
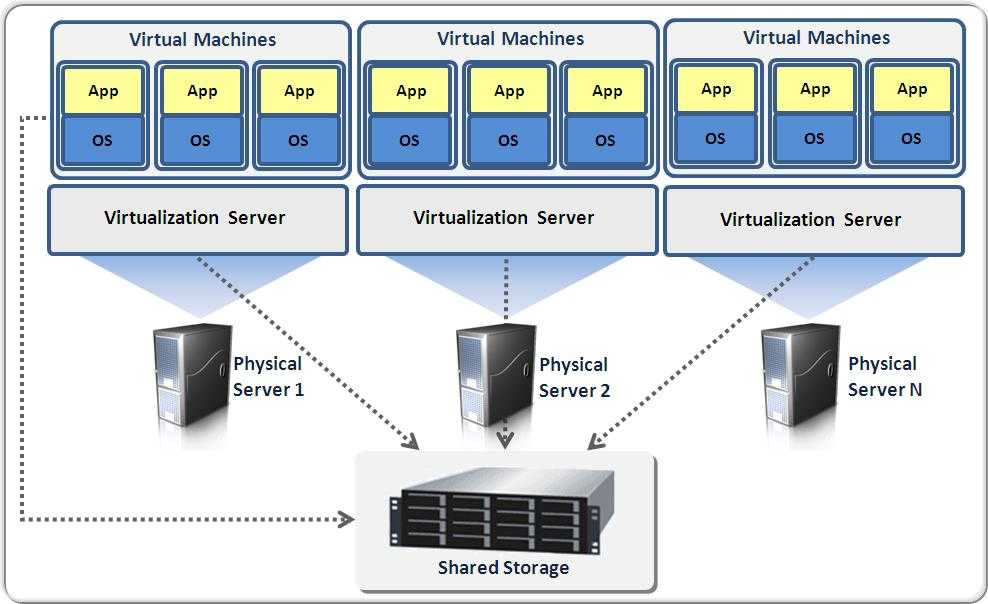
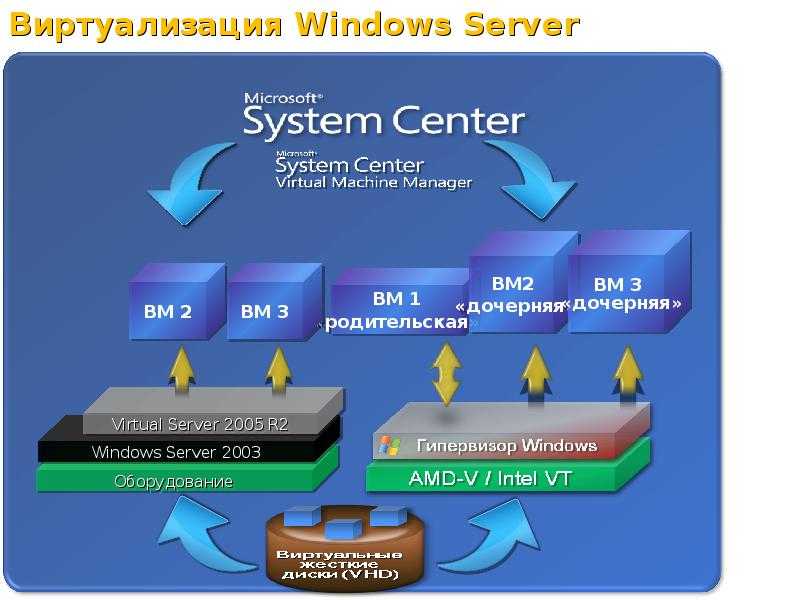
Архитектура подсистемы
Подсистема состоит из двух сервисов: vmwatch-master и vmwatch-node. Для взаимодействия между сервисами используется очередь сообщений. Очередь реализована с помощью библиотеки ZeroMQ по схеме PUSH-PULL.
Сервис vmwatch-master
Выполняется на узле, где расположена панель управления. Сервис принимает сообщения на указанном в конфигурационном файле IP-адресе и порту, обрабатывает их и выполняет вызовы соответствующих функций API панели управления для передачи информации об изменении состояния виртуальных машин.
Сервис vmwatch-node
Выполняется на каждом узле кластера. Сервис отправляет сообщения на указанный в конфигурационном файле IP-адрес и порт. Информацию об изменении состояния виртуальных машин сервис получает от сервиса libvirtd. В случае потери соединения с libvirtd сервис завершает работу.
Просмотр метрик производительности виртуальной машины
Служба Azure Monitor для виртуальных машин включает в себя набор диаграмм производительности, ориентированных на несколько ключевых показателей эффективности (KPI), которые помогают определить, насколько эффективно работает виртуальная машина. Чтобы получить доступ со своей виртуальной машины, выполните указанные ниже действия.
-
На портале Azure щелкните Группы ресурсов, выберите myResourceGroupMonitor, а затем в списке ресурсов выберите myVM.
-
На странице виртуальной машины в разделе Мониторинг выберите Аналитические сведения (предварительная версия) .
-
Выберите вкладку Производительность.
Эта страница содержит не только диаграммы использования производительности, но и таблицу с отображением каждого обнаруженного логического диска, его емкости, использования и общего среднего значения по каждому показателю.
Создание отчетов с помощью Operations Manager
После подключения VMM к Operations Manager можно просматривать и создавать отчеты. VMM предоставляет перечисленные ниже отчеты по умолчанию.
| Отчет | Сведения |
|---|---|
| Использование ресурсов | Сведения об использовании узлов виртуальных машин и других объектов. Предоставляет общие сведения об использовании емкости в центре обработки данных и помогает принимать решения в отношении ресурсов для обеспечения работы виртуальных машин. |
| Прогноз для группы узлов | Прогноз активности узлов на основе исторических данных об использовании пространства на диске, памяти, операций дискового ввода-вывода, операций сетевого ввода-вывода и загрузки ЦП. Чтобы использовать отчеты для прогноза, на сервере отчетов Operations Manager следует установить службы SQL Server Analysis Services. |
| Использование узлов | Этот отчет показывает число работающих на каждом узле виртуальных машин, а также среднюю и суммарную или максимальную загрузку процессоров, памяти и дискового пространства виртуальных машин. |
| Рост использования узлов | Содержит сведения о процентном изменении уровня использования ресурсов и количестве виртуальных машин, работающих на выбранных узлах в указанный период времени. |
| Энергосбережение | Сведения о количестве энергии, сэкономленной благодаря использованию функции энергосбережения. Можно просмотреть общие сведения об энергосбережении процессора (в часах) для диапазона дат и группы узлов, а также подробные сведения для каждого узла в группе узлов. |
| Прогноз использования сети SAN | Прогноз использования сети SAN на основе данных журнала. |
| Распределение виртуальных машин | Сведения о распределении виртуальных машин. |
| Использование виртуальных машин | Сведения об использовании ресурсов виртуальными машинами, включая среднюю и суммарную или максимальную загрузку процессоров, памяти и дискового пространства виртуальных машин. |
| Кандидаты для виртуализации | Позволяет определить физические компьютеры, которые являются подходящими кандидатами для преобразования в виртуальные машины. Этот отчет можно применить для определения редко используемых серверов и вывода средних значений для часто запрашиваемых счетчиков производительности ЦП, памяти и использования диска, наряду с конфигурациями оборудования, включая скорость процессора, число процессоров и общий объем ОЗУ. Область этого отчета можно ограничить компьютерами, которые отвечают указанным требованиям к ЦП и ОЗУ, и сортировать результаты по столбцам отчета. |
Наблюдение с помощью заданий VMM
Задание VMM создается для любого действия, изменяющего состояние управляемого объекта.
- Задания состоят из этапов, которые выполняются последовательно для совершения действия. Простые задания, такие как остановка виртуальной машины, содержат только один этап. Более сложные задания, в том числе запуск мастеров, могут содержать несколько заданий или группы заданий.
- Задания отслеживаются в представлении Задания консоли VMM. На вкладке Сведения представления Задания показано состояние каждого этапа задания.
- Каждое задание представлено одним или несколькими командлетами PowerShell VMM. С помощью PowerShell можно выполнить почти любую задачу VMM. В каждом мастере на странице Сводка есть кнопка Просмотреть скрипт, нажав которую, можно просмотреть командлеты, выполняющие запрошенное задание. Скрипты Windows PowerShell можно сохранять в библиотеке VMM, а затем просматривать и выполнять их в представлении Библиотека.
- Каждое задание VMM является независимым, то есть не зависит от состояния других заданий. Например, если выполняются задания по добавлению нескольких серверов узлов, сбой при добавлении одного из узлов не влияет на остальные задания.
После выполнения задания сохраняется запись аудита со списком изменений, внесенных заданием в объект VMM. Запись аудита можно просмотреть на странице Задания > Сведения > Отслеживание изменений. - Задания запускаются автоматически при выполнении задач в VMM или с помощью PowerShell. Некоторые выполняющиеся задания можно отменить, но другие, в том числе добавление узлов, а также системные задания, нельзя отменить, после того как они начали выполняться.
- Задания, завершившиеся сбоем, как правило, можно перезапустить, но имейте в виду перечисленные ниже особенности.
- Если несколько заданий перевели виртуальную машину в состояние сбоя, перезапустить можно только последнее задание.
- Для таких длительно выполняющихся заданий, как миграция виртуальной машины, периодически сохраняются промежуточные результаты, и действие перезапуска пытается возобновить выполнение задания с момента последнего известного состояния. Остальные задания перезапускаются с самого начала.
