
Общие сведения о виртуализации
По своей сути, все ОС это в общем-то и так некоторая виртуальная среда, которая предоставляется разработчику ПО, как средство реализации конечных задач. Уже давно прошло то время, когда программы писались конкретно под аппаратную часть компьютера по средствам аппаратных кодов и запросов. Сегодня же, любое приложение – это в первую очередь приложение, написанное на некотором API, который находится под управлением ОС. Задачи же ОС – предоставить данным API непосредственно доступ к аппаратным ресурсам.
Собственно видов виртуализации существует несколько:
- Программная виртуализация;
- Аппаратная виртуализация;
- Виртуализация уровня операционной системы.
Виртуализация в свою очередь бывает полной и частичной.
Программная виртуализация – вид виртуализации, который задействует различные библиотеки ОС, транслируя вызовы виртуальной машины в вызовы ОС. (DOSBox, Virtualbox, VirtualPC)
Аппаратная виртуализация – такой вид, который предусматривает специализированную инструкцию аппаратной части, а конкретно инструкций процессора. Позволяет исполнять запросы в обход гостевой ОС, и исполнять прямо на аппаратном обеспечении. (виртуализация KVM,виртуализация XEN, Parallels, VMware, Virtualbox)
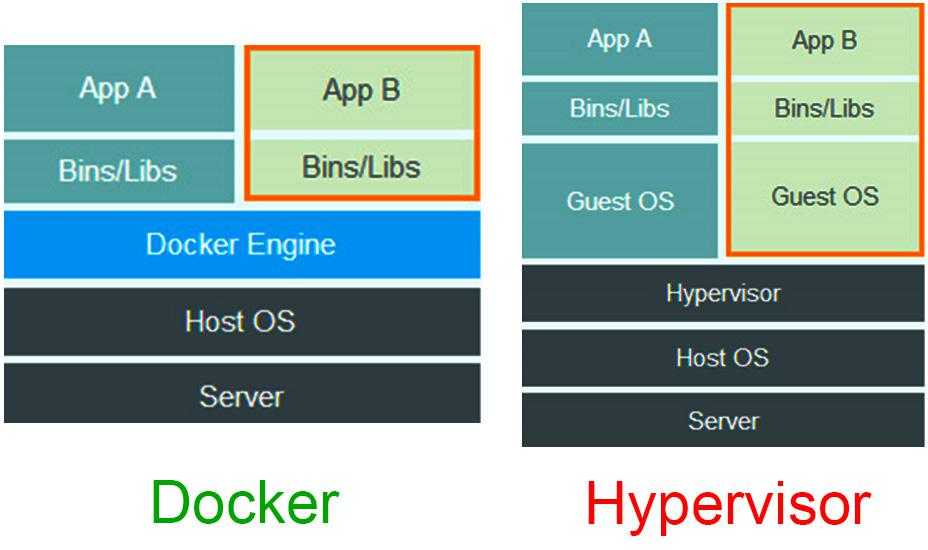
Виртуализация уровня операционной системы – виртуализация только части платформы, без полной виртуализации аппаратной части. Подразумевает работы нескольких экземпляров среды ОС. (Docker, LXC)
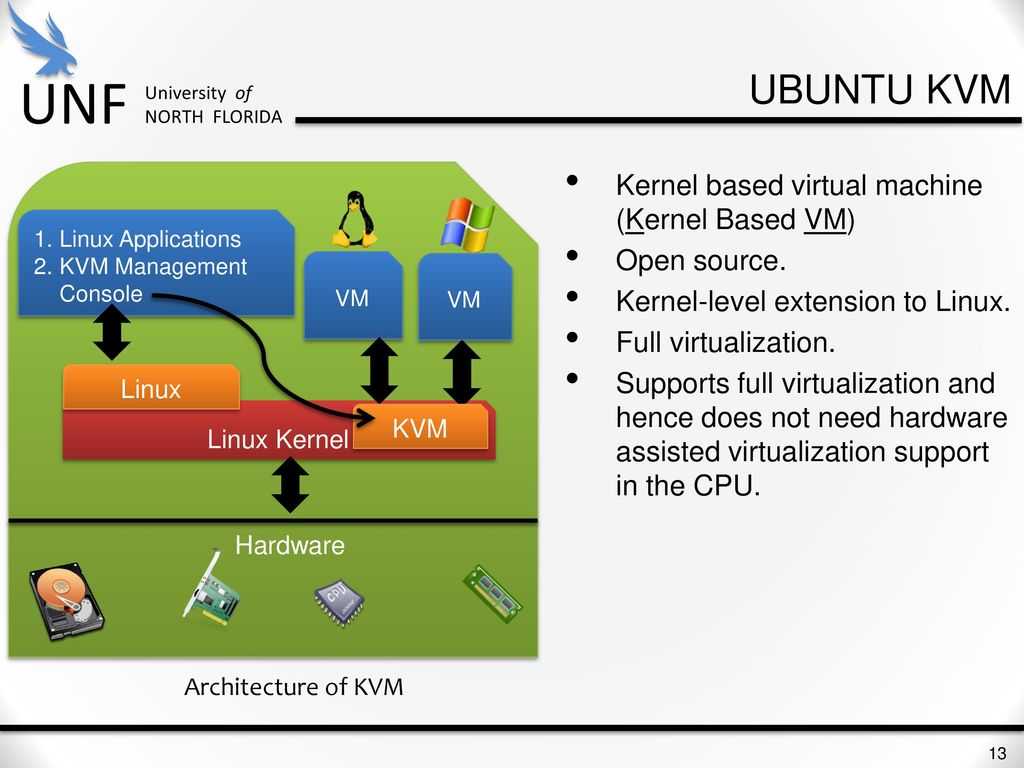
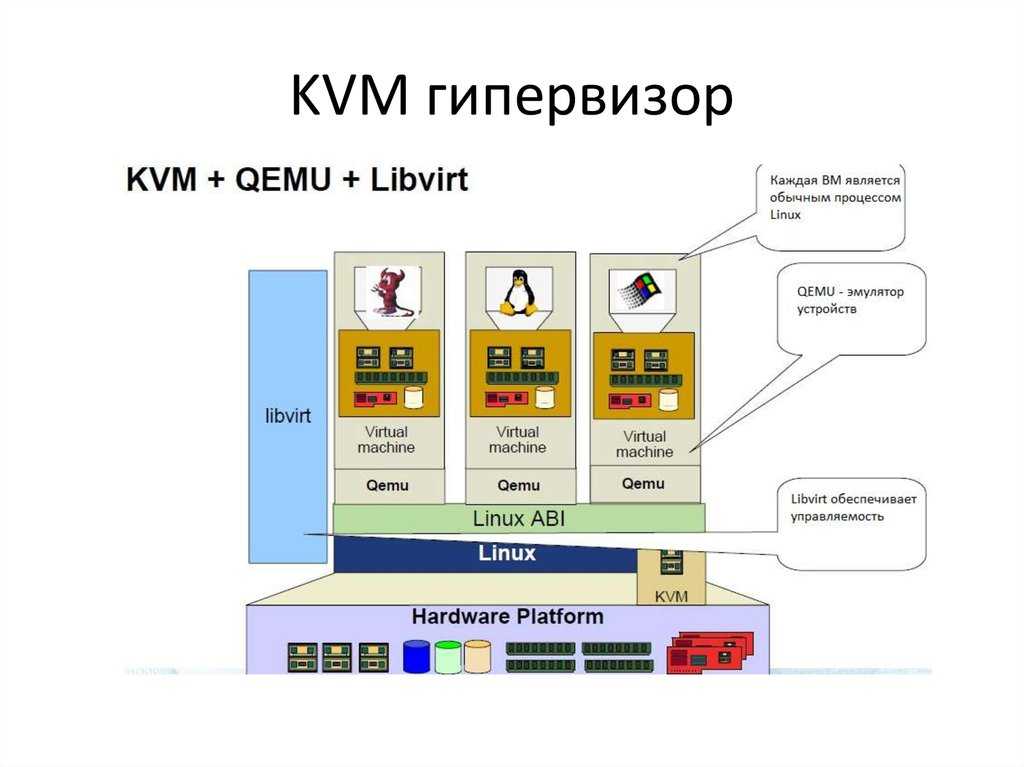
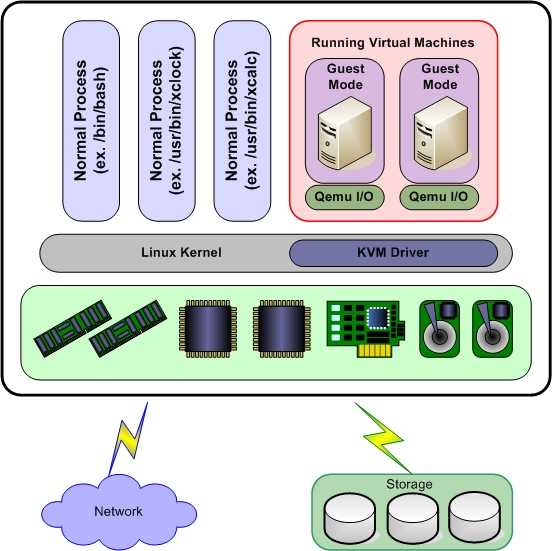
Данная статья будет рассматривать Аппаратную виртуализацию, а конкретно виртуализацию KVM.
