством копий данных и распределяют их по нодам.
В последнем случае можно использовать самое обычное железо для кластера Kубернетиса, без рейд контроллеров и дублирования дорогих и быстрых SSD дисков. Необходимо только следить за количеством реплик приложения на нодах, чтобы их количество было достаточно для стабильной работы системы.
Два этих подхода можно комбинировать. Внешние хранилища для холодных данных и внутренние SSD диски для кэшей.
На этом у меня все. Надеюсь мой цикл статей по k8s был для вас полезен.
Онлайн курс «DevOps практики и инструменты»
Если у вас есть желание научиться строить и поддерживать высокодоступные и надежные системы, научиться непрерывной поставке ПО, мониторингу и логированию web приложений, рекомендую познакомиться с онлайн-курсом «DevOps практики и инструменты» в OTUS. Курс не для новичков, для поступления нужны базовые знания по сетям и установке Linux на виртуалку. Обучение длится 5 месяцев, после чего успешные выпускники курса смогут пройти собеседования у партнеров.
Проверьте себя на вступительном тесте и смотрите программу детальнее по .