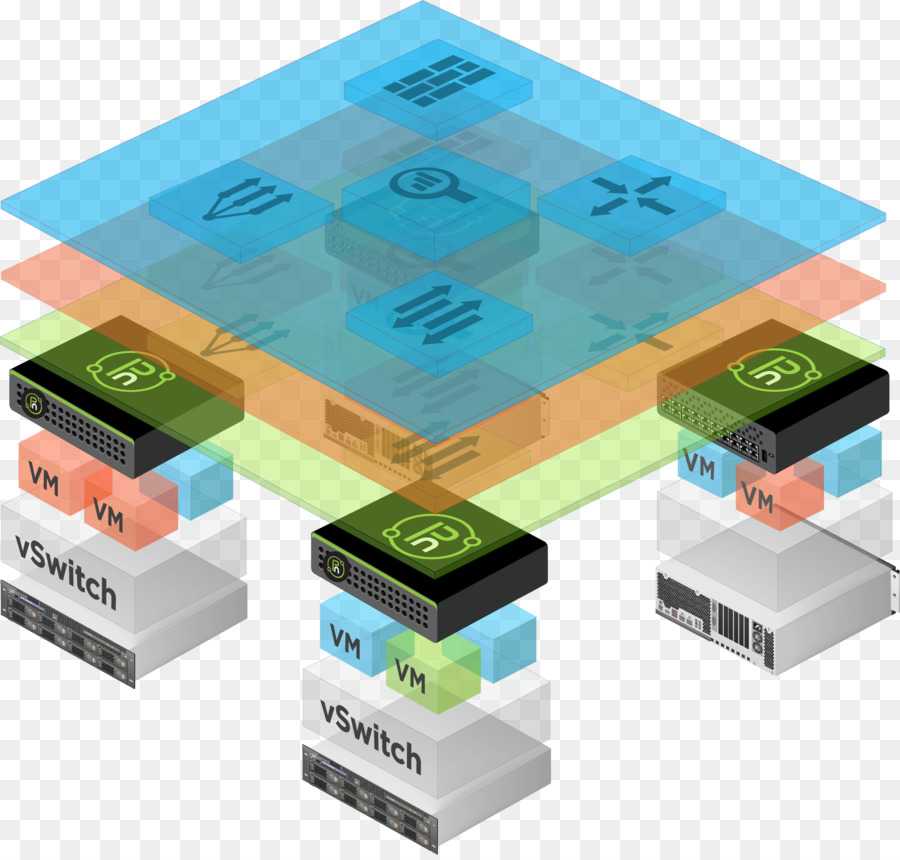
Готовая система мониторинга в VMmanager
VMmanager — платформа для построения виртуальной инфраструктуры с готовой системой мониторинга, которая включает в себя набор элементов.
Агент сбора метрик получает данные с виртуальных и физических машин, а затем передает их в сервисы статистики, мониторинга в режиме реального времени, и алармов (для отслеживания пиковых показателей).
Сервис нотификаций отслеживает все события в базе данных платформы: создание, удаление, редактирование данных.
Сервисы самодиагностики платформы отслеживают метрики мастер-узла и события из сервиса нотификаций.
Time-series база данных (Graphite) для хранения статистики.
Быстрые KV-хранилища (consul/redis) для хранения кратковременной информации о нотификациях и алертах.
Визуализация — красивый и удобный интерфейс для мониторинга в режиме реального времени и отображения статистики за выбранный период.
Интерфейс
Список виртуальных машин и узлов
В списке виртуальных машин можно посмотреть информацию о самых важных параметрах ВМ в реальном времени и оперативно оценить их состояние.
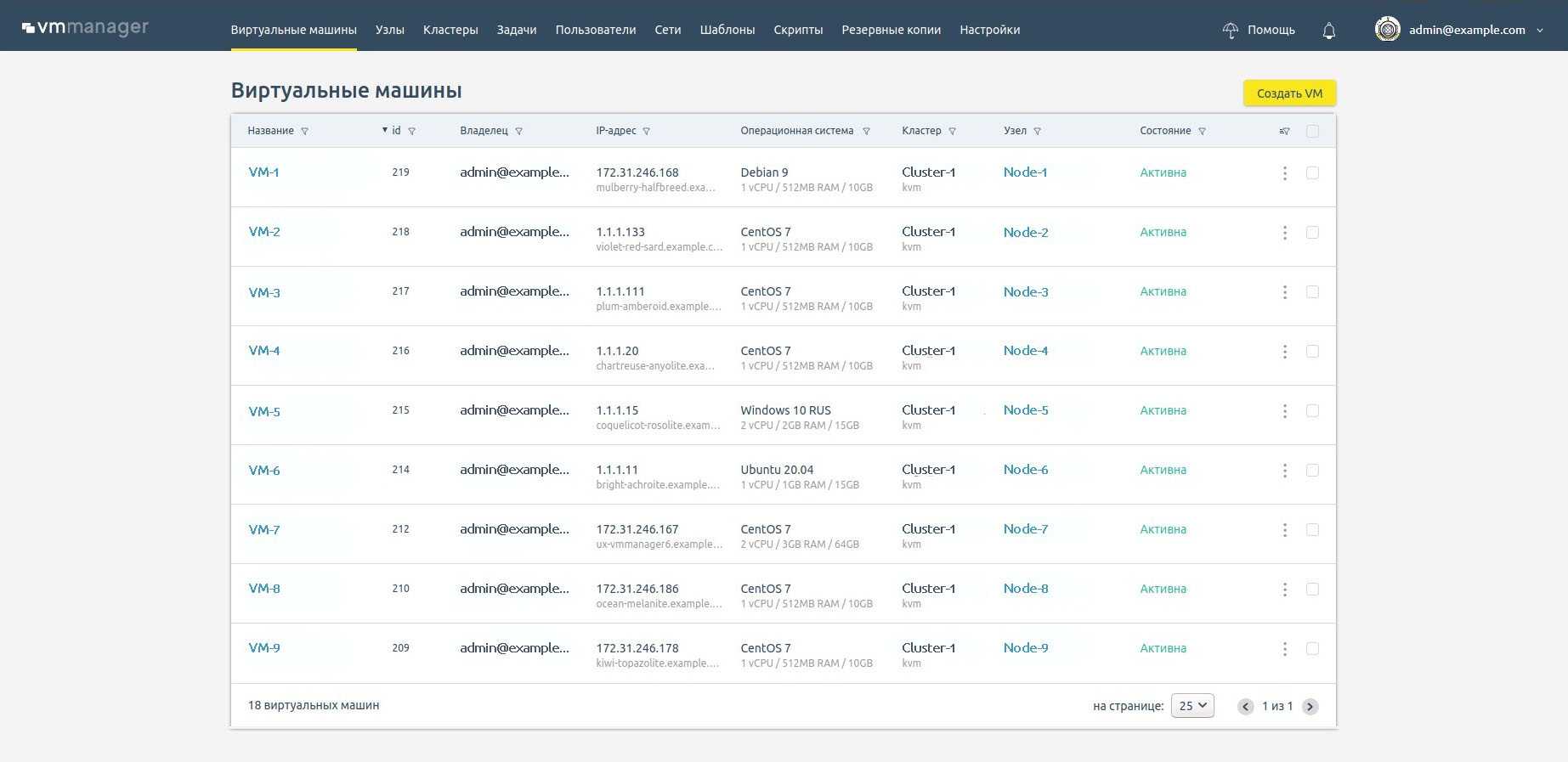
Список виртуальных машин
Аналогичная информация есть по физическим серверам в списке узлов.
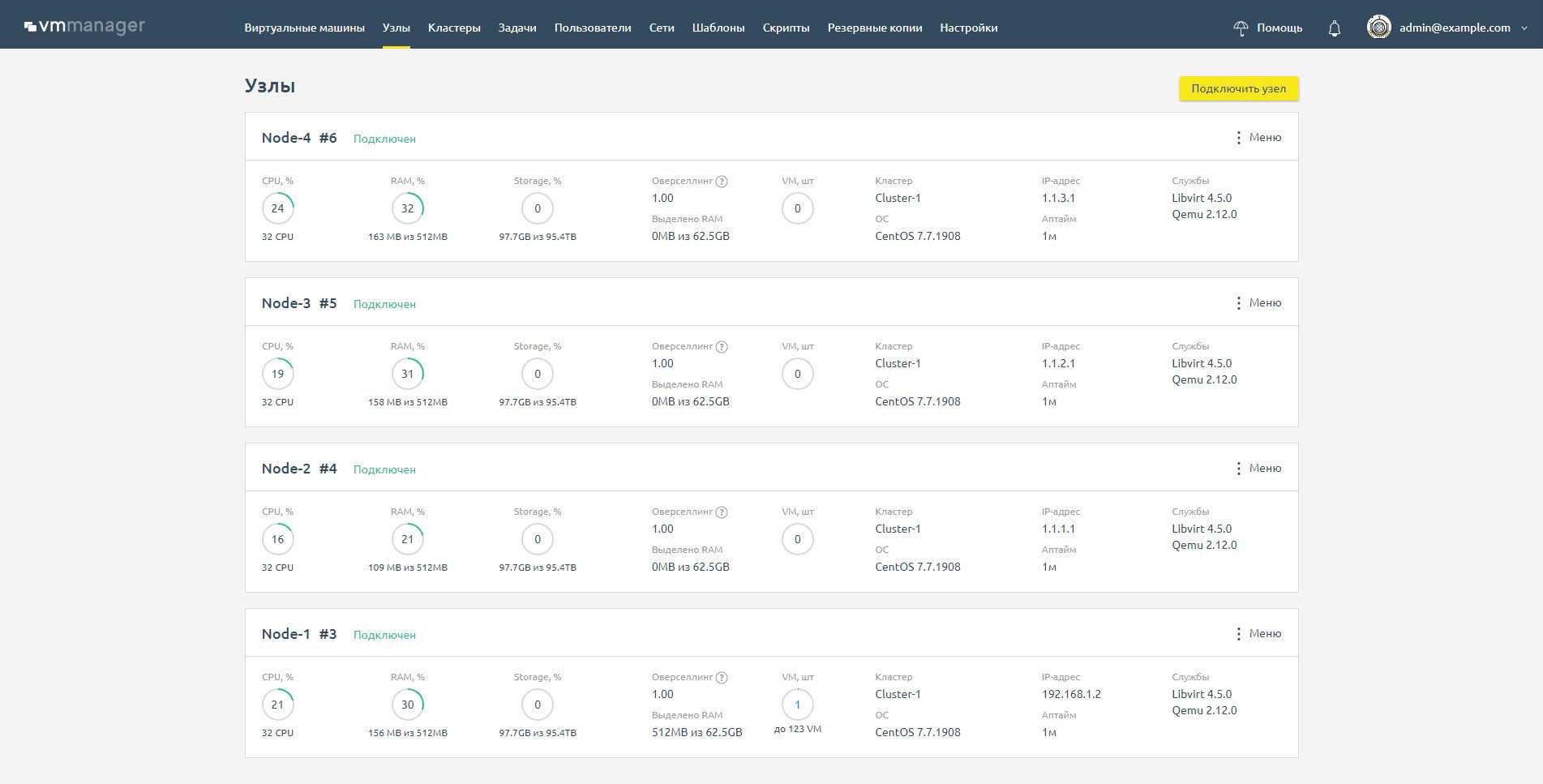
Список узлов
Карточка виртуальной машины
На карточке представлена детальная информация по всем параметрам виртуальной машины. Можно посмотреть статистику за определенный период и проанализировать изменения в инфраструктуре. В карточке можно управлять параметрами виртуальной машины:

- Сетевыми настройками,
- Доменным именем,
- Параметрами VNC-подключения,
- Резервными копиями,
- Тонкими настройками libvirt-домен: вес CPU, IO, ограничения по трафику, режим эмуляции оборудования.