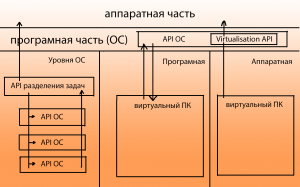
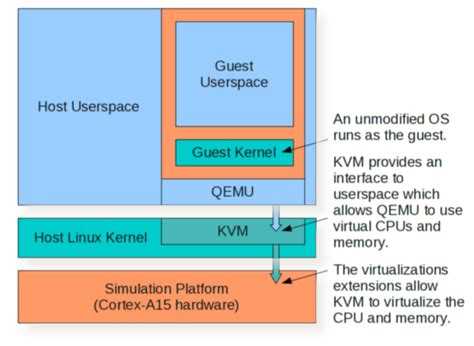
Схема 1. – Взаимодействие компонентов виртуальной машины с аппаратной частью
https://youtube.com/watch?v=WOVDqSYmTfM
Достоинства и недостатки при развертывании облака с использованием первичных NFS-хранилищ
NFS — широко применяемый протокол доступа к файловым системам, зарекомендовавший себя за десятилетия использования. К достоинствам NFS-хранилищ при реализации сервиса публичного облака можно отнести следующие свойства:
- высокая производительность хранилища, достигаемая за счет консолидации большого количества дисковых устройств в одном сервере;
- эффективное использование пространства хранилища, достигаемое за счет возможности продажи дискового пространства сверх реального объема за счет использования тонкого выделения при использовании формата томов QCOW2, что позволяет развивать хранилище по мере необходимости с запаздыванием;
- простота распределения дискового пространства между хостами виртуализации, достигаемая за счет функционирования всего пространства хранилища как единого пула;
- поддержка живой миграции виртуальных машин между хостами, разделяющими одно хранилище;
- простота администрирования.
К недостаткам же можно отнести следующие свойства:
- единая точка отказа для всех виртуальных машин, разделяющих хранилище;
- требуется тщательное планирование производительности на этапе проектирования;
- некоторые регламентные процедуры, требующие остановки хранилища, будут вызывать остановку всех машин, использующих данное хранилище;
- требуется разработка регламентных процедур наращивания свободного пространства хранилища (добавление новых дисков, сборка RAID, миграция данных между логическими томами).
OpenVZ

OpenVZ становится все более популярным в индустрии хостинга из-за его очень высокой плотности и быстрого развертывания. Это возможно, поскольку ядро хоста совместно с гостями использует дисковое пространство, ЦП и ОЗУ. Между хостом и гостем существует очень простое разделение, а узкое место ввода-вывода практически отсутствует.
OpenVZ — это программное обеспечение для виртуализации, предлагаемое SWSoft Inc. OpenVZ предлагает огромное количество преимуществ для администратора, поскольку позволяет размещать несколько виртуальных сред на одном сервере. Единственными ограничениями для этого являются ЦП и ОЗУ.
OpenVZ — это технология виртуализации на уровне ОС, основанная на ядре Linux. Это позволяет одному физическому серверу запускать несколько различных экземпляров операционной системы, известных как виртуальные среды или виртуальные частные серверы.
В отличие от паравиртуализации и технологий VMWare, таких как Xen, OpenVZ ограничен, поскольку требует, чтобы и гостевая, и хост-ОС были Linux, хотя дистрибутивы Linux могут быть разными в виртуальных средах с общим ядром. OpenVZ предлагает хорошее преимущество в производительности, и штраф за запуск OpenZ составляет от 1 до 3% по сравнению с другим автономным сервером.
Поскольку OpenVZ использует одну модель ядра, он может поддерживать до 64 процессоров и до 64 ГБ оперативной памяти. Единая виртуальная среда может масштабироваться до целого физического блока и использовать всю оперативную память и все процессоры.
OpenVZ разделен на настраиваемое ядро и может использоваться ряд инструментов, таких как vzstat, vzctl и т.д. Помимо этого, в OpenVZ отсутствуют некоторые функции коммерческого продукта Virtuozzo, такие как расширенная файловая система, функции создания шаблонов, позволяющие экономить дисковое пространство, и дополнительные пользовательские инструменты. OpenVZ гибок, эффективен и предлагает качественные услуги в корпоративной среде. Каждый виртуальный частный сервер представляет собой независимое оборудование, которое может быть перемещено в другую систему на основе OpenVZ внутри сети.
Что касается задержки диска и скорости доступа к диску, OpenVZ явно является победителем по сравнению с Xen и KVM, однако, когда дело доходит до стоимости отсутствия разделения и конфиденциальности, а также влияния одной гостевой ОС на оба хоста. node и других гостевых ОС, это очень беспокоит. Все отдельные процессы видны хост-узлу, и данные не могут быть зашифрованы или скрыты.
OpenVZ поддерживает только Linux, если не используются различные коммерческие параллели. Преимущество OpenVZ в том, что он также может быть вложен в KVM или Xen для достижения еще большей плотности. Из-за количества гостей, которые вы можете запустить на хост-узле, цена OpenVZ остается гораздо более конкурентоспособной, чем Xen или KVM.
https://youtube.com/watch?v=VTPoEYb2qWE
Запуск виртуальной машины
А теперь самое интересное. Ниже несколько красивых скриншотов…
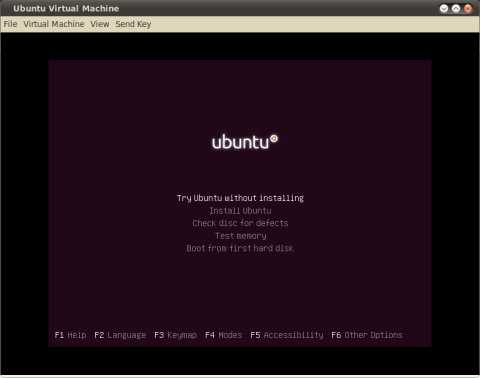
Начинаем с загрузочного меню 32-битной версии Ubuntu 10.10 Maverick:
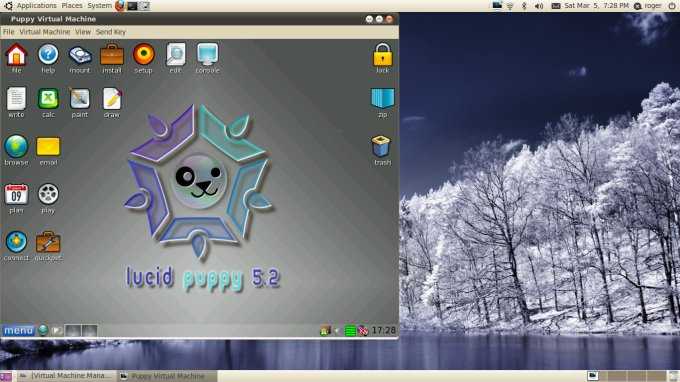
Рабочий стол Puppy Linux как всегда великолепен:
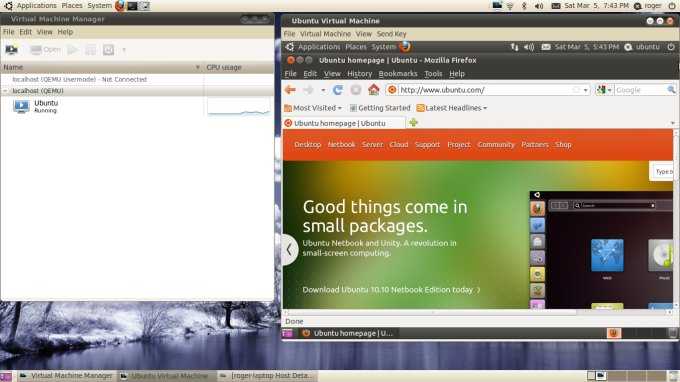
Теперь Ubuntu, запущенная под NAT
Обратите внимание на низкую загрузку процессора. Позже мы поговорим об этом, когда будем обсуждать режим эмуляции
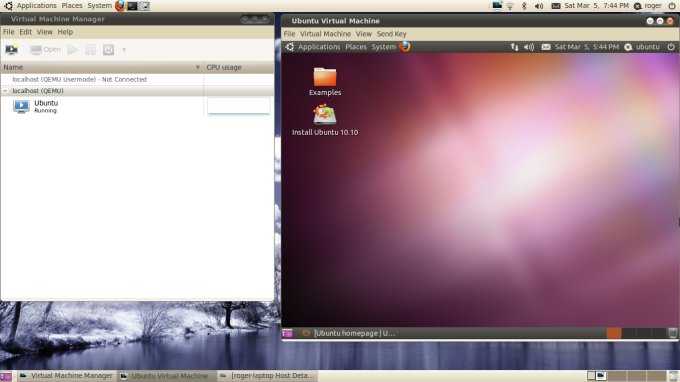
Размер окна консоли можно подгонять под разрешение рабочего стола гостевой системы. На следущем скриншоте Puppy и Ubuntu бок о бок:
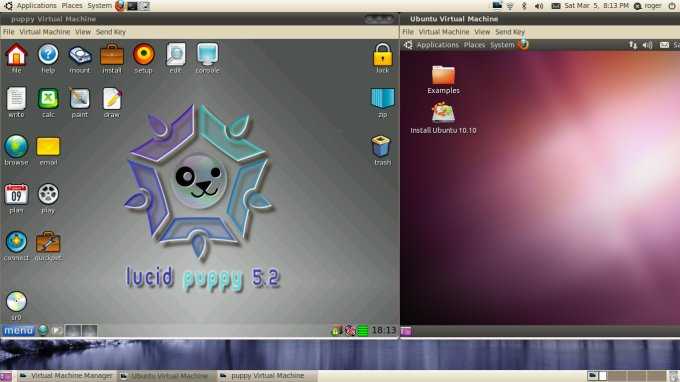
Обратите внимание на небольшую загрузку системы. С этим режимом эмуляции можно запускать одновременно несколько виртуальных машин
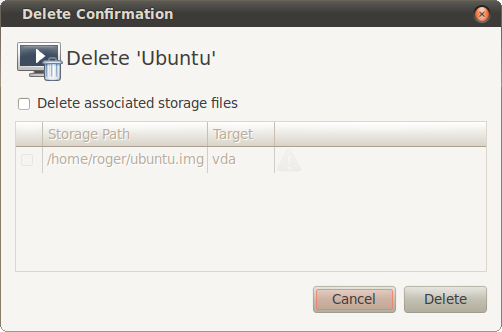
При необходимости можно удалить виртуальную машину вместе со всеми ее файлами:
Базовые команды управления ВМ
1. Получить список созданных машин:
virsh list —all
2. Включить / перезагрузить / выключить.