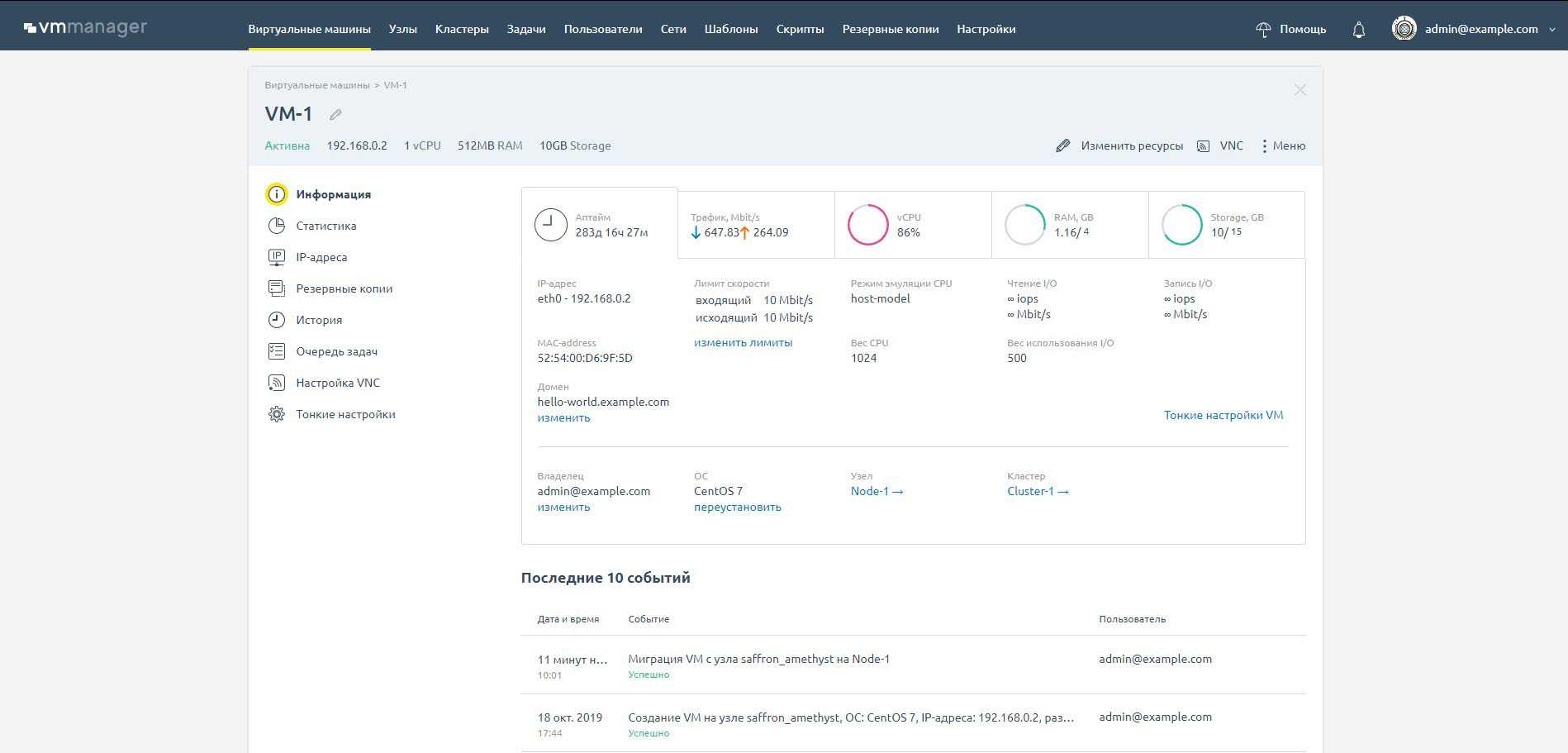
Карточка виртуальной машины
Карточка узла
На карточке узла представлены данные о количестве активных, остановленных, поврежденных виртуальных машин, и прогноз, сколько еще ВМ примерно вместит физический сервер. Это помогает лучше оценивать имеющиеся физические ресурсы и планировать закуп оборудования.
В истории изменений фиксируются данные по всем последним событиям: время их запуска, продолжительность, статус задачи (в очереди, готово, выполняется), и имя пользователя, который их запустил. Можно посмотреть принадлежность сервера к кластеру и гостевые ВМ, которые исполняются на конкретном оборудовании. Всё это помогает обеспечить прозрачность бизнес-процессов компании.
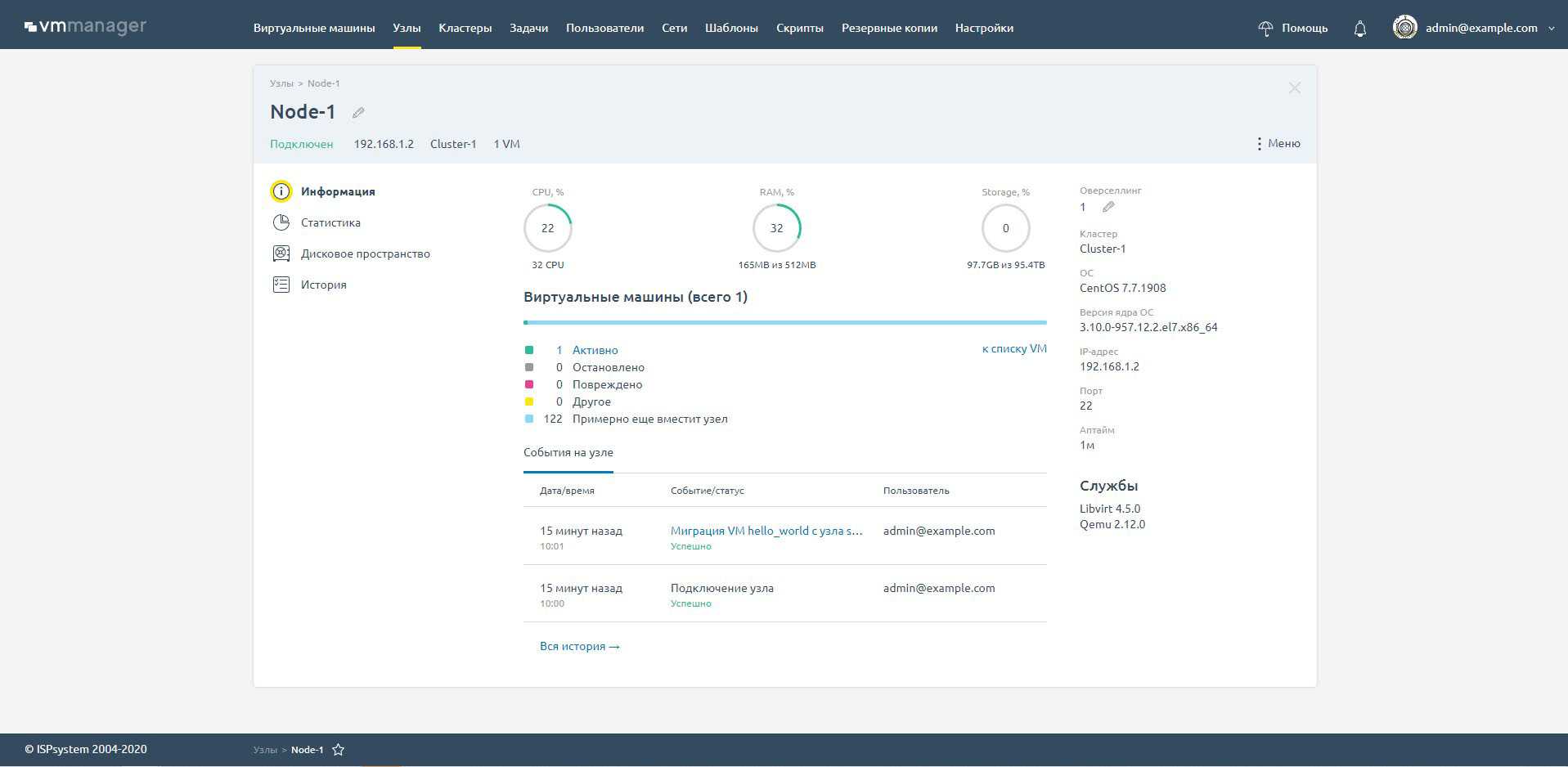
Карточка узла
Дашборд
На дашборде собраны основные показатели системы. Его можно вывести на отдельный монитор, чтобы иметь возможность быстро оценивать текущее состояние инфраструктуры и оперативно реагировать на инциденты.
Здесь представлены и новые параметры. Например, виджет самодиагностики платформы, статистика по кластеру, количество доступных IP-адресов, версия VMmanager и ченчлог продукта.
Есть список задач, разбитый по статусам: завершено, выполняется, в очереди на обработку, ошибка.
Можно посмотреть топ самых нагруженных узлов и отредактировать на них настройки оверселлинга.
Из дашборда можно перейти на список задач, кластер, ноду или виртуальную машину, чтобы приблизится к проблеме и детальнее оценить ситуацию.
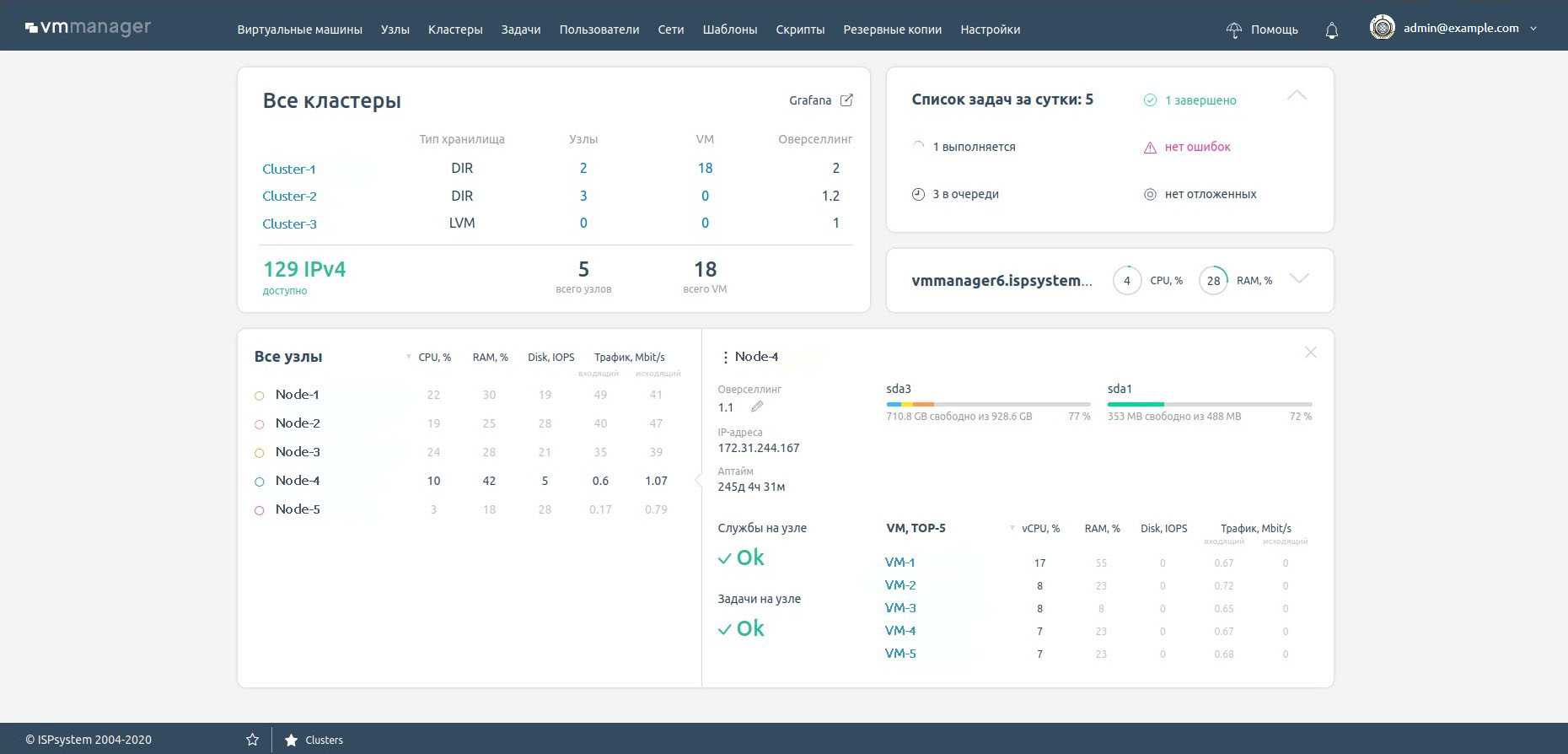
Дашборд
Grafana
Благодаря интеграции с Grafana, можно гибко настроить визуализацию параметров в системе, статистику и анализировать инциденты.
Это работающий прямо из коробки контейнер с Grafana со всеми интеграциями, связями с базами данных и преднастроенным демо-дашбордом. Для осуществления мониторинга достаточно создать собственный дашборд, выбрать интересующую сущность, параметры и способ визуализации. Всё настраивается в простом графическом интерфейсе в пару кликов. Больше информации — в наше документации: как работать с Grafana в VMmanager.
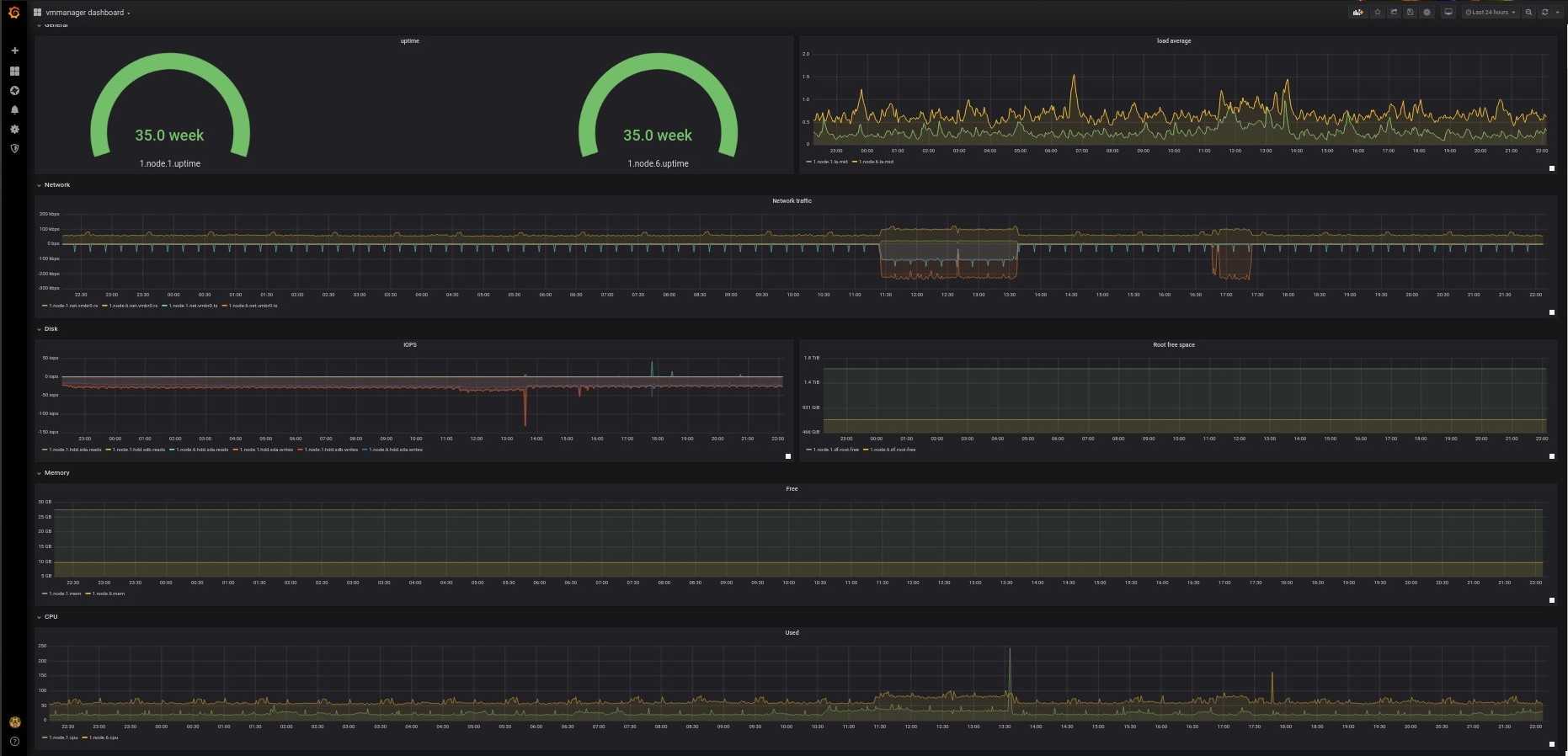
Преднастроенный дашборд в Grafana
Уведомления
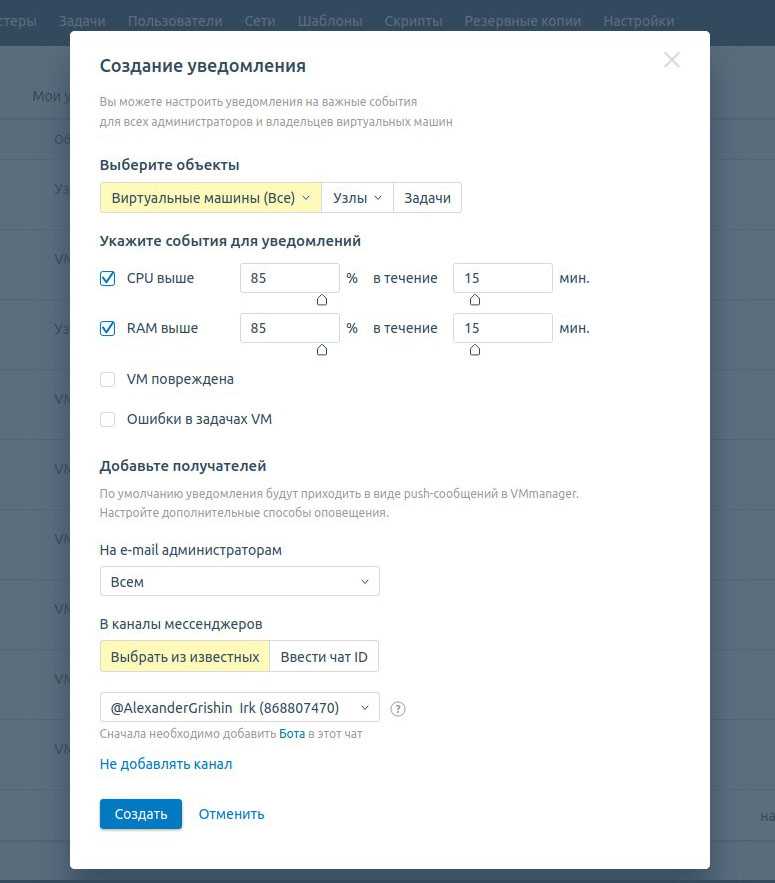
Сервис уведомлений помогает вовремя реагировать на опасные инциденты. Например, если у провайдера перестанут выдаваться ВМ из биллинга, он сразу узнает об этом. А своевременные действия специалистов минимизируют негативное влияние на бизнес.


Сервис позволяет гибко задавать параметры пиков и событий. В нём вы можете настроить уведомления
- По параметрам: CPU, RAM, STORAGE, IOPS;
- По задачам в платформе: повреждение ВМ, недоступность сервера, ошибки в задачах на сервере, перезагрузка, ошибки создания ВМ и другие.
Центр уведомлений
Уведомления можно получать в интерфейсе продукта, на почту и в Telegram. Подробнее об архитектуре сервиса рассказал Back-end разработчик Дмитрий Сыроватский в статье «Как мы написали сервис уведомлений».