а) включить виртуальную машину можно командой:
virsh start FirstTest
* где FirstTest — имя созданной машины.
б) перезагрузить:
virsh reboot FirstTest
* посылает команду операционной системе на корректную перезагрузку.
в) выключить корректно:
virsh shutdown FirstTest
* посылает команду операционной системе на корректное выключение.
г) выключить принудительно:
virsh destroy FirstTest
* грубо выключает ВМ. Может привести к потере данных. Способ стоит применять при полном зависании виртуалки.
д) приостановить:
virsh suspend FirstTest
Для возобновления работы вводим команду:
virsh resume FirstTest
е) отправить команду всем гостевым операционным системам:
for i in $(virsh list —name —state-shutoff); do virsh start $i; done
for i in $(virsh list —name —state-running); do virsh shutdown $i; done
* первыя команда запустит все ВМ, вторая — отправит команду на выключение.
3. Разрешаем автостарт для созданной ВМ:
virsh autostart FirstTest
4. Удаление виртуальной машины:
Удаляем виртуальную машину:
virsh undefine FirstTest
Удаляем виртуальный жесткий диск:
\rm /kvm/images/FirstTest-disk1.img
* где /kvm/images — папка, где хранится диск; FirstTest-disk1.img — имя виртуальног диска для удаленной машины.
5. Редактирование конфигурации виртуальной машины:
Открыть редактор для изменения конфигурации:
virsh edit FirstTest
Также можно менять параметры из командной строки. Приведем несколько примеров для работы с виртуальной машиной FirstTest.
а) изменить количество процессоров:
virsh setvcpus FirstTest 2 —config —maximum
virsh setvcpus FirstTest 2 —config
б) изменить объем оперативной памяти:
virsh setmaxmem FirstTest 2G —config
virsh setmem FirstTest 2G —config
6. Увеличение диска
Получаем список дисков для виртуальной машины:
virsh domblklist FirstTest
Останавливаем виртуальную машину:
virsh shutdown FirstTest
Увеличиваем размер диска:
qemu-img resize /kvm/images/FirstTest-disk1.img +100G
* данной командой мы расширим дисковое пространство виртуального диска /kvm/images/FirstTest-disk1.img на 100 Гигабайт.


Запускаем виртуальную машину:
virsh start FirstTest
Меняем размер блочного устройства:
virsh blockresize FirstTest /kvm/images/FirstTest-disk1.img 200G
Получаем информацию о виртуальном диске:
qemu-img info /kvm/images/FirstTest-disk1.img
7. Работа со снапшотами
а) Создать снимок виртуальной машины можно командой:
virsh snapshot-create-as —domain FirstTest —name FirstTest_snapshot_2020-03-21
* где FirstTest — название виртуальной машины; FirstTest_snapshot_2020-03-21 — название для снапшота.
б) Список снапшотов можно посмотреть командой:
virsh snapshot-list —domain FirstTest
* данной командой мы просмотрим список всех снапшотов для виртуальной машины FirstTest.
в) Для применения снапшота, сначала мы должны остановить виртуальную машину. Для этого можно либо выполнить выключение в операционной системе или ввести команду:
virsh shutdown FirstTest
После вводим:
virsh snapshot-revert —domain FirstTest —snapshotname FirstTest_snapshot_2020-03-21 —running
* где FirstTest — имя виртуальной машины; FirstTest_snapshot_2020-03-21 — имя созданного снапшота.
г) Удалить снапшот можно так:
virsh snapshot-delete —domain FirstTest —snapshotname FirstTest_snapshot_2020-03-21
8. Клонирование виртуальных машин
Для примера, склонируем виртуальную машину FirstTest и создадим новую SecondTest.
Для начала, мы должны остановить виртуалку:
virsh suspend FirstTest
После можно клонировать:
virt-clone —original FirstTest —name SecondTest —file /kvm/images/SecondTest-disk1.img
* итого, мы склонируем виртуальную машину FirstTest. Новая машина будет иметь название SecondTest, а путь до диска будет /kvm/images/SecondTest-disk1.img.
Восстанавливаем работу FirstTest:
virsh resume FirstTest
Типы гипервизоров
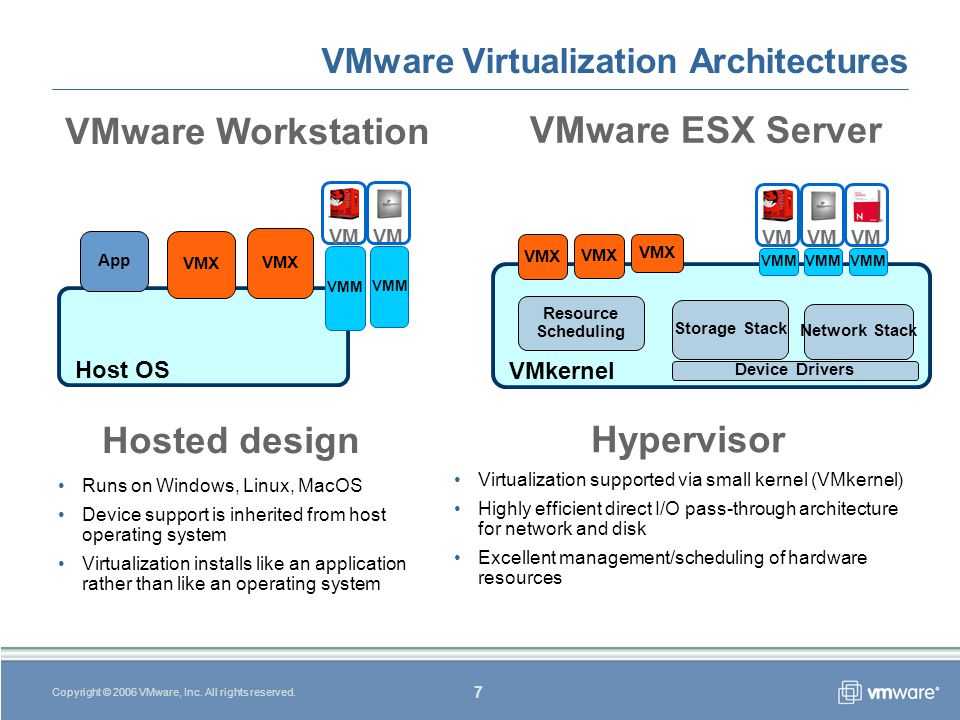
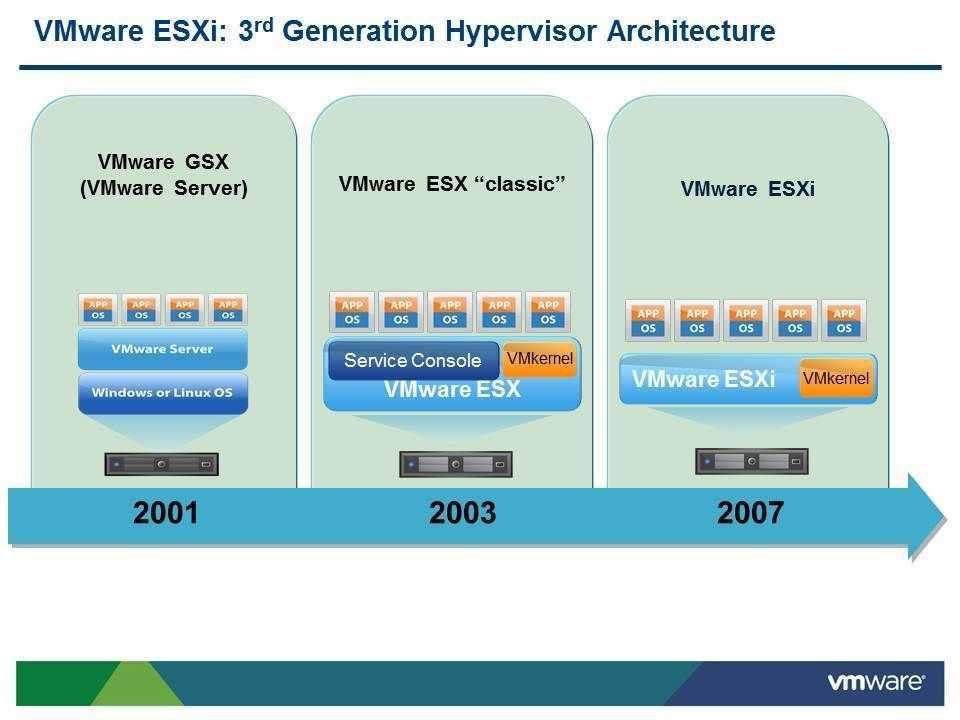
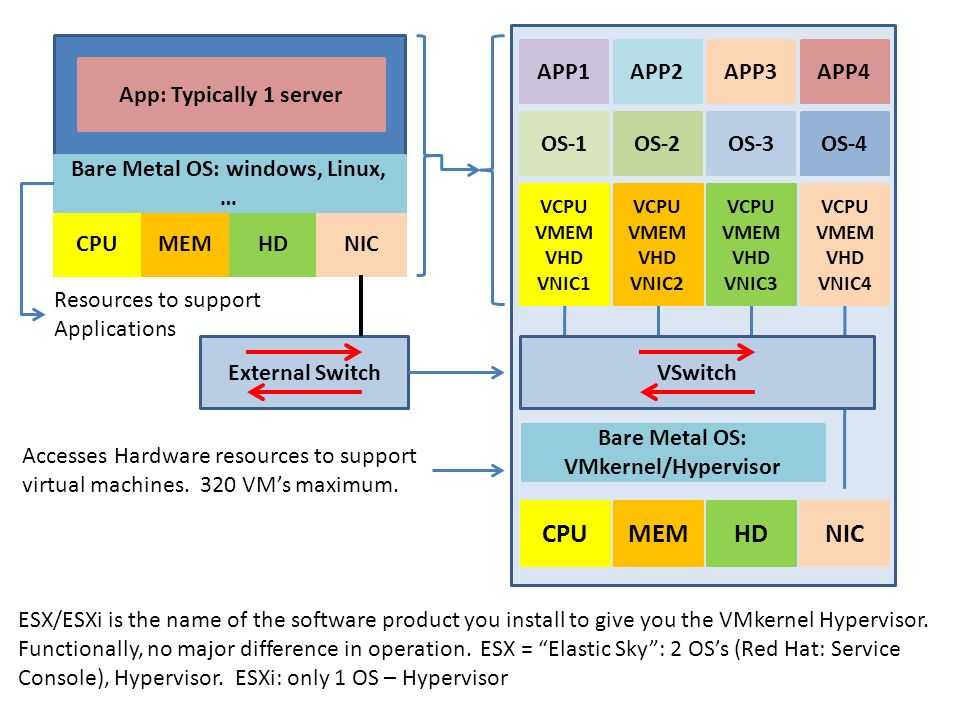
Существует два типа гипервизоров. Гипервизоры первого типа запускаются непосредственно на «железе» и не требуют установки какой-либо операционной системы. Для работы монитора виртуальных машин второго типа нужна операционная система — через нее производится доступ к аппаратной части. Лучшим гипервизором считается тот, что относится к первому типу, т. к. его производительность выше, поскольку они работают напрямую с оборудованием.
Рис. 1. Принцип работы гипервизора 1-го типа
Рис. 2. Принцип работы гипервизора 2-го типа
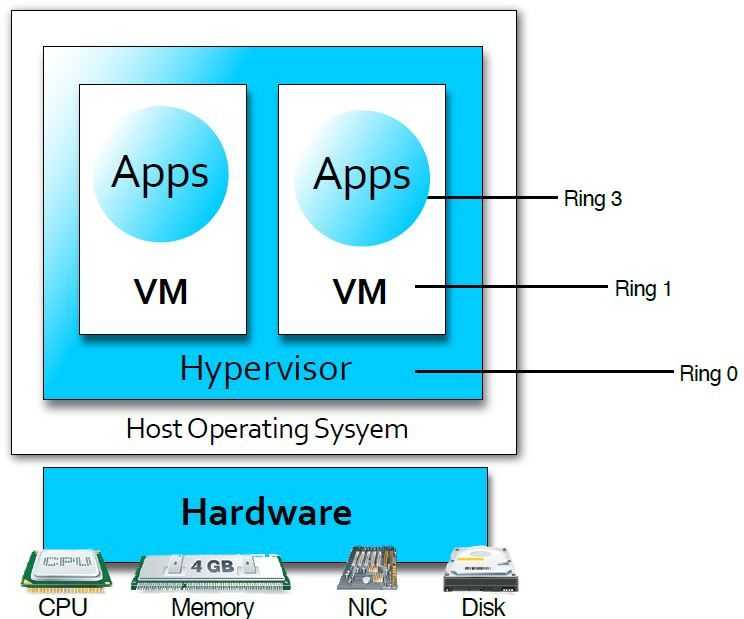

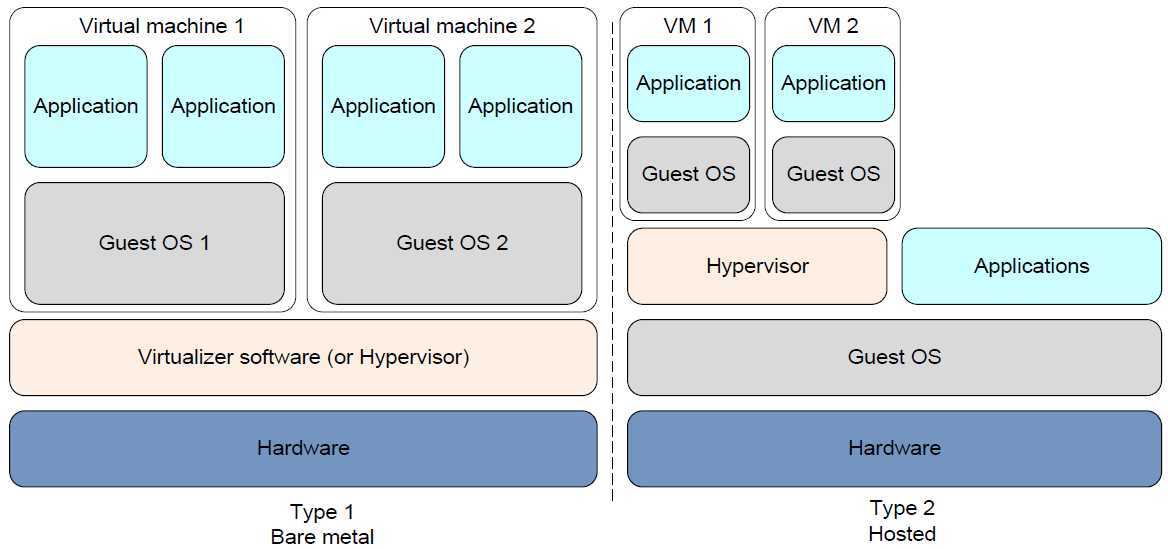
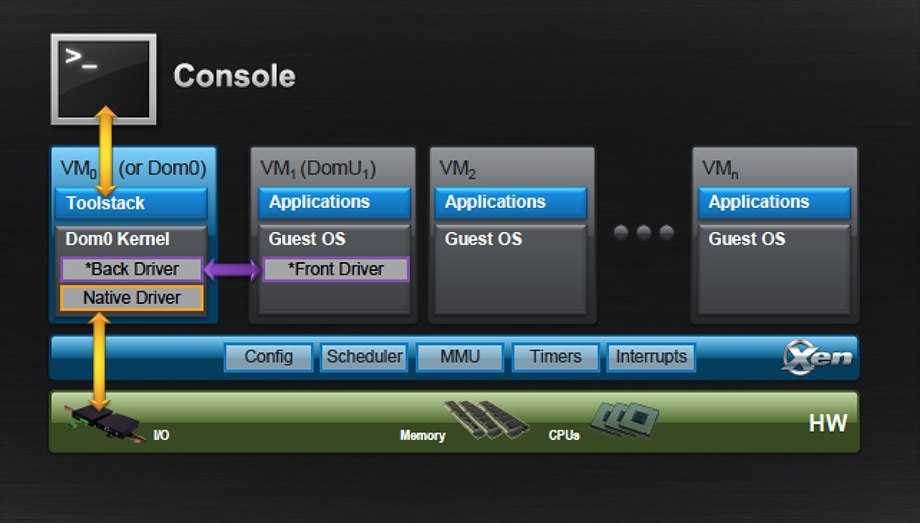
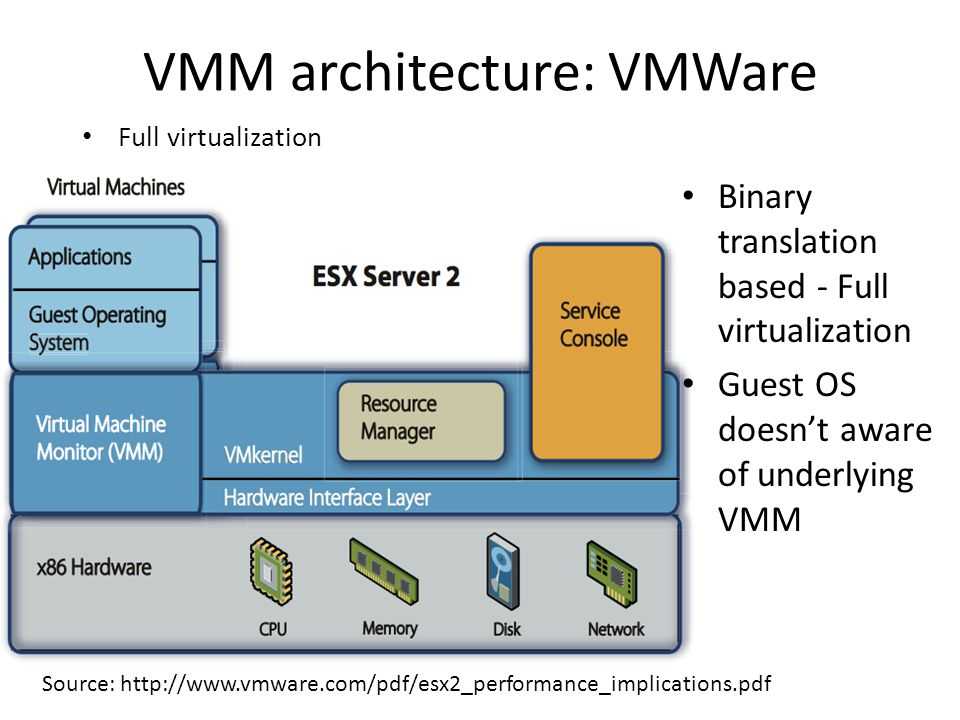
Примеры гипервизоров 1-го типа: Hyper-V, KVM, ESXi. Гипервизоры 2-го типа: VMware Workstation, Oracle Virtual Box, OpenVZ. Нас интересуют только системы виртуализации первого типа, так как вторые больше подходят для индивидуального использования, чем в качестве решений уровня предприятия.
Отметим, что Hyper-V и WMware — это проприетарные решения, поэтому мы подготовили обзор и сравнение гипервизоров этих моделей. Мы также поговорим и о решении с открытым исходным кодом — KVM. Многие предприятия выбирают именно его, не смотря, что некоторые независимые эксперты считают это решение довольно сырым и непригодным на корпоративной кухне. Однако, согласно отчету IT Central Station за январь 2018 года, 25% операторов связи и 11% финансовых организаций считают именно KVM лучшим гипервизором. Так что при рассуждениях о том, какой гипервизор выбрать, это решение исключать нельзя.