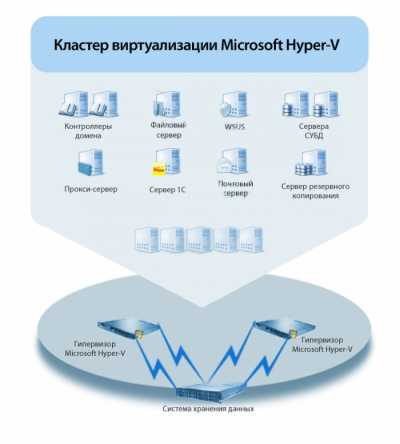
Microsoft Hyper-V
В «магическом квадранте» Gartner по виртуализации серверной инфраструктуры х86 (Magic Quadrant for x86 Server Virtualization Infrastructure), выпущенном в июле 2015 года, лидируют Micrоsoft и VMware. Xen и KVM представлены вендорами Citrix и Red Hat.способны отлично работать под Hyper-VLinux Integration Services 4.0 for Hyper-Vпакет драйверов, утилит и улучшений для гостевых ОС LinuxОсобенности Microsoft Hyper-V в Windows Server 2012 R2 Datacenter Edition
| Максимальное число одновременно работающих ВМ | 1024 |
| Максимальное число процессоров на хост-сервер | 320 |
| Число ядер на процессор хоста | Не ограничено |
| Максимальное число виртуальных процессоров (vCPU) на хост-сервер | 2048 |
| Максимальная емкость оперативной памяти на хост-сервер | 4 Тбайт |
| Память на одну ВМ | 1 Тбайт |
| Виртуальных процессоров на ВМ | 64 vCPU |
| Динамическое перераспределение памяти | Dynamic Memory |
| Дедупликация страниц памяти | Нет |
| Поддержка больших страниц памяти (Large Memory Pages) | Да |
| Централизованное управление | Да, System Center Virtual Machine Manager (SCVMM) |
| Интеграция с Active Directory | Да (через SCVMM) |
| Снимки ВМ (snapshot) | Да |
| Управление через браузер | Через портал самообслуживания |
| Обновления хост-серверов/ гипервизора | Да |
| Управление сторонними гипервизорами | Да, управление VMware vCenter и Citrix XenCenter |
| Обновление ВМ | Да (WSUS, SCCM, VMST) |
| Режим обслуживания (Maintenance Mode) | Да |
| Динамическое управление питанием | Да, Power Optimization |
| API для резервного копирования | Да, VSS API |
| Шаблоны виртуальных машин (VM Templates) | Да |
| Профили настройки хостов (Host Profiles) | Да |
| Миграция физических серверов в виртуальные машины (P2V) | Нет |
| Горячая миграция виртуальных машин | Да, без общего хранилища (Shared Nothing), поддержка сжатия и SMB3, неограниченное число одновременных миграций |
| Горячая миграция хранилищ ВМ | Да |
| Профили хранилищ | Да |
| Поддержка USB | Нет (за исключением Enhanced Session Mode) |
| Горячее добавление устройств | Только устройства хранения и/или память |
| Устройства Floppy в ВМ | 1 |
| Сетевые адаптеры/интерфейсы | 8 NIC |
| Виртуальные диски IDE | 4 |
| Емкость виртуального диска | 64 Тбайта для VHDX |
| Максимальное число узлов в кластере | 64 |
| Виртуальных машин в кластере | 8000 |
| Функции высокой доступности при сбоях хост-серверов | Failover Clustering |
| Перезапуск виртуальных машин в случае сбоя на уровне гостевой ОС | Да |
| Обеспечение доступности на уровне приложений | Да (Failover Clustering) |
| Непрерывная доступность ВМ | Нет |
| Репликация виртуальных машин | Да, Hyper-V Replica |
| Автоматическое управление ресурсами кластера | Да, Dynamic Optimization |
| Пулы ресурсов | Да (Host Groups) |
| Проверка совместимости процессоров при миграциях машин | Да, Processor Compatibility |
| Поддерживаемые хранилища | SMB3, FC, Virtual FC, SAS, SATA, iSCSI, FCoE, Shared VHDX |
| Кластерная файловая система | CSV (Cluster Shared Volumes) |
| Поддержка Boot from SAN | Да (iSCSI, FC) |
| Динамическое выделение емкости хранения (Thin Provisioning) | Да, Dynamic Disks |
| Загрузка с USB | Нет |
| Хранилища на базе локальных дисков серверов | Storage Spaces, Tiered Storage |
| Уровни обслуживания для подсистемы ввода-вывода | Да, Storage QoS |
| Поддержка NPIV | Да (Virtual Fibre Channel) |
| Поддержка доступа по нескольким путям (multipathing) | Да (DSM и SMB Multichannel) |
| Кэширование | Да, CSV Cache |
| API для интеграции с хранилищами | Да, SMI-S/SMP, ODX, Trim |
| Поддержка NIC Teaming | Да |
| Поддержка Private VLAN | Да |
| Поддержка Jumbo Frames | Да |
| Поддержка Network QoS | Да |
| Поддержка IPv6 | Да |
| Мониторинг трафика | Да |
Данные мониторинга
Виртуальные машины в Azure создают журналы и метрики , как показано на следующей схеме.
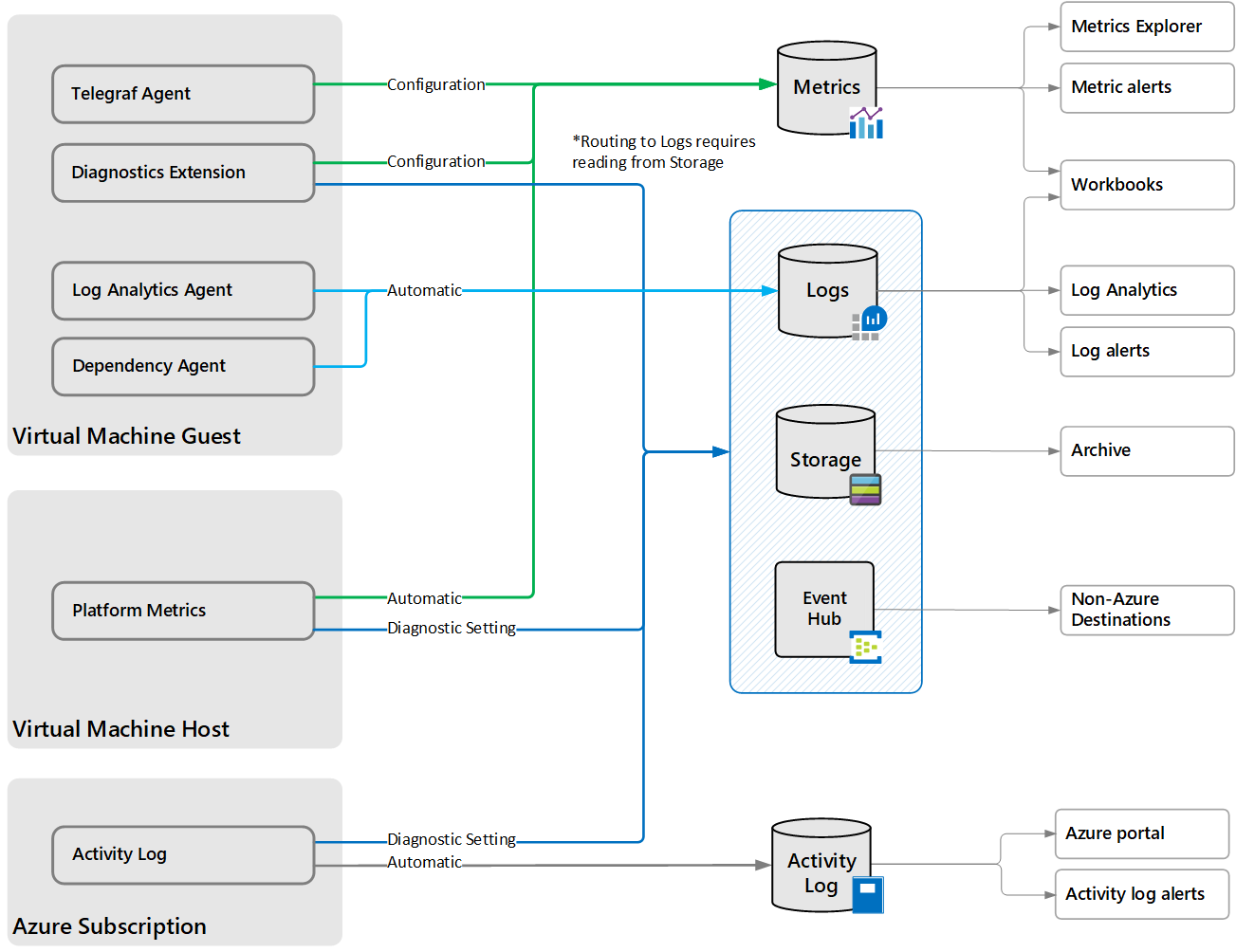
Компьютер виртуальной машины
Виртуальные машины Azure создают приведенные ниже данные для компьютера виртуальной машины так же, как и другие ресурсы Azure (см. статью ).
- Метрики платформы — числовые значения, которые автоматически собираются через регулярные интервалы и описывают некоторый аспект ресурса на определенный момент времени. Метрики платформы собираются для компьютера виртуальной машины, но для сбора метрик для операционной системы на виртуальной машине требуется расширение диагностики.
- Журнал действий — предоставляет полезные сведения об операциях с каждым ресурсом Azure в подписке извне (плоскость управления). Для виртуальной машины сюда входят такие сведения, как время запуска и изменения конфигурации.
Операционная система на виртуальной машине
Для сбора данных из операционной системы на виртуальной машине требуется агент, который выполняется локально на каждой виртуальной машине и отправляет данные в Azure Monitor. Для Azure Monitor доступно несколько агентов, каждый из которых собирает различные данные и записывает их в разные места. Подробное сравнение различных агентов см. в статье Обзор агентов Azure Monitor.
- — доступен для виртуальных машин в Azure, других облачных средах и локальной среде. Собирает данные в журналах Azure Monitor. Поддерживает решения VM Insights и мониторинга. Это тот же агент, который используется для System Center Operations Manager.
- — собирает данные по процессам, выполняемым на виртуальной машине, и их зависимостям. Использует агент Log Analytics для передачи данных в Azure и поддерживает решения VM Insights, Сопоставление служб и Wire Data 2.0.
- — доступно только для виртуальных машин Azure Monitor. Может собирать данные в несколько мест, но в основном используется для сбора данных по производительности операционной системы Windows на виртуальных машинах в метрики Azure Monitor.
- Агент Telegraf — собирает данные по производительности виртуальных машин Linux в метрики Azure Monitor.
видны узлы
Оповещения в Azure Monitor заранее уведомляют вас об обнаружении определенных состояний в данных мониторинга и могут выполнять действия, например запускать приложение логики или вызывать веб-перехватчик. Правила генерации оповещений определяют логику, используемую для определения того, когда необходимо создавать оповещения. Azure Monitor собирает данные, используемые правилами генерации оповещений, но вам необходимо создать правила для определения условий срабатывания оповещений в подписке Azure.
В следующих разделах описываются типы правил генерации оповещений и рекомендации по их использованию. Эта рекомендация основана на функциональности и стоимости типа правила генерации оповещений. Подробные сведения о ценах на оповещения см. в разделе Цены на Azure Monitor.