Рис. 3. Немного статистики от IT Central Station
Сначала мы рассмотрим проприетарные решения, а затем попытаемся выяснить, стоит ли использовать KVM.
Шаг 4: Весёлая часть
Есть три способа получить ускоренный виртуальный дисплей VM с Windows на экране вашей машины.
- VNC или какой-то другой протокол удалённого доступа (обычно это весьма плохое решение). В этом варианте вам нужно только подключить vGPU и отключить все остальные дисплеи и видеокарты. Также выставьте настройку . Вам не нужна опция , показанная позже.
- SPICE (у меня не получилось добиться 30 FPS или выше, но работает общий буфер обмена и передача файлов между VM и хостом).
- Встроенный интерфейс QEMU на GTK+ (общий буфер обмена и передача файлов не работают, но можно добиться 60 FPS с помощью патча).
Что бы вы ни собирались использовать, вам всё равно придётся использовать второй вариант, чтобы установить драйвера для GPU. Встроенные драйвера от Microsoft не очень хорошо работают с GVT-g на момент написания поста, и часто ломаются. До того, как вы подсоедините vGPU к ВМ, желательно скачать последнюю версию драйвера от Intel(Судя по всему, Intel меняет подход к распространению драйверов, так что в будущем этот шаг, возможно, будет другим, либо станет вообще не нужным). Теперь убедитесь, что у вас создан vGPU. Откройте и замените хороший быстрый QXL на медленный Cirrus во избежание конфликтов. Чтобы подключить vGPU к ВМ, нужно открыть и где-нибудь добавить такой фрагмент:
Замечание: Когда я предоставляю XML-фрагмент вроде этого, вам по возможности следует добавить его к текущему, не заменяя ничего.
Проверьте, что вы создали уникальные UUID для всех vGPU, которые вы используете, и что номера слотов не конфликтуют ни с какими из остальных PCI-устройств. Если номер слота находится после Cirrus GPU, виртуальная машина упадёт. Теперь вы можете запустить виртуальную машину. Нужно установить , чтобы увидеть оба дисплея! Подключиться к ВМ можно с помощью команды
Один из дисплеев будет пустой или не инициализированный, второй — уже знакомый маленький не ускоренный дисплей. Раскройте его и, войдя, установите драйвер для GPU. Если вам повезёт, всё заработает сразу же. В противном случае, надо выключить и снова запустить ВМ (не перезагрузить) с помощью работающего экрана. Теперь самое время открыть терминал и запустить внутри . Эта команда выдаст вам некоторую полезную информацию о проблемах и общем ходе работы с использованием vGPU. Например, при загрузке KVM будет жаловаться на заблокированные MSR, затем вы должны получить несколько сообщений о неправильном доступе, когда vGPU инициализируется. Если их слишком много — что-то не так.
Если система загрузилась, можно открыть настройки дисплея и отключить не ускоренный экран. Пустой экран можно скрыть через меню View в . В принципе, ВМ уже можно использовать, но есть ещё пару вещей, которые можно сделать, чтобы добиться более высокого разрешения и более высокой скорости.
Утилита CRU весьма полезна. Можете поиграться с ней, и даже если вы наткнётесь на какие-то графические артефакты или даже почти целиком чёрный экран, как получилось у меня, вы можете запустить файл , идущий в комплекте с программой, чтобы перезагрузить графическую подсистему Windows. Лично я использую эту утилиту для использования более высокого разрешения на более скромном vGPU.
Чтобы добиться прекрасных 60 FPS, нужно переключиться на встроенный монитор QEMU на GTK+ без поддержки общего буфера обмена с хостом и подобных плюшек, а также изменить в нём одну строчку и пересобрать QEMU. Также понадобится добавить пачку противных аргументов командной строки в ваш XML. Удалите дисплей SPICE и видеокарту Cirrus и установите атрибут у вашего vGPU в (libvirt не поддерживает дисплей на GTK+ и не позволит загрузиться с без дисплея).
Масштабирование для HiDPI у монитора QEMU работает из рук вон плохо, поэтому мы его отключим. Также, вам понадобится установить переменную в тот номер дисплея, который вы используете. Чтобы дать пользователю, запускающему qemu, права доступа к X серверу, используйте команду:
Если это не сработало, попробуйте , но убедитесь, что вы используете файрвол. Иначе попробуйте более безопасный метод.
Если вы потерялись где-то по пути, можете посмотреть мой текущий XML для libvirt.
Скачивание и установка KVM
Для работы KVM необходимо установить следующие пакеты (для дистрибутивов с apt):
$ apt-get install qemu-kvm libvirt-bin
Кроме того, я настоятельно рекомендую установить дополнительно следующие пакеты:
$ apt-get install bridge-utils virt-manager python-virtinst
P.S. В различных дистрибутивах пакеты могут называться по разному. Например, virt-install может называться python-virt-install или python-virtinst. Зависимости для virt-clone, virt-image и virt-viewer должны установиться автоматически.
В отличие от того, что пишется в большинстве руководств, утилиты bridge устанавливать необязательно. Они нужны только в том случае, если вы собираетесь создавать сетевой мост между виртуальными и физическими сетевыми картами.
В большинстве руководств также указывается, что большинство беспроводных сетевых интерфейсов не работают с мостами. Может быть это верно для какого-либо частного случая, однако у меня мост прекрасно работает с беспроводными адаптерами, поэтому будем надеяться, что и вас все заработает.
Я настоятельно рекомендую VMM (virt-manager). Более того, лучше установить и все утилиты поддержки, включая virt-viewer, virt-install, virt-image и virt-clone.
И последнее. Вы можете предпочесть ubuntu-vm-builder:
$ apt-get install ubuntu-vm-builder
Кроме этого, скорее всего будет установлено большое количество зависимостей, поэтому загрузка может занять значительное время.
P.S. На RedHat используйте yum install, на SUSE — zypper install.
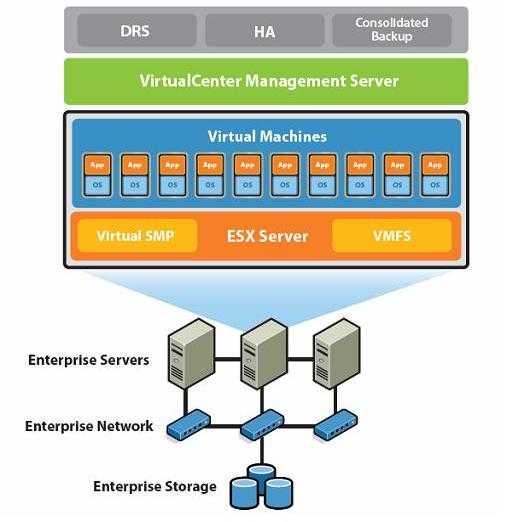
Сервер виртуализации
Сервер виртуализации предназначен для выполнения виртуальных машин. Конфигурация сервера виртуализации может существенно различаться от облака к облаку и зависит от типа вычислительных предложений (конфигураций VPS, доступных пользователям) и их назначения. В рамках одного кластера желательно иметь однотипные, взаимозаменяемые серверы виртуализации с совместимыми CPU (или обеспечить совместимость по младшему CPU среди всех), что позволит обеспечить живую миграцию виртуальных машин между узлами и доступность ресурсов кластера при выходе одного из узлов из строя.
В том случае, если планируется выполнение множества небольших виртуальных машин с низкой и средней нагрузкой, то желательно использовать серверы с большим количеством ядер и памяти, например, 2 x Xeon E5-2699V4 / 256GB RAM. При этом удается достичь хорошей плотности ресурсов и высокого качества обслуживания для виртуальных машин с 1, 2, 4, 8 ядрами, обычного использования (не для решения вычислительных задач) и добиться высокого качества обслуживания при существенной переподписке по CPU (в 2-8 раз). В таком случае, планирование может производиться исходя из объема RAM, а не количества ядер.
Если же планируется развертывание высокочастотных, многоядерных, высоконагруженных виртуальных машин, то необходимо выбирать серверы, которые обеспечивают необходимые ресурсы CPU. В этом случае планирование должно производиться, исходя из доступного без переподписки количества ядер, а объем оперативной памяти должен соответствовать необходимой потребности. Для примера, можно рассмотреть сервер Xeon E3-1270V5 / 64GB RAM, который может использоваться для предоставления услуг высокочастотных виртуальных машин:
- 1 x CPU 3.6 GHz / 8 GB RAM
- 2 x CPU 3.6 GHz / 16 GB RAM
- 4 x CPU 3.6 GHz / 32 GB RAM
- 8 x CPU 3.6 GHz / 64 GB RAM
Аналогично, можно рассмотреть использование серверов на базе 2 x Xeon E5V4, при этом планирование должно осуществляться аналогичным образом, исходя из фактических потребностей CPU, а не RAM.
Оптимизация RAM
Apache CloudStack позволяет осуществлять переподписку по памяти. Обычно, переподписка по памяти ведет к деградации сервиса за счет интенсивного использования разделов подкачки, однако, Linux предоставляет инструменты, которые позволяют эффективно использовать переподписку по памяти, особенно, в случае однотипных виртуальных машин. Данные механизмы — KSM, ZRAM и ZSwap, обеспечивающие дедупликацию и сжатие страниц RAM, что позволяет уменьшить объем используемой физической оперативной памяти и обеспечить высокие коэффициенты переподписки (1:2 и выше) за счет повышенной нагрузки на CPU. Кроме того, применение высокопроизводительных SSD накопителей для разделов подкачки так же может положительно повлиять на качество сервиса.
Сеть доступа к хранилищам
В качестве сетевых карт для доступа к хранилищам рекомендуется применять современные сетевые карты, например, Intel X520-DA2. Оптимизация сетевого стека заключается в настройке поддержки jumbo frame и в распределении обработки прерываний очередей сетевой карты между ядрами CPU.
Сеть передачи данных
В качестве сетевых карт для передачи пользовательских данных рекомендуется применять современные сетевые карты с поддержкой большого количества очередей и в распределении обработки прерываний очередей сетевой карты между ядрами CPU.