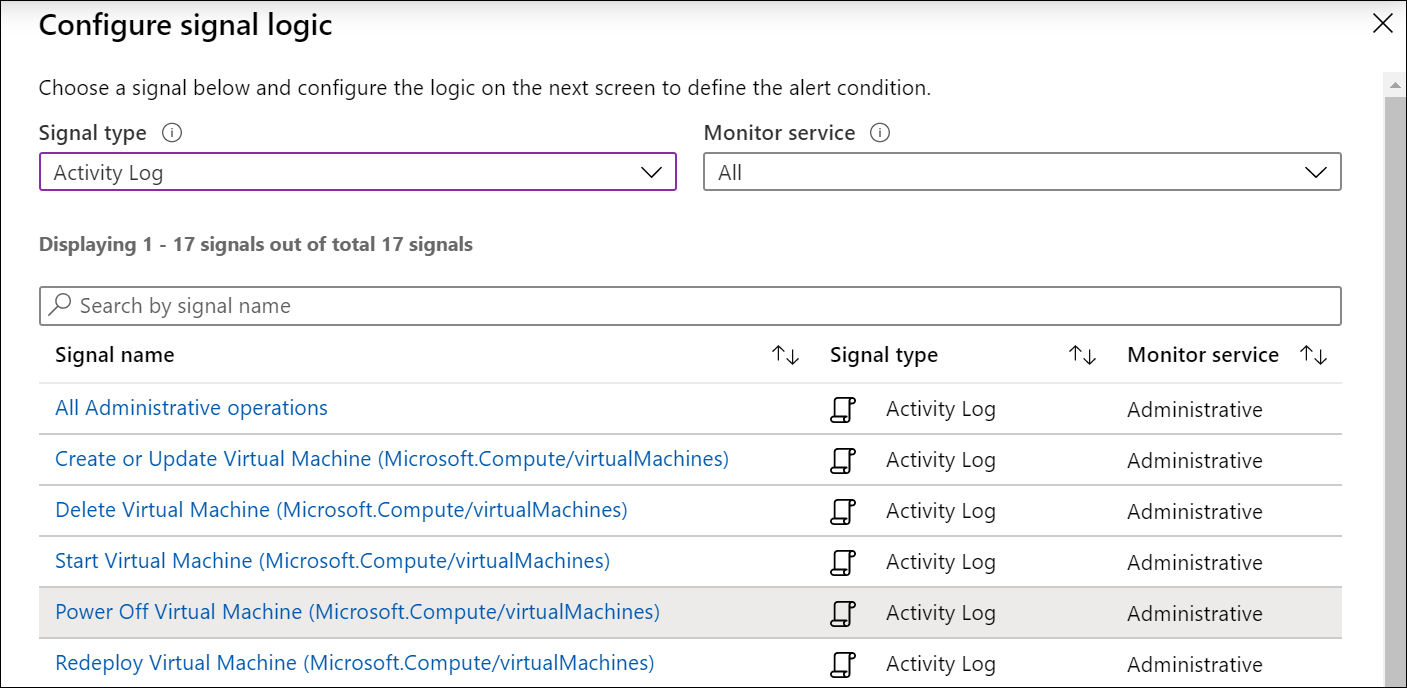
Правила генерации оповещений журнала действий
Правила генерации оповещений для журнала действий срабатывают при создании в журнале действий записи, соответствующей определенным условиям. Они бесплатны, поэтому их следует использовать в первую очередь, если нужная логика находится в журнале действий.
Целевым ресурсом для оповещений журнала действий может быть определенная виртуальная машина, все виртуальные машины в группе ресурсов или все виртуальные машины в подписке.
Например, создайте оповещение об остановке критически важной виртуальной машины, выбрав Отключить питание виртуальной машины в качестве имени сигнала
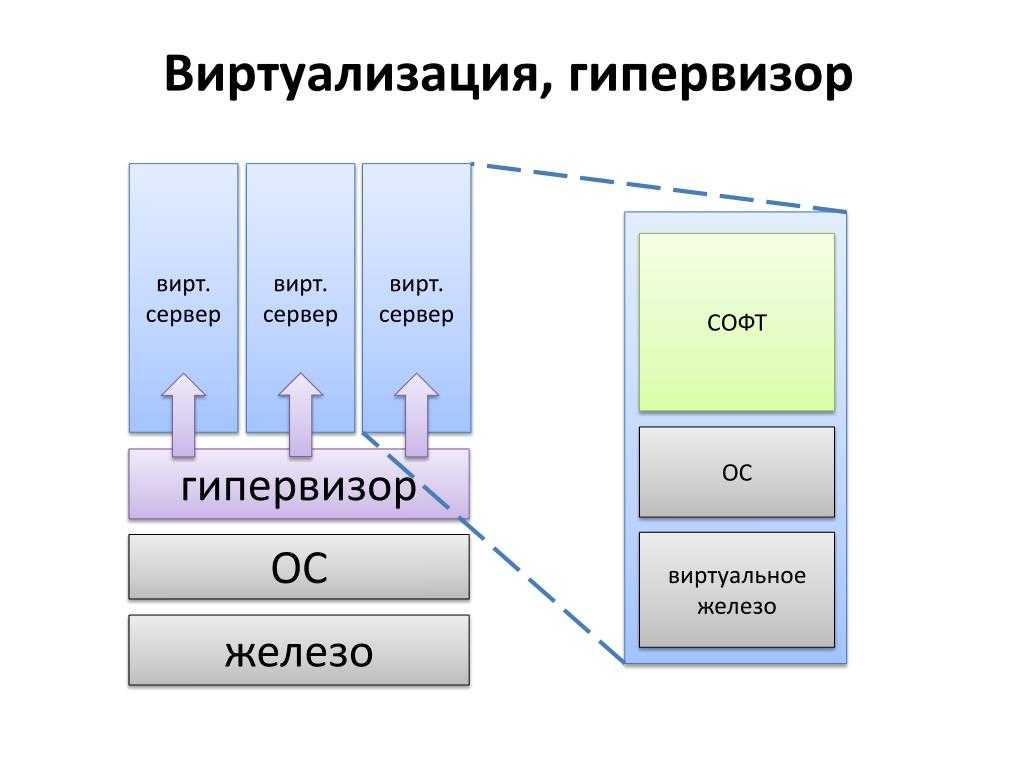
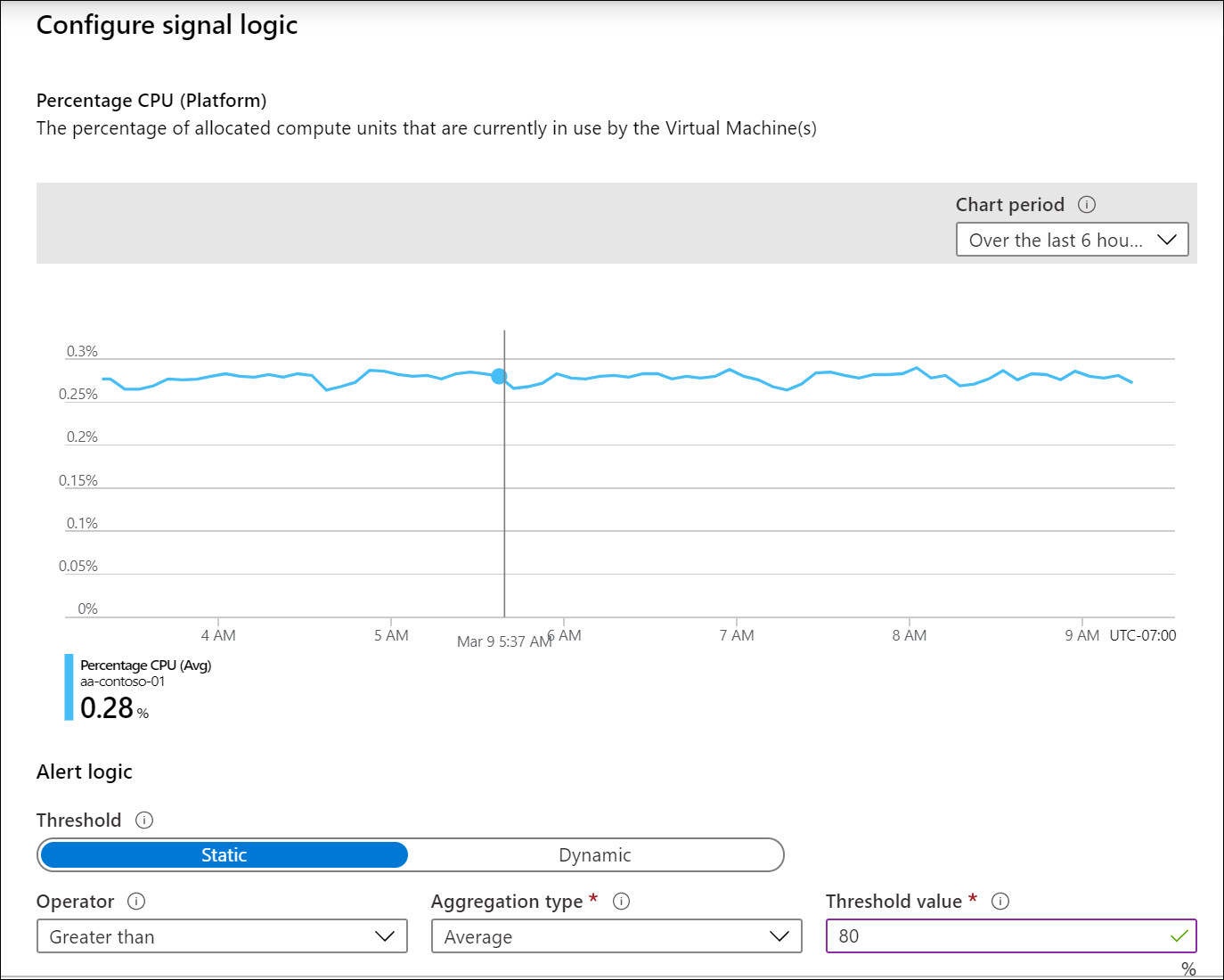
Правила генерации оповещений метрик
Правила генерации оповещений о метриках срабатывают в случае превышения порогового значения метрикой. Вы можете определить конкретное пороговое значение или разрешить Azure Monitor динамически определять пороговое значение на основе исторических данных. Используйте оповещения о метриках для данных метрик, когда это возможно, так как они дешевле и оперативнее, чем правила генерации оповещений для журналов. Они также являются оповещениями с отслеживанием состояния, то есть разрешаются, когда значение метрики опускается ниже порогового значения.
Целевым ресурсом для оповещений о метриках может быть определенная виртуальная машина или все виртуальные машины в группе ресурсов.
Например, чтобы создать оповещение о превышении определенного значения процессором виртуальной машины, создайте правило генерации оповещений о метрике с типом сигнала Загрузка ЦП. Задайте конкретное пороговое значение или разрешите Azure Monitor задавать пороговое значение динамически.






Оповещения журналов
Правила генерации оповещений для журналов срабатывают, когда результаты запланированного запроса к журналу соответствуют определенным условиям. Оповещения о запросах к журналам — наиболее дорогой и наименее оперативный тип правил генерации оповещений, но они обеспечивают доступ к наиболее разнообразным данным и позволяют выполнять сложную логику, которая невозможна при использовании других правил генерации оповещений.
Целевым ресурсом для запроса к журналу является рабочая область Log Analytics. Фильтрация определенных компьютеров осуществляется в запросе.
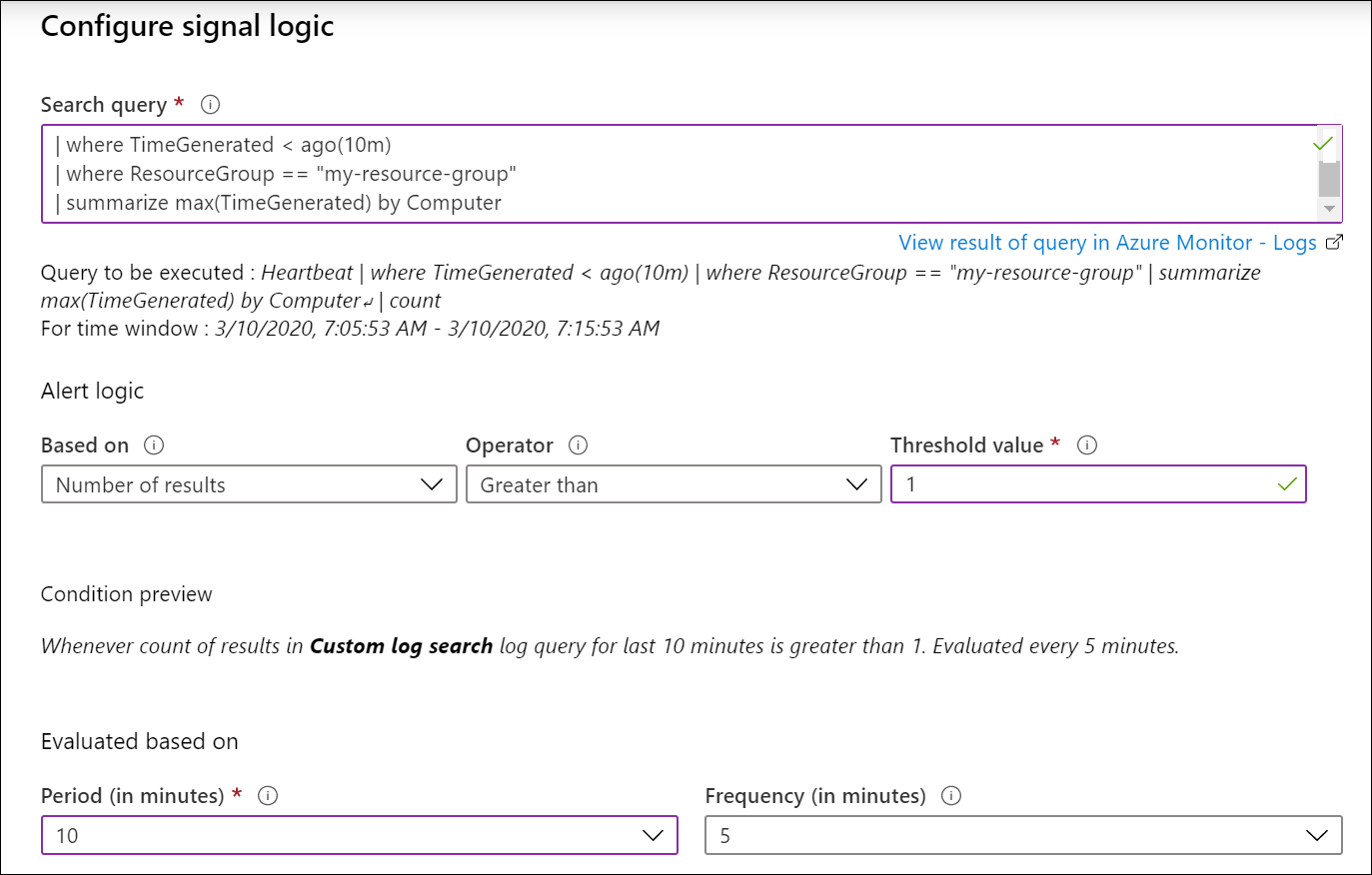
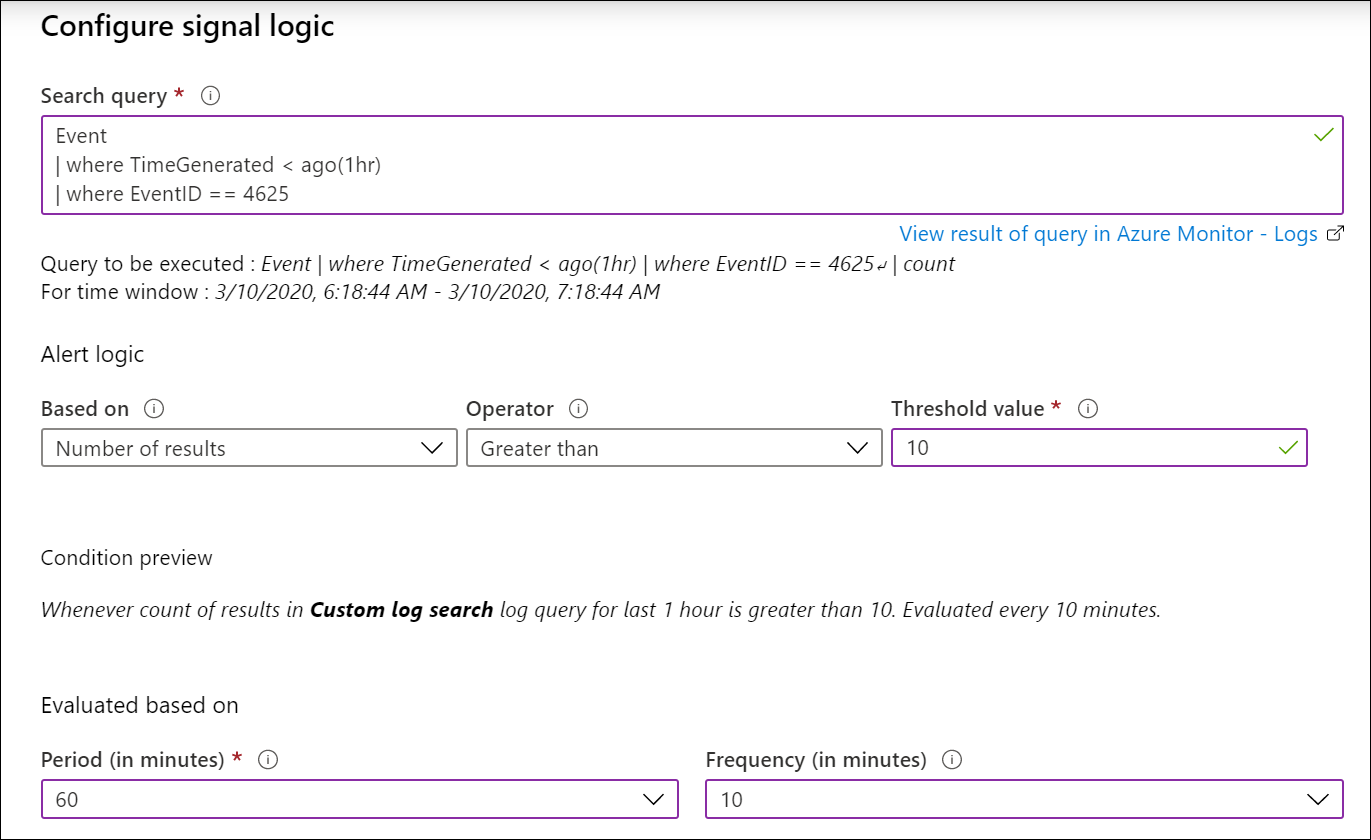
Например, чтобы создать оповещение, которое проверяет, отключены ли какие-либо виртуальные машины в определенной группе ресурсов, используйте приведенный ниже запрос. Он возвращает запись для каждого компьютера, который пропустил пакет пульса за последние десять минут. Используйте пороговое значение 1, чтобы оповещение срабатывало, если по крайней мере один компьютер имеет пропущенный пакет пульса.
Чтобы создать оповещение о слишком большом числе неудачных попыток входа на каких-либо виртуальных машинах Windows в подписке, используйте приведенный ниже запрос. Он возвращает запись для каждого события неудачного входа за последний час. В качестве порогового значения укажите допустимое число неудачных попыток входа.
Коротко о развертывании
Чтобы настроить Operations Manager с VMM, выполните указанные ниже действия.
-
Проверьте, выполнены ли все необходимые условия.
-
Установите консоль Operations Manager на сервере VMM, чтобы наблюдать за VMM с сервера.
-
Установите агенты Operations Manager на сервере управления VMM и на всех узлах под управлением VMM.
-
Найдите последний пакет управления.
-
Запустите мастер интеграции, чтобы обеспечить интеграцию VMM и Operations Manager. Мастер выполняет следующие действия:
- Импортирует пакеты управления VMM в Operations Manager.
- При необходимости включает оптимизацию производительности и ресурсов (PRO). Сведения PRO предоставляются диспетчером Operations Manager и могут использоваться VMM для оптимизации производительности. Можно сопоставить определенные предупреждения Operations Manager с действиями по устранению в VMM. Например, после сбоя оборудования виртуальные машины можно перенести на другой узел. Кроме того, если включена функция PRO, Operations Managers может обнаруживать проблемы с ресурсами или сбои оборудования в инфраструктуре виртуализации.
- При необходимости включает режим обслуживания. Служба VMM может переводить узлы в режим обслуживания. Когда узел находится в этом режиме, VMM использует динамическую миграцию для переноса виртуальных машин в другое место и не размещает новые виртуальные машины на этом узле. Если режим обслуживания включен для мониторинга Operations Manager, то при переводе узла в режим обслуживания в VMM диспетчер Operations Manager также переводит его в этот режим. В режиме обслуживания агент Operations Manager блокирует предупреждения, уведомления и изменения состояния, так что узел не отслеживается, пока выполняются операции по регулярному обслуживанию оборудования и программного обеспечения.
- Включает поддержку служб SQL Server Analysis Services (SSAS) и возможностей подготовки отчетов, предоставляемых SSAS.