Настройка виртуальных мостов
Виртуальные мосты используются для организации связи виртуальных сетевых устройств виртуальных машин с физическими сетевыми устройствами. Данные мосты могут быть организованы двумя способами — посредством Linux Bridge и Open Vswitch. Apache CloudStack поддерживает обе модели, однако, Linux Bridge в рамках данной топологии является оптимальным выбором в силу простоты настройки и более высокой производительности.
Пользовательский интерфейс самообслуживания
Apache CloudStack предоставляет два интерфейса управления виртуальными машинами, доступные пользователю — интерфейс API и браузерный UI, реализованный с помощью JavaScript и jQuery. В том случае, если ожидания пользователей к интерфейсу являются высокими, то необходима переработка интерфейса UI для того, чтобы добиться соответствия высоким ожиданиям пользователей. Также, доступен альтернативный пользовательский интерфейс CloudStack-UI, который предназначен именно для провайдеров, планирующих оказание платных услуг для широкого круга пользователей с применением Apache CloudStack. Интерфейс реализован с использованием Angular v4 и Material Design Lite и распространяется в соответствии с открытой лицензией Apache v2.0.
Технологии и системы
-
OpenVZ
Технология заключается в выполнении различных систем с разными настройками и корневой системой под одним ядром. Данная технология часто используется при предоставлении услуги VDS/VPS. Т.к. ядро по сути одно и тоже, потеря производительности минимальна, но выбор систем ограничивается дистрибутивами linux’а с одним ядром. Существует платный вариант данной системы с большим количеством функций: Virtuozzo. -
Xen
В основе лежит технология паравиртуализации. Вкратце: гостевая система специально подготавливается для работы с Xen, и соответственно получается довольно небольшая потеря производительности. В качестве гостевой системы может выступать Linux (ядро гостевой системы может отличатся от ядра основной системы), FreeBSD, NetBSD, OpenBSD, OpenSolaris, Plan 9 и другие. Также возможен запуск практически любой системе через технологии виртуализации Intel/AMD, но нужен процессор с поддержкой данных архитектур. Мой сервер, в отличии от ноутбука как оказалось не поддерживает данные технологии, по этому данный метод виртуализации расcматриваться не будет. -
VirtualBOX/VMWare/Qemu и подобные системы эмуляции.
Данные системы обеспечивают эмуляцию, ценой потери производительности, по этому они рассматриваться не будут.
Шаг 2: создаём виртуального друга
Внутри можно найти целый набор директорий. Этот набор определяется количеством вашей графической памяти, каждая поддиректория соответствует некоторому типу виртуального GPU. Файл в ней содержит информацию о памяти и разрешениях, поддерживаемых данным виртульным GPU. Если создание виртуального GPU с большой памятью с помощью вывода UUID в файл вам выдаёт непонятную ошибку, то у вас есть несколько опций. Сперва стоит зайти в BIOS и добавить видеопамяти, если возможно. Если это не работает, можно остановить ваш DM, переключиться на фреймбуфер, создать нужный vGPU оттуда, а затем вернуться в x11. К сожалению, такой способ приводит ко многим багам и не даёт добиться 60 FPS на моём ноутбуке. Альтернативный вариант состоит в том, чтобы создать vGPU поменьше, и использовать специальную программу для увеличения разрешения (CRU). Таким способом мне удалось добиться 60 FPS и багов и зависаний встретилось гораздо меньше.
Создать vGPU можно такой командой:
А удалить — такой:
Примечание переводчика:Сгенерировать UUID для vGPU можно с помощью команды без аргументов. Переменная ${vGPU_TYPE} обозначает один из типов, перечисленных в директории . Также стоит заметить, что vGPU при каждой перезагрузке надо создавать заново, они не сохраняются между запусками ОС.
Стенд
Стенды представляют собой следующий уровень организации топологии. В зависимости от фактической организации стендом может быть как комната, так и альтернативные сущности, например, ряд, стойка. То, что понимается под стендом, определяется в первую очередь следующими факторами:
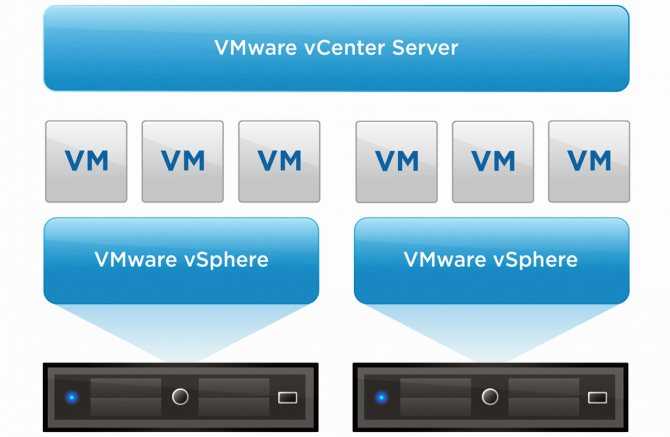
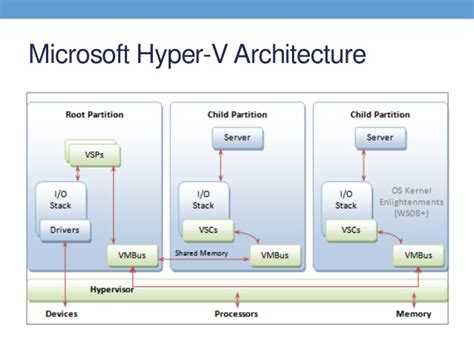
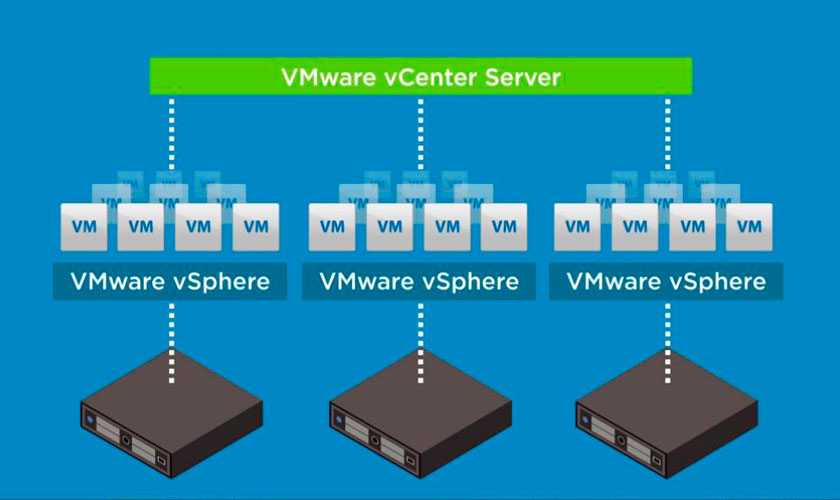
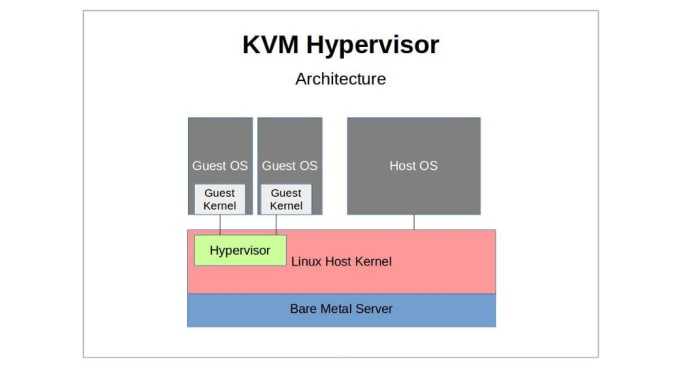

- количеством адресов, которые будут выделяться виртуальным машинам в рамках стенда, адреса, выделенные одному стенду не могут быть переданы другому стенду, например, при выделении стенду сети /22 (1024 адреса) необходимо обеспечить нахождение в стенде оборудования, которое сможет обслужить все данные адреса;
- резервирование — конкретный стенд может быть выделен для аккаунта;
- геометрическими соображениями;
- выделением доменов отказа.
Для сети из 1024 виртуальных машин вполне достаточно одного стенда, если все оборудование размещается в одной стойке, но может быть и 4, если существуют явные аргументы за разделение сети /22 на 4 x /24, например, при использовании разных устройств агрегации L3. В стенде может находиться произвольное количество кластеров, поэтому явных ограничений на планирование нет.
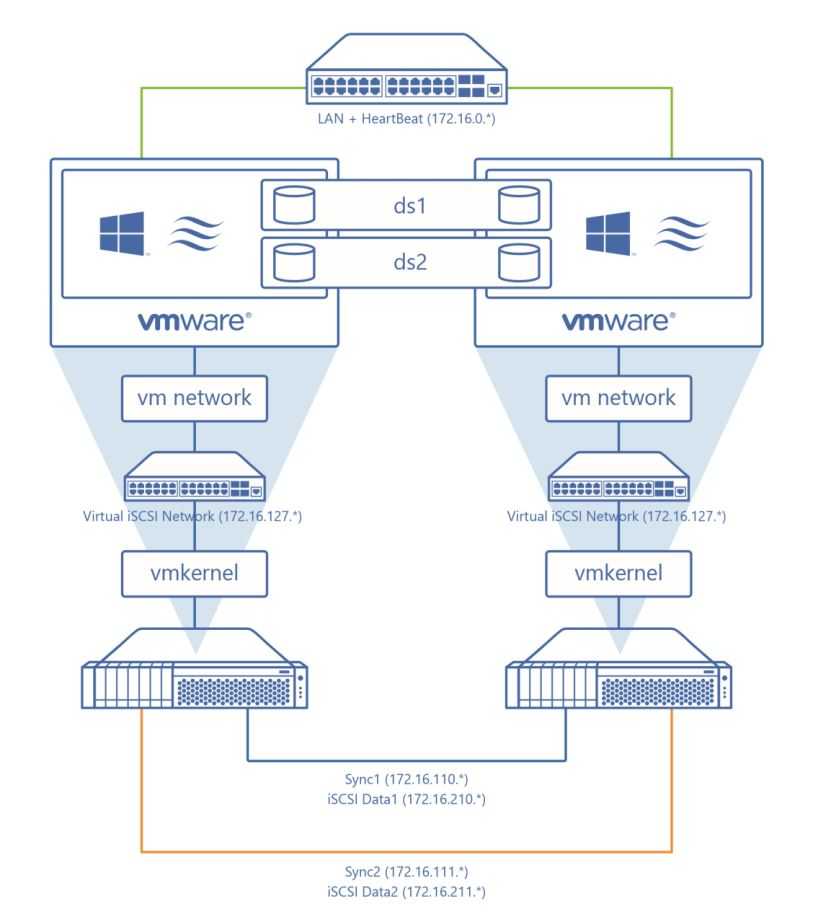
Сетевой Bridge для kvm
Настройка сети для виртуальных машин kvm может быть настроена различными способами. Я как минимум 3 наиболее популярных знаю:
- Виртуальные машины выходят во внешний мир через сам хост kvm, на котором настроен NAT. Этот вариант вам будет доступен сразу после установки kvm. Ничего дополнительно настраивать не надо, так как сетевой бридж для этого virbr0 уже будет добавлен в систему. А в правилах iptables будет добавлен MASQUERADE для NAT.
- Одна из виртуальных машин превращается в шлюз и через нее осуществляется доступ во внешний мир для всех виртуальных машин. Наиболее гибкий способ управления сетью для vm, но в то же время требует больше времени на настройку и набор знаний по работе с сетями.
- Для виртуальных машин kvm создается отдельный сетевой бридж во внешнюю сеть. Они напрямую получают в нее сетевой доступ.
Последний вариант наиболее простой и удобный, поэтому настроим сеть для виртуальных машин таким образом. Для этого нам нужно установить дополнительный пакет на host.
sudo apt install bridge-utils
Теперь на хосте приводим сетевые настройки в /etc/netplan к следующему виду.
network:
ethernets:
ens18:
dhcp4: false
dhcp6: false
version: 2
bridges:
br0:
macaddress: 16:76:1a:3b:be:03
interfaces:
- ens18
dhcp4: true
dhcp6: false
parameters:
stp: true
forward-delay: 4
Здесь будьте очень внимательны. Не выполняйте изменения сетевых настроек, не имея прямого доступа к консоли сервера. Очень высок шанс того, что что-то пойдет не так и вы потеряете удаленный доступ к серверу.
В предложенном наборе правил netplan у меня один сетевой интерфейс на хосте гипервизора — ens18. Он изначально получал настройки по dhcp. Мы добавили новый сетевой бридж br0, в него добавили интерфейс ens18. Так же мы указали, что br0 будет получать сетевые настройки по dhcp. Я указал mac адрес для того, чтобы он не менялся после перезагрузки. Такое может происходить. Адрес можно указать любой, не принципиально. Я сделал похожий на адрес физического сетевого интерфейса.
Теперь надо применить новые настройки.
sudo netplan apply
Сразу после этого вы потеряете доступ к серверу по старому адресу. Интерфейс ens18 перейдет в состав bridge br0 и потеряет свои настройки. А в это время бридж br0 получит новые сетевые настройки по dhcp. IP адрес будет отличаться от того, что был перед этим на интерфейсе ens18. Чтобы снова подключиться удаленно к гипервизору kvm, вам надо будет пойти на dhcp сервер и посмотреть, какой новый ip адрес ему назначен.
Если у вас нет dhcp сервера или вы просто желаете вручную указать сетевые настройки, то сделать это можно следующим образом.
network:
ethernets:
ens18:
dhcp4: false
dhcp6: false
version: 2
bridges:
br0:
macaddress: 16:76:1a:3b:be:03
interfaces:
- ens18
addresses:
- 192.168.25.2/24
gateway4: 192.168.25.1
nameservers:
addresses:
- 192.168.25.1
- 77.88.8.1
dhcp4: false
dhcp6: false
parameters:
stp: true
forward-delay: 4
В этом случае после применения новых настроек, гипервизор kvm будет доступен по адресу 192.168.25.2.
Обращайте внимание на все отступы в конфигурационном файле netplan. Они важны
В случае ошибок, настройки сети применены не будут. Иногда эта тема очень напрягает, так как не получается сразу понять, где именно в отступах ошибка. В этом плане yaml файл для настроек сети гипервизора как-то не очень удобен.
Далее еще один важный момент. Чтобы наш kvm хост мог осуществлять транзит пакетов через себя, надо это явно разрешить в sysctl. Добавляем в /etc/sysctl.d/99-sysctl.conf новый параметр. Он там уже есть, надо только снять пометку комментария.
net.ipv4.ip_forward=1
Применяем новую настройку ядра.
sudo sysctl -p /etc/sysctl.d/99-sysctl.conf net.ipv4.ip_forward = 1
С настройкой сети гипервизора мы закончили. На данном этапе я рекомендую перезагрузить сервер и убедиться, что все настройки корректно восстанавливаются после перезагрузки.
Редактируем выключенную машину vrr20:
Попадаем в редактирование (vi либо nano) xml-документа. Скроллим вниз до <interface type=’network’ – это сетевой интерфейс, который создается автоматически при инсталляции VRR:
Заменяем весь этот блок — <interface> на новый. В нём “type network”, заменяется на ‘direct’, а source network заменяем на source dev=eno1677736 (выясненное в пункте 9):
Обратите внимание на «slot=’0x03′» – делаем в нашем новом блоке таким же, как в том который было до этого, либо любое другое значение, но не повторяющееся больше ни разу в файле!
Проверить можно заранее сделав cat + grep по xml-файлу нашего vrr20.xml (ну или grep -i «slot=» /etc/libvirt/qemu/vrr20.xml)
Здесь видно, что для второго интерфейса можно взять, например, слот 0x08, т.к. как он ни разу в файле не встречается. Второй интерфейс может понадобиться для mgmt или резервирования доступности VRR. В VMWARE можно сделать, например, один сетевой интерфейс нашего Centos/Ubuntu в режиме NAT, второй — bridge.
Заканчиваем редактирование vrr20. Если редактор VI это будет Escape, shift + :, wq! + enter. В случае с nano — ctrl+O + Enter + Ctrl+X.
Начало работы
Настроить дисковые накопители
/dev/sda/dev/sdb/dev/sdbext4
- Размечаем диск, создавая новый раздел:
- Нажимаем клавишу o или g (разметить диск в MBR или GPT).
- Далее нажимаем клавишу n (создать новый раздел).
- И наконец w (для сохранения изменений).
- Создаем файловую систему ext4:
- Создаем директорию, куда будем монтировать раздел:
- Открываем конфигурационный файл на редактирование:
- Добавляем туда новую строку:
- После внесения изменений сохраняем их сочетанием клавиш Ctrl + X, отвечая Y на вопрос редактора.
- Для проверки, что все работает, отправляем сервер в перезагрузку:
- После перезагрузки проверяем смонтированные разделы:
/dev/sdb1/mnt/storage
Добавить новое хранилище в Proxmox
ДатацентрХранилищеДобавитьДиректория
- ID — название будущего хранилища;
- Директория — /mnt/storage;
- Содержимое — выделяем все варианты (поочередно щелкая на каждом варианте).
Добавить
Создать виртуальную машину
- Определяемся с версией операционной системы.
- Заранее закачиваем ISO-образ.
- Выбираем в меню Хранилище только что созданное хранилище.
- Нажимаем Содержимое ➝ Загрузить.
- Выбираем из списка ISO-образ и подтверждаем выбор нажатием кнопки Загрузить.
- Нажимаем Создать VM.
- Заполняем поочередно параметры: Имя ➝ ISO-Image ➝ Размер и тип жесткого диска ➝ Количество процессоров ➝ Объем оперативной памяти ➝ Сетевой адаптер.
- Выбрав все желаемые параметры нажимаем Завершить. Созданная машина будет отображена в меню панели управления.
- Выбираем ее и нажимаем Запуск.
- Переходим в пункт Консоль и выполняем установку операционной системы точно таким же образом, как и на обычный физический сервер.
Настроить автозапуск
- Щелкаем по названию нужной машины.
- Выбираем вкладку Опции ➝ Запуск при загрузке.
- Ставим галочку напротив одноименной надписи.
Start/Shutdown order
KVM
KVM (Kernel-based Virtual Machine), входящая в состав Red Hat Virtualization Suite, представляет собой комплексное решение для инфраструктуры виртуализации. KVM превращает ядро Linux в гипервизор. Он был введен в основную ветку ядра Linux с версии ядра 2.6.20.