System Center Operations Manager
System Center Operations Manager обеспечивает детальный мониторинг рабочих нагрузок на виртуальных машинах. Сравнение платформ мониторинга и стратегий реализации см. в статье Руководство по облачному мониторингу.
При наличии существующей среды Operations Manager, которую вы собираетесь использовать, ее можно интегрировать с Azure Monitor для предоставления дополнительных функциональных возможностей. Агент Log Analytics, используемый Azure Monitor, аналогичен тому, который используется для Operations Manager, поэтому отслеживаемые виртуальные машины будут отсылать данные в оба. Вам по-прежнему необходимо добавить агент в Application Insights и настроить рабочую область для получения дополнительных данных, как указано выше, но виртуальные машины могут продолжать запускать существующие пакеты управления в среде Operations Manager без изменения.
К функциям Azure Monitor, дополняющим существующие функции Operations Manager, относятся следующие.
- использование Log Analytics для интерактивного анализа данных журналов и данных по производительности;
- Используйте оповещения журнала для определения условий предупреждений на нескольких виртуальных машинах и использования долгосрочных тенденций, которые невозможно использовать при использовании предупреждений в Operations Manager.
Дополнительные сведения о подключении существующей группы управления Operations Manager к рабочей области Log Analytics см. в разделе Connect Operations Manager to Azure Monitor .
Сценарии использования vRealize Automation
Все в одном
Сейчас в мире существует много разных решений для виртуализации — VMware, Hyper-V, KVM. Нередко бизнес прибегает к использованию глобальных облаков типа Azure, AWS и Google Cloud. Управлять этим «зоопарком» с каждым годом все сложнее и сложнее. Кому-то эта проблема может показаться надуманной: почему бы, мол, не пользоваться в рамках компании только одним решением? Дело в том, что для каких-то задач действительно может хватить недорогого KVM. А более серьезным проектам понадобится весь функционал VMware. Выбрать что-то одно бывает невозможно как минимум по экономическим причинам.

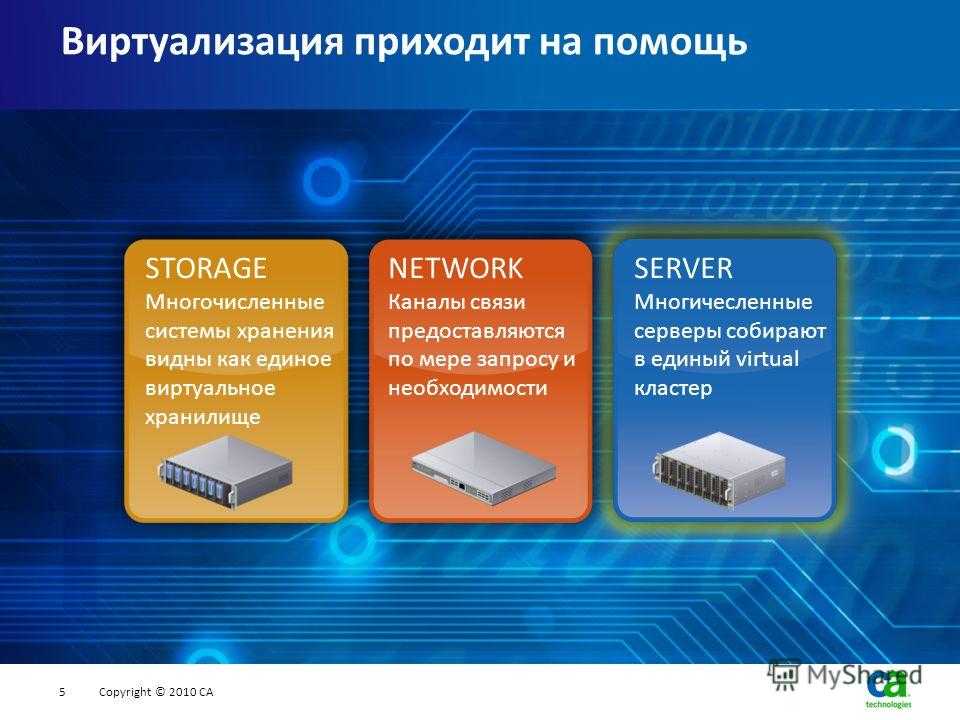
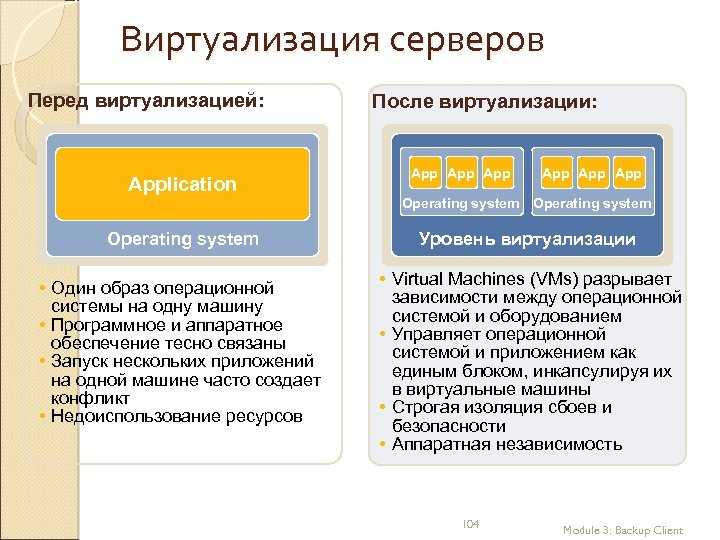



Вместе с увеличением количества используемых решений растет и объем задач. Например, у вас может появиться необходимость автоматизировать поставку ПО, управление конфигурацией и развертывание приложений. До появления vRealize Automation не было единого инструмента, который мог бы «впитать» в себя управление всеми этими платформами в режиме одного окна.
Каким бы стеком решений и площадок вы ни пользовались, есть возможность управлять ими через единый портал.
Каким бы стеком решений и площадок вы ни пользовались, есть возможность управлять ими через единый портал.
Автоматизируем типовые процессы
В рамках vRealize Automation возможен подобный сценарий:
-
Администратору приложения требуется развернуть дополнительную ВМ. С vRealize Automation ему не придется делать что-то вручную или договариваться с соответствующими специалистами. Достаточно будет нажать на условную кнопку «Хочу ВМ и побыстрее», и заявка отправится дальше.
-
Заявку получает системный администратор. Он изучает запрос, смотрит, есть ли достаточное количество свободных ресурсов, и аппрувит его.
-
Следующим в очереди стоит менеджер. Его задача — оценить, готова ли компания выделить средства для реализации проекта. Если все в порядке, он тоже нажимает Approve.
Мы сознательно выбрали максимально простой процесс и сократили количество его звеньев, чтобы выделить главную мысль:
Приведенную в виде примера задачу можно решить с помощью других систем — например, ServiceNow или Jira. Но vRealize Automation находится «ближе» к инфраструктуре и в нем возможны более сложные кейсы, чем развертывание виртуальной машины. Можно «в режиме одной кнопки» автоматически проверять наличие места в хранилище, при необходимости создавать новые луны. Технически даже возможно построить нестандартное решение и заскриптовать запросы к облачному провайдеру.
DevOps и CI/CD
Помимо сбора всех площадок и облаков в одном окне, vRealize Automation позволяет управлять всеми доступными средами в соответствиями с принципами DevOps. Разработчики сервисов могут разрабатывать и выпускать приложения без привязки к каждой конкретной платформе.
Как видно на схеме, над уровнем платформы находится Developer Ready Infrastructure, которая реализует функции интеграции и доставки, а также управления различными сценариями по развертыванию ИТ-систем вне зависимости от платформы, используемой на уровень ниже.
Consumption, или уровень потребителя услуг, представляет из себя среду взаимодействия пользователей/администраторов с конечными ИТ-системами:
-
Content Development позволяет выстроить взаимодействие с Dev-уровнем и управлять изменениями, версионностью и обращаться к репозиторию.
-
Service Catalog позволяет доставлять сервисы конечным потребителям: откатывать/публиковать новые и получать обратную связь.
-
Projects позволяет наладить внутренние ИТ-процессы принятия решений, когда каждое изменение или делегирование прав проходит процесс согласования, что актуально для компаний из энтерпрайза.
Создание оповещений
На основе метрик производительности можно создавать оповещения. Например, оповещения можно использовать для уведомления о том, что средняя загрузка ЦП превышает пороговое значение или свободное место на диске ниже определенного значения. Оповещения отображаются на портале Azure или могут быть отправлены по электронной почте. Вы также можете активировать модули Runbook службы автоматизации Azure или Azure Logic Apps в ответ на создаваемые оповещения.
В следующем примере создается предупреждение на основе среднего показателя использования ЦП.
-
На портале Azure щелкните Группы ресурсов, выберите myResourceGroupMonitor, а затем в списке ресурсов выберите myVM.
-
В колонке виртуальной машины щелкните Правила оповещения, а затем выберите Добавить оповещение метрики.
-
Укажите имя оповещения, например myAlertRule.
-
Для активации оповещения о превышении процента использования ЦП на 1.0 в течение пяти минут оставьте все настройки по умолчанию.
-
-
При необходимости установите флажок возле параметра Участники, читатели и владельцы электронной почты для отправки уведомлений по электронной почте. Действие по умолчанию — предоставлять уведомления на портале.
-
Нажмите кнопку ОК .




Анализ данных метрик
Вы можете анализировать метрики виртуальных машин с помощью обозревателя метрик. Для этого выберите пункт Метрики в меню виртуальной машины. Подробные сведения об использовании этого средства см. в статье Начало работы с обозревателем метрик Azure.
Для метрик виртуальных машин используются три пространства имен.
| Пространство имен | Описание | Требование |
|---|---|---|
| Компьютер виртуальной машины | Метрики компьютера автоматически собираются для всех виртуальных машин Azure. Подробный список метрик: . | Собираются автоматически без настройки. |
| Гость (классическая версия) | Ограниченный набор данных по производительности операционной системы на виртуальном компьютере и производительности приложений. Доступно в обозревателе метрик, но не в других компонентах Azure Monitor, таких как оповещения о метриках. | Расширение системы диагностики установлено. Данные считываются из службы хранилища Azure. |
| Операционная система на виртуальной машине | Данные по операционной системе на виртуальной машине и производительности приложений доступны для всех компонентов Azure Monitor с помощью метрик. | Для Windows расширение системы диагностики должно быть установлено с включенным приемником Azure Monitor. Для Linux должен быть установлен агент Telegraf. |