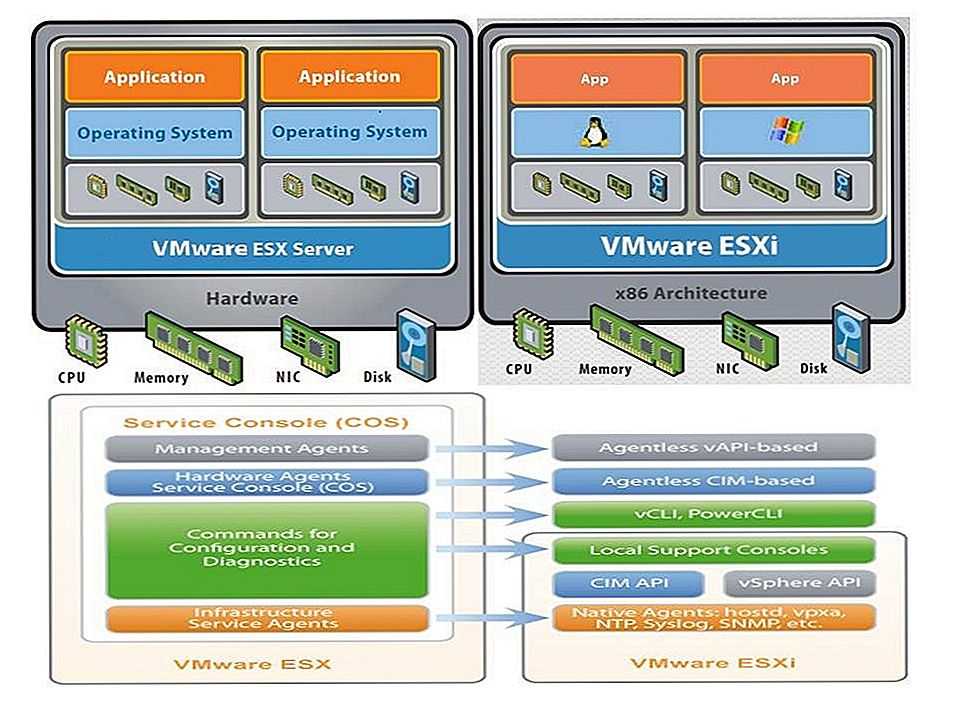
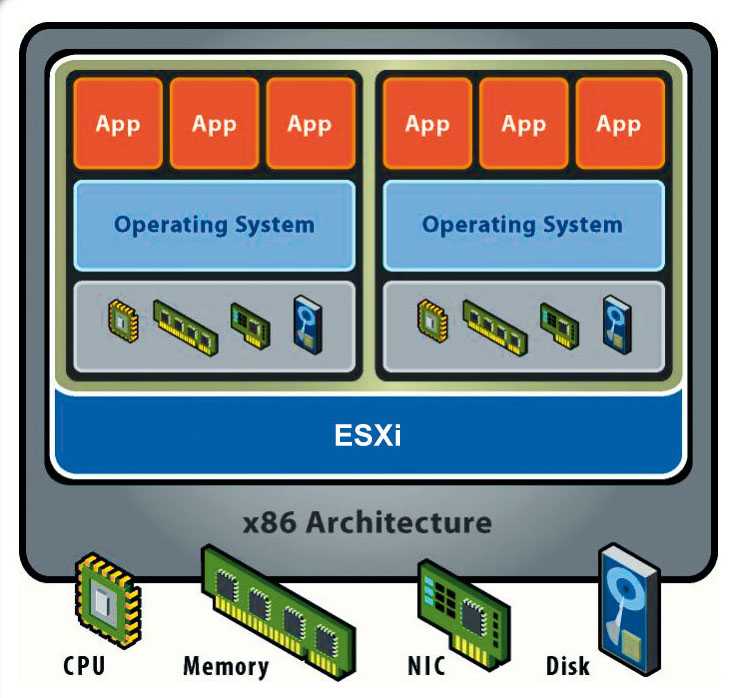
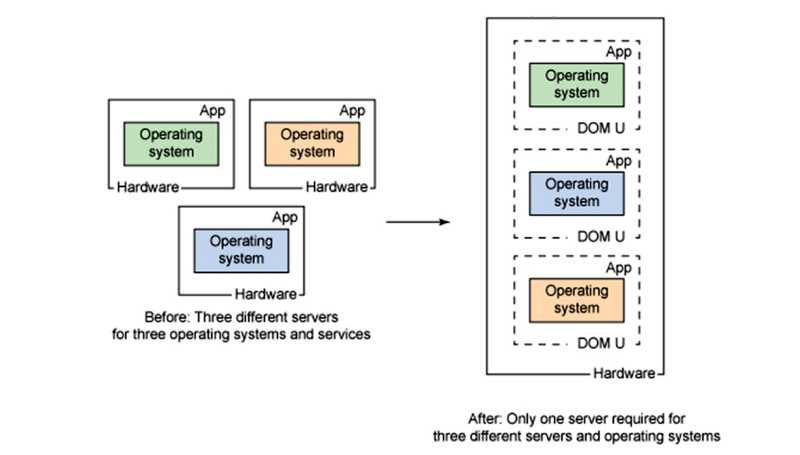
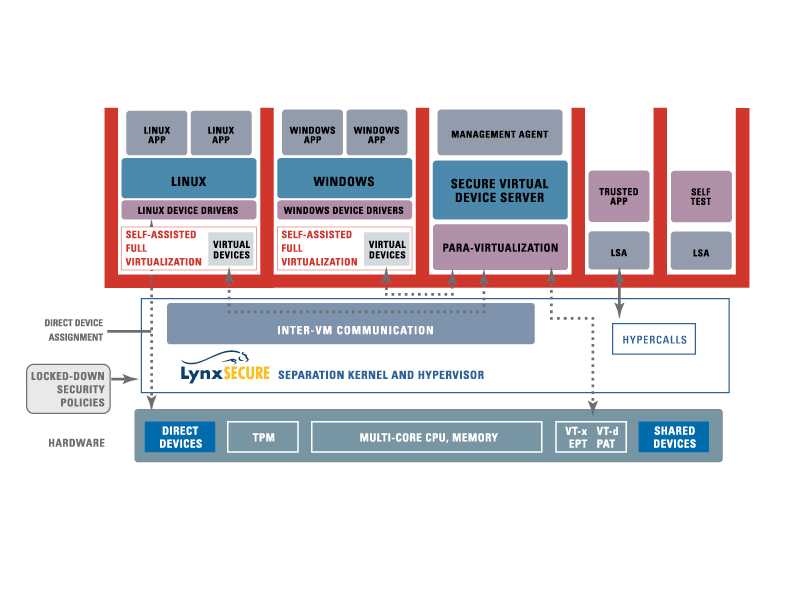
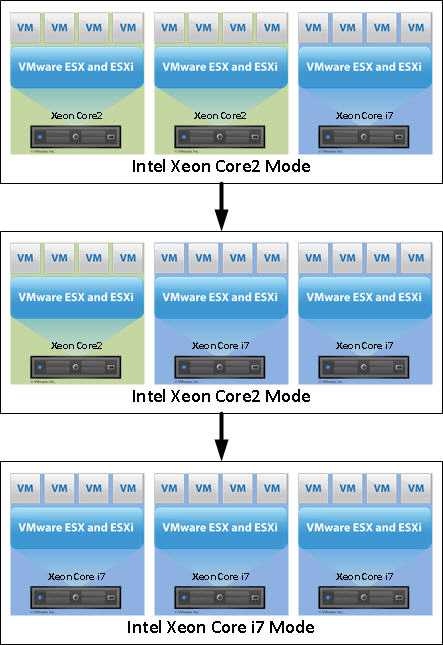
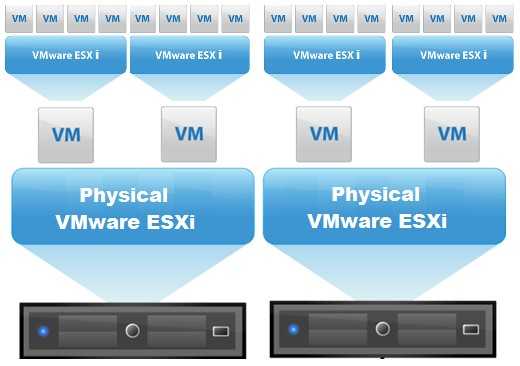
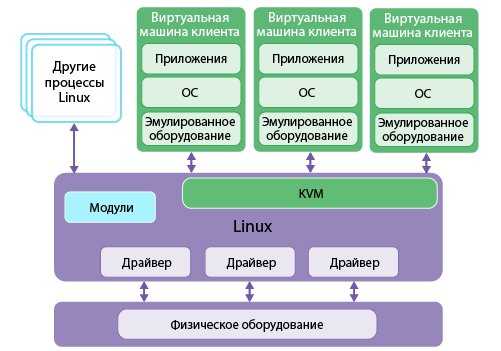
Функционал Red Hat KVM:
- Поддержка контейнеров
- Масштабируемость
- Overcommit ресурсов
- Disk I/O throttling
- Горячая замена виртуальных ресурсов
- Недорогое решение для виртуализации
- Red Hat Enterprise Virtualization программирование и API
- Живая миграция и миграция хранилища
- Назначение любых PCI устройств виртуальным машинам
- Интеграция Red Hat Satellite
- Поддержка восстановления после сбоя (Disaster Recovery)
Для получения более подробной информации прочтите это руководство по функционалу KVM.
Установка KVM в Ubuntu
Прежде чем начать установку гипервизора KVM в Ubuntu, проверим, поддерживает ли наш процессор виртуализацию. Для этого существует утилита kvm-ok. Если у вас нет ее в системе, установите пакет, который ее содержит.
sudo apt install cpu-checker sudo kmv-ok
Если ваш процессор не поддерживает виртуализацию, то получите сообщение:
INFO: Your CPU does not support KVM extensionsKVM acceleration can NOT be used
Если же все ОК, то информация будет следующая.
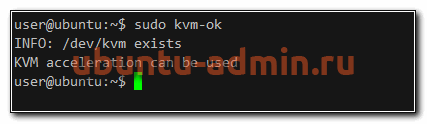
В этом случае можно приступать к установке виртуализации kvm.
sudo apt install qemu qemu-kvm libvirt-daemon-system virtinst libosinfo-bin
Я устанавливаю следующие компоненты kvm:
- qemu и qemu-kvm — сам гипервизор
- libvirt-daemon-system и virtinst — утилиты для управления гипервизором и виртуальными машинами
- libosinfo-bin — пакет с информацией о поддержки гипервизорами различных операционных систем.
Запустим и добавим в автозагрузку сервис управления kvm:
sudo systemctl enable --now libvirtd
В целом, все. Установка KVM на Ubuntu на этом и заканчивается. Можно проверить, загрузились ли у вас модули ядра kvm.
sudo lsmod | grep -i kvm kvm_intel 282624 0 kvm 663552 1 kvm_intel
Все в порядке, гипервизор kvm готов к работе.





